


책 소개
2019년 대한민국학술원 우수학술도서 선정도서
요약
머신러닝을 금융에 적용하는 방법을 알려주며, 이론 연구를 넘어선 실전 경험을 바탕으로 어떠한 장점과 위험이 존재하는 것인지 빠짐없이 설명한다. 저자가 20년 간 금융에서 실제로 적용해 본 머신러닝 기법에 대해 각각의 장단점과 함께 개별 기법들을 상세히 설명한다. 또 금융에 맞는 데이터 구조, 모델링, 백테스팅, 유용한 금융적 특징, 고성능 컴퓨팅에 이르기까지 최고 전문가의 시각에서 전달해 주는 실전 지식을 빠짐없이 나열한다.
대부분의 금융 머신러닝 프로젝트가 실패하는 이유와 성공적인 금융 머신러닝 프로젝트를 위해서 어떠한 요소가 갖춰져야 하는지 설명하고 있다. 특히 대부분 프로젝트가 저지르는 백테스팅의 오류를 심도 있게 설명한다.
메타-전략 패러다임의 효용성과 중요성을 설명해 주며, 대부분 성공한 프로젝트가 활용하고 있는 메타-전략 패러다임을 예제와 함께 잘 설명한다. 이 책은 그 깊이로 인해 머신러닝과 금융에 대한 최소한의 지식을 갖춰야 이해할 수 있지만, 최소한의 지식이 바탕이 되고 나면 책에서 다루고 있는 깊이 있고 실용적인 내용으로부터 많은 도움을 받을 수 있다.
추천의 글
로페즈 박사는 현대 머신러닝을 금융 모델링에 응용하는 방법을 종합적으로 설명한 책을 저술했다. 이 책은 머신러닝의 최신 기술 발전을 저자의 학계나 산업계에서의 수십 년 간의 금융 경험으로부터 배운 중요한 삶의 교훈을 조화시킨 것이다. 나는 이 책을 머신러닝을 공부하는 전도유망한 학생들과 이들을 가르치고자 하는 전문가, 감독자들에게 추천한다.
- 피터 카(Peter Carr) 교수 뉴욕대학교 금융 리스크 공학부 학장
금융 문제에는 매우 확실한 머신러닝 해법이 필요하다. 로페즈 박사의 책은 표준 머신러닝 툴이 금융에 적용됐을 때 어떤 점에서 실패하는지를 알려주는 최초의 책이고, 자산 관리사들이 접하게 되는 고유한 문제를 해결할 수 있는 실질적인 해법을 알려주는 최초의 책이다. 금융의 미래를 이해하고자 하는 사람이라면 이 책을 읽어야 한다.
- 프랭크 파보지(Frank Fabozzi) 교수 EDHEC 경영 대학원, ‘포트폴리오 관리’ 편집인
마르코스는 금융에서 머신러닝을 적용하고자 하는 전문가들에게 귀중한 교훈과 기술을 한곳에 집대성했다. 마르코스의 영감을 주는 이 책은 호기심 많은 전문가가 어두운 복도로 잘못 접어들거나 제 발등을 찍게 되는 사태를 예방하는 데 도움을 준다.
- 로스 가론(Ross Garon) 입체파 시스템 전략, 이사, 포인트 72 자산 관리
정량 금융의 첫 번째 물결은 마코위츠 최적화가 이끌었고, 머신러닝의 두 번째 물결은 금융의 모든 측면에 영향을 미칠 것이다. 이 책은 이 물결에 대체돼 버리지 않고, 이 물결을 이끌어가고자 하는 사람들이 반드시 읽어야 할 책이다.
- 캠벨 하비(Campbell Harvey) 교수 듀크 대학, 전 미국 금융 학회 회장
작가의 학문적, 전문적, 일류적 신뢰가 책의 각 장마다 빛나고 있다. 새롭고 익숙하지 않은 과제에 대해 이토록 이론과 실제를 잘 설명한 사람은 찾아보기 힘들다. 급속히 주목 받는 분야에서 고전적인 필독서로 자리매김할 책이다.
- 카도 레보나토(Riccardo Rebonato) 교수 EDHEC 경영 대학원; 전 PIMCO 이자율, 환율 분석 글로벌 헤드
이 책의 대상 독자
특히 금융 관련 데이터에 연계된 문제들을 해결하기 위해 설계된 고급 머신러닝 기법을 다루고 있다. ‘고급’이라는 의미는 이해하기가 극도로 힘들다거나 딥러닝이나 순환신경망 또는 합성곱망 등 최근에 되살아나고 있는 기법들을 설명한다는 의미는 아니다. 그보다 이 책은 금융 문제에 머신러닝 알고리즘을 적용한 경험이 있는 상급 연구원들이 중요하게 생각하는 여러 의문에 해답을 주고자 쓰여졌다. 만약 머신러닝이 처음이고, 복잡한 알고리즘에 대한 경험이 없다면 이 책은 (아직은) 맞지 않을 것이다. 이 책에서 다루고 있는 문제에 대해 현업에서의 경험이 없다면 이 책을 이용해 문제를 해결하기가 쉽지 않을 것이다. 이 책을 읽기 전에 머신러닝에 관한 여러 훌륭한 책을 읽길 권한다.
이 책의 핵심 독자들은 머신러닝 경험이 풍부한 전문 투자가들이다. 저자의 목표는 여러분이 이 책에서 배운 것을 통해 수익을 증대하기를 바라는 것이고, 금융을 현대화하는 데 일조하고 투자가들에게 실질적인 가치를 전달해 주기를 바라는 것이다.
이 책은 금융 이외의 여러 분야에 머신러닝 알고리즘을 성공적으로 구현한 경험이 있는 데이터 과학자들에게도 적합하다. 만약 여러분이 구글에서 일하면서 얼굴 인식 분야를 성공적으로 구현한 적이 있지만, 금융 쪽에 제대로 적용해 본 적이 없다면 이 책이 많은 도움이 될 것이다. 가끔 특정 구조(예를 들어, 메타 레이블링, 삼중 배리어 기법, 프랙디프)의 금융 논리에 대해 잘 이해되지 않을 때도 있을 수 있지만, 끈기를 갖길 바란다. 투자 포트폴리오를 일정 수준 이상 운용하다 보면 게임의 법칙이 점점 뚜렷하게 보이고, 1장에 설명된 내용들이 이해가 될 것이다.
이 책의 구성
이 책은 서로 얽혀 있는 주제들을 각각 구분해 정돈된 형태로 설명한다. 각 장은 그 이전 장을 읽었다고 가정하고 설명한다. 1부는 금융 데이터를 머신러닝 알고리즘에서 잘 적용할 수 있도록 데이터를 구조화하는 방법을 알아보고, 2부에서는 해당 데이터에 기반해 머신러닝 알고리즘을 활용해 리서치하는 방법을 알아본다. 여기서 중요한 것은 실질적인 발견은 연구나 과학적 프로세스를 통해 이뤄지며, 이는 우연히 어떤 (잘못될 가능성이 많은) 결과가 나타날 때까지 의미 없이 반복하는 연구 기법과는 구분된다. 3부에서는 연구에 대한 백테스트 방법을 설명하고, 결과가 잘못될 확률을 평가해 본다.
1~3부를 통해 데이터 분석으로부터 모델을 연구하고, 결과를 평가하는 전체 프로세스를 개괄할 수 있다. 이러한 지식을 바탕으로 4부에서는 데이터로 되돌아가 의미 있는 특성을 추출하는 혁신적인 방법을 설명한다. 이러한 작업들은 대부분 상당한 양의 자원을 소모하는데 5부에서는 유용한 HPC 비법을 알아본다.
목차
목차
- 1장. 독립된 주제로서의 금융 머신러닝
- 1.1 동기
- 1.2 금융 머신러닝 프로젝트가 실패하는 주요 원인
- 1.2.1 시지프스 패러다임
- 1.2.2 메타 전략 패러다임
- 1.3 책의 구조
- 1.3.1 생산 체인 형태로 구조 짜기
- 1.3.3 흔한 함정에 따른 구성
- 1.4 대상 독자들
- 1.5 필요 지식
- 1.6 자주 받는 질문들
- 1.7 감사의 글
- 연습 문제
- 참고 자료
- 참고 문헌
- 1부. 데이터 분석
- 2장. 금융 데이터 구조
- 2.1 동기
- 2.2 금융 데이터의 근본적 형태
- 2.2.1 기본 데이터
- 2.2.2 시장 데이터
- 2.2.3 분석
- 2.2.4 대체 데이터
- 2.3 바
- 2.3.1 표준 바
- 2.4 복수 상품 계열 다루기
- 2.4.1 ETF 트릭
- 2.4.2 PCA 가중값
- 2.4.3 단일 선물 롤 오버
- 2.5 특성 샘플 추출
- 2.5.1 축소를 위한 표본 추출
- 2.5.2 이벤트 기반의 표본 추출
- 연습 문제
- 참고 자료
- 3장. 레이블링
- 3.1 동기
- 3.2 고정 기간 기법
- 3.3 동적 임계값 계산
- 3.4 삼중 배리어 기법
- 3.5 방향과 크기 파악
- 3.6 메타 레이블링
- 3.7 메타 레이블링을 이용하는 방법
- 3.8 퀀터멘털 방법
- 3.9 불필요한 레이블 제거
- 연습 문제
- 참고 문헌
- 4장. 표본 가중값
- 4.1 동기
- 4.2 중첩된 결과
- 4.3 공존 레이블의 개수
- 4.4 레이블의 평균 고유도
- 4.5 배깅 분류기와 고유도
- 4.5.1 순차적 부트스트랩
- 4.5.2 순차적 부트스트랩의 구현
- 4.5.3 수치적 예제
- 4.5.4 몬테카를로 실험
- 4.6 수익률 기여도
- 4.7 시간 감쇠
- 4.8 클래스 가중값
- 연습 문제
- 참고 자료
- 참고 문헌
- 5장. 분수 미분의 특징
- 5.1 동기
- 5.2 정상성 대 기억 딜레마
- 5.3 문헌 리뷰
- 5.4 방법
- 5.4.1 장기 기억
- 5.4.2 반복 추정
- 5.4.3 수렴
- 5.5 구현
- 5.5.1 확장 윈도우
- 5.5.2 고정 너비 윈도우 분수 미분
- 5.6 최대 기억 유지 정상성
- 5.7 결론
- 연습 문제
- 참고 자료
- 참고 문헌
- 2부. 모델링
- 6장. 앙상블 기법
- 6.1 동기
- 6.2 오류의 세 가지 원인
- 6.3 배깅
- 6.3.1 분산 축소
- 6.3.2 개선된 정확도
- 6.3.3 관측 중복
- 6.4 랜덤 포레스트
- 6.5 부스팅
- 6.6 금융에 있어서의 배깅 대 부스팅
- 6.7 배깅의 확장성
- 연습 문제
- 참고 자료
- 참고 문헌
- 7장. 금융에서의 교차 검증
- 7.1 동기
- 7.2 교차 검증의 목표
- 7.3 금융에서 K겹 교차 검증이 실패하는 이유
- 7.4 해법: 제거 K겹 교차 검증
- 7.4.1 훈련셋에서의 제거
- 7.4.2 엠바고
- 7.4.3 제거된 K겹 클래스
- 7.5 sklearn의 교차 검증 버그
- 연습 문제
- 참고 문헌
- 8장. 특성 중요도
- 8.1 동기
- 8.2 특성 중요도의 중요성
- 8.3 대체 효과가 있는 특성 중요도
- 8.3.1 평균 감소 불순도
- 8.3.2 평균 감소 정확도
- 8.4 대체 효과가 없는 특성 중요도
- 8.4.1 단일 특성 중요도
- 8.4.2 직교 특성
- 8.5 병렬 대 스태킹 특성 중요도
- 8.6 합성 데이터를 사용한 실험
- 연습 문제
- 참고 자료
- 9장. 교차 검증을 통한 하이퍼 파라미터 튜닝
- 9.1 동기
- 9.2 그리드 검색 교차 검증
- 9.3 랜덤 검색 교차 검증
- 9.3.1 로그 균등 분포
- 9.4 점수 함수 및 하이퍼 파라미터 튜닝
- 연습 문제
- 참고 자료
- 참고 문헌
- 3부. 백테스트
- 10장. 베팅 크기
- 10.1 동기
- 10.2 전략 독립 베팅 크기 방식
- 10.3 예측된 확률로부터 베팅 크기 조절
- 10.4 실행 중인 베팅의 평균화
- 10.5 베팅 크기 이산화
- 10.6 동적 베팅 크기와 지정가
- 연습 문제
- 참고 자료
- 참고 문헌
- 11장. 백테스트의 위험
- 11.1 동기
- 11.2 미션 임파서블: 결함 없는 백테스트
- 11.3 비록 백테스트 결과가 나무랄 데 없어도 아마 잘못됐을 것이다
- 11.4 백테스트는 연구 도구가 아니다
- 11.5 몇 가지 일반적인 추천
- 11.6 전략 선택
- 연습 문제
- 참고 자료
- 참고 문헌
- 12장. 교차 검증을 통한 백테스트
- 12.1 동기
- 12.2 전방 진행 기법
- 12.2.1 전방 진행 방법의 위험
- 12.3 교차 검증 기법
- 12.4 조합적 제거 교차 검증 기법
- 12.4.1 조합적 분할
- 12.4.2 조합적 제거 교차 검증 백테스트 알고리즘
- 12.4.3 몇 가지 예제
- 12.5 조합적 제거 교차 검증이 백테스트 과적합을 해결하는 법
- 연습 문제
- 참고 자료
- 13장. 합성 데이터에 대한 백테스트
- 13.1 동기
- 13.2 거래 규칙
- 13.3 문제
- 13.4 프레임워크
- 13.5 최적 거래 규칙의 수치적 결정
- 13.5.1 알고리즘
- 13.5.2 구현
- 13.6 실험 결과
- 13.6.1 제로 장기 균형의 경우
- 13.6.2 양의 장기 균형의 경우
- 13.6.3 음의 장기 균형의 경우
- 13.7 결론
- 연습 문제
- 참고 자료
- 14장. 백테스트 통계량
- 14.1 동기
- 14.2 백테스트 통계량의 종류
- 14.3 일반적인 특성
- 14.4 성과
- 14.4.1 수익률의 시간 가중 비율
- 14.5 런
- 14.5.1 수익률 집중
- 14.5.2 손실폭과 수면하 시간
- 14.5.3 성과 평가를 위한 런 통계량
- 14.6 거래 구축 비용
- 14.7 효율성
- 14.7.1 샤프 비율
- 14.7.2 확률적 샤프 비율
- 14.7.3 축소 샤프 비율
- 14.7.4 효율성 통계량
- 14.8 분류 점수
- 14.9 기여도 분석
- 연습 문제
- 참고 자료
- 참고 문헌
- 15장. 전략 리스크 이해
- 15.1 동기
- 15.2 대칭 투자 이익
- 15.3 비대칭 투자 이익
- 15.4 전략 실패의 확률
- 15.4.1 알고리즘
- 15.4.2 구현
- 연습 문제
- 참고 자료
- 16장. 머신러닝 자산 배분
- 16.1 동기
- 16.2 볼록 포트폴리오 최적화 문제
- 16.3 마코위츠의 저주
- 16.4 기하적 관계에서 계층적 관계까지
- 16.4.1 트리 군집화
- 16.4.2 준대각화
- 16.4.3 재귀적 이분법
- 16.5 수치 예제
- 16.6 샘플 외 몬테카를로 시뮬레이션
- 16.7 향후 연구 과제
- 16.8 결론
- 부록
- 연습 문제
- 참고 자료
- 4부. 유용한 금융의 특징
- 17장. 구조적 변화
- 17.1 동기
- 17.2 구조적 변화 테스트 유형
- 17.3 CUSUM 테스트
- 17.3.1 재귀적 잔차에 브라운 - 더빈 - 에반스 CUSUM 테스트
- 17.3.2 수준에 대한 추 - 스틴치콤 - 화이트 CUSUM 테스트
- 17.4 폭발성 테스트
- 17.4.1 초 - 유형의 딕키 - 풀러 테스트
- 17.4.2 상한 증강 딕키 - 풀러
- 17.4.3 서브 또는 슈퍼 - 마팅게일 테스트
- 연습 문제
- 참고 자료
- 18장. 엔트로피 특성들
- 18.1 동기
- 18.2 샤논의 엔트로피
- 18.3 플러그인(또는 최대 우도) 추정량
- 18.4 렘펠 - 지브 추정기
- 18.5 인코딩 체계
- 18.5.1 이진 인코딩
- 18.5.2 분위수 인코딩
- 18.5.3 시그마 인코딩
- 18.6 가우시안 프로세스의 엔트로피
- 18.7 엔트로피와 일반화된 평균
- 18.8 엔트로피의 몇 가지 금융 응용
- 18.8.1 시장 효율성
- 18.8.2 최대 엔트로피 생성
- 18.8.3 포트폴리오 집중화
- 18.8.4 시장 미시 구조
- 연습 문제
- 참고 자료
- 참고 문헌
- 19장. 미시 구조적 특성
- 19.1 동기
- 19.2 문헌 리뷰
- 19.3 1세대: 가격 시퀀스
- 19.3.1 틱 규칙
- 19.3.2 롤 모델
- 19.3.3 고가 - 저가 변동성 추정량
- 19.3.4 코윈과 슐츠
- 19.4 2세대: 전략적 거래 모델
- 19.4.1 카일의 람다
- 19.4.2 아미후드의 람다
- 19.4.3 하스브룩의 람다
- 19.5 제3세대: 순차적 거래 모델
- 19.5.1 정보 기반 거래의 확률
- 19.5.2 정보 기반 거래의 거래량 동기화 확률
- 19.6 미시 구조적 데이터셋으로부터의 추가 특성
- 19.6.1 주문 크기의 분포
- 19.6.2 취소율, 지정가 주문, 시장가 주문
- 19.6.3 시간 가중 평균 가격 실행 알고리즘
- 19.6.4 옵션 시장
- 19.6.5 부호가 있는 주문 흐름의 계열 상관관계
- 19.7 미시 구조적 정보란 무엇인가?
- 연습 문제
- 참고 자료
- 5부. 고성능 컴퓨팅 비법
- 20장. 다중 처리와 벡터화
- 20.1 동기
- 20.2 벡터화 예제
- 20.3 단일 스레드 대 다중 스레딩 대 다중 처리
- 20.4 원자와 분자
- 20.4.1 선형 분할
- 20.4.2 이중 루프 분할
- 20.5 다중 처리 엔진
- 20.5.1 작업 준비
- 20.5.2 비동기 호출
- 20.5.3 콜백 언래핑
- 20.5.4 피클/언피클 객체
- 20.5.5 출력 축소
- 20.6 다중 처리 예제
- 연습 문제
- 참고 자료
- 참고 문헌
- 21장. 무차별 대입과 양자 컴퓨터
- 21.1 동기
- 21.2 조합적 최적화
- 21.3 목적 함수
- 21.4 문제
- 21.5 정수 최적화 방법
- 21.5.1 비둘기집 분할
- 21.5.2 가능한 정적 해
- 21.5.3 궤적 평가
- 21.6 수치 예제
- 21.6.1 랜덤 행렬
- 21.6.2 정태적 해
- 21.6.3 동태적 해
- 연습 문제
- 참고 자료
- 22장. 고성능 계산 지능과 예측 기술
- 22.1 동기
- 22.2 2010년 플래시 크래시에 대한 감독 당국의 반응
- 22.3 배경
- 22.4 HPC 하드웨어
- 22.5 HPC 소프트웨어
- 22.5.1 MPI
- 22.5.2 계층적 데이터 형식 5
- 22.5.3 제자리 처리
- 22.5.4 수렴
- 22.6 실제 사례
- 22.6.1 초신성 사냥
- 22.6.2 융합 플라스마의 덩어리
- 22.6.3 일간 전기 사용 최대값
- 22.6.4 2010년의 플래시 크래시
- 22.6.5 정보 기반 거래 거래량 동기화 확률의 추정
- 22.6.6 비균등 고속 푸리에 변환으로 고빈도 이벤트 발견
- 22.7 요약 및 참여 요청
- 22.8 감사의 글
- 참고 자료
도서 오류 신고
정오표
정오표
[p.68 : 마지막 행 수식]
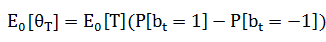
[p.469 : 그림 22-1]
QDR infiband
->
QDR infiniband
[p.469 : 그림 22-1]
1TD 메모리당 노드
->
노드당 1TB 메모리
[p.470]
GUP
->
GPU