


책 소개
현대 컴퓨터의 실리콘 심장! 그 내부를 들여다보자.
최근 아마존 컴퓨터 인터넷 부문 탑 셀러에 랭크된 이 책은 매우 훌륭한 컴퓨터 아키텍처 책으로 명료한 설명과 논리적인 구성에 최신 내용을 담고 있다. 마이크로프로세서 분야에서 몇 년의 실무 경험이 있는 사람도 새로 배우는 내용이 있을 정도로 교육적이며 쉽게 기술되어 있어 이 분야에 관한 지식이 필요한 학생이나 직장인에게 필수적인 책이다. 특히 컬러로 된 그림들과 저자의 친절한 설명은 이 책을 읽는 재미를 배가해준다. 굳이 수 년간 대학에서 이 분야를 전공하지 않고서도 마이크로프로세서 설계에 대해 알고 싶은 사람들에게 강력히 추천할만하다.
[ 이 책에서 다루는 내용 ]
♦ 컴퓨터와 마이크로프로세서의 구성 요소
♦ 프로그래밍의 기초(산술 명령어, 메모리 명령어, 제어 명령어, 데이터 타입)
♦ 중상급 마이크로프로세서 개념(분기 예측 및 예측 수행)
♦ 중상급 컴퓨터 개념(ISA, CISC 및 RISC, 메모리 계층, 명령어 인코딩 및 디코딩)
♦ 64비트 컴퓨터와 32비트 컴퓨터 비교
♦ 캐쉬와 컴퓨터 성능
[ 이 책에서 다루는 프로세서 ]
♦ 인텔 오리지널 펜티엄 및 펜티엄 프로
♦ 인텔 펜티엄 II, 펜티엄 III
♦ 인텔 펜티엄 4
♦ 인텔 펜티엄 M, 코어 듀오, 코어 2 듀오
♦ 파워PC 600 시리즈 및 700 시리즈, 7400
♦ 모토로라 G4e 및 G5(파워4)
[ 추천의 글 ]
프로세서 구조를 다루는 많은 책들이 있어 왔지만, 근래에 보기 드문 좋은 책이 나왔다. 이 책은 자세하고 멋진 일러스트레이션과 함께 프로세서가 동작하는 구조를 아주 명쾌하게 설명하고 있다. 저자는 프로세서의 기본 구성과 동작원리를 쉽게 설명하기 위해 DLW-1라는 단순한 가상 프로세서를 예로 들고 있다. 이런 단순화한 접근 방법은 처음으로 프로세서 구조를 공부하고자 하는 학생이나 엔지니어, 심지어 비전공자까지도 프로세서의 구조를 쉽게 이해할 수 있게 도와준다.
지금은 프로세서의 구조와 파이프라인, 캐쉬의 개념을 제대로 모르고서는 고급 소프트웨어 개발자라고 말하기 어려운 시대다. 일반 소비자들이 제품에 바라는 경험과 기대치는 날로 커지고 있다. PC에서 보던 동영상을 그대로 PMP에서 보기를 원하고 GUI도 좀더 화려해지기를 바란다. 심지어 PC에서 동작하는 플래시 컨텐츠를 휴대용 기기에서도 재생하기를 원하고 있다. 이렇듯 소비자의 기대치는 높아지고 있는 반면, 임베디드 제품에서 사용하는 프로세서의 능력에는 한계가 있다. 원가에 민감한 임베디드 제품을 개발할 때 프로세서가 제공하는 정해진 능력을 최대한 활용할 수 있는 소프트웨어를 작성하기 위해서는 프로세서를 숙지하고 세세히 이해하고 있어야 한다.
물론 이 책은 기본적으로 프로세서를 설계할 전공자들이 봐야 할 책이다. 하지만 그저 책을 훑어 읽어 내려가는 것만으로 프로세서 구조와 동작을 쉽게 이해할 수 있기 때문에 프로세서 설계와 관계 없는 소프트웨어 개발자도 이 책을 보면 많은 도움을 받을 수 있을 것이다. 특히 임베디드 소프트웨어 개발자라면 반드시 꼭 읽어야 한다. 이런 점에서 이 책은 컴퓨터공학을 전공하지 않은 소프트웨어 개발자에게도 많은 도움을 줄 것으로 확신한다.
[ 이 책의 구성 ]
『인사이드 머신: 그림으로 배우는 컴퓨터 아키텍처와 마이크로프로세서』는 컴퓨터 아키텍처 부분의 명저인 (하지만 읽기는 쉽지 않은) 헤네시와 패터슨의 책과, 컴퓨터 아키텍처를 본격적으로 알고 싶어하는 사람들이 보기에는 너무 쉬운 책들 사이의 간극을 메우기 위해 쓴 책이다. 컴퓨터를 좀 사용해본 독자들은(스크립트 언어라도, 일단 프로그램을 작성해본 경험이 있는 사람이라면) 이 책을 통해 오늘날 컴퓨터 프로세서가 어떤 식으로 동작하는지 깊이 있는 지식을 얻을 수 있을 것이다. 이 책을 읽고 난 독자는 혼자 힘으로도 앞서 소개한 헤네시와 패터슨의 책을 더욱 쉽게 읽을 수 있을 것이고, 대학교 정규 수업을 받으며 좀더 체계적인 지식을 쌓을 수 있게 될 것이다.
이 책은 여러 프로세서에서 같은 문제를 어떤 방식으로 해결하는지 비교해서 설명한다. 각 장은 앞 장의 내용을 알고 있다고 가정하고 쓰여 있기 때문에 초중급 독자는 가급적 앞에서부터 순서대로 읽기를 권한다. 한편 컴퓨터 아키텍처에 이미 상당한 지식이 있는 독자라면 원하는 내용만 골라 읽어도 괜찮다. 이 책은 각 장의 내용을 상세히 나눠놓아서, 원할 경우 특정 프로세서의 기능을 쉽게 참고할 수 있게 했다.
이 책의 1장에서 4장까지는 이후 실제 프로세서들에 대한 설명을 이해하기 위한 기본 개념을 설명했다. 여기에서는 DLW라는 매우 단순한 프로세서를 예로 들어 명령어와 데이터의 개념, 어셈블리 프로그래밍, 수퍼스칼라, 파이프라인, 프로그래밍 모델, 기계어 등에 대해 설명한다.
중반부는 인텔의 펜티엄 계열 프로세서와 IBM, 모토로라의 파워PC 계열 프로세서에 대해 설명한다. 이를 통해 독자는 각 프로세서 계열에서 마이크로아키텍처와 ISA가 어떤 식으로 진화해 왔는지 알 수 있다. 이 과정에서 실제 프로세서를 예로 들어 예측 수행, 벡터 처리, 명령어 변환 등의 고급 기법들에 대해 살펴볼 것이다. 중반부 설명에서 필자가 사용한 방법은 ‘비교 분석법’이다. 각 프로세서의 참신한 기능을 설명할 때면, 비슷한 문제를 해결하기 위해 경쟁 제품과 이전 제품들은 어떤 기법을 사용했었는지 비교해서 설명한다. 특히 7장과 8장에서는 각기 다른 접근 기법을 사용한 인텔의 펜티엄4와 모토로라의 MPC 7450(G4e)을 상세히 비교 분석했다.
9장에서는 64비트 컴퓨터에 대한 개념을 설명하고 널리 사용되는 x86 ISA에 대한 64비트 확장을 알아본다. 이어 10장에서는 최초로 출시된 64비트 프로세서인 IBM 파워PC 970에 대해 설명한다. 파워PC 970은 이 책에서 다루는 마지막 파워PC 계열의 프로세서로, 이에 대한 설명은 IBM의 파워4 메인프레임 프로세서에도 거의 동일하게 적용된다. 11장은 오늘날 대부분 컴퓨터에서 사용되는 메모리 계층의 구조와 기능에 대해 설명한다.
마지막 장인 12장은 인텔의 최신 프로세서인 펜티엄 M, 코어 듀오, 코어 2 듀오에 대해 알아본다. 12장에서는 책으로 출판된 자료나 인터넷상에서 공개된 자료를 통틀어 이들 프로세서에 대한 가장 상세한 부분까지 설명하고 있다. 심지어 일부 정보는 이 책을 통해 처음으로 공개된다.
최근 아마존 컴퓨터 인터넷 부문 탑 셀러에 랭크된 이 책은 매우 훌륭한 컴퓨터 아키텍처 책으로 명료한 설명과 논리적인 구성에 최신 내용을 담고 있다. 마이크로프로세서 분야에서 몇 년의 실무 경험이 있는 사람도 새로 배우는 내용이 있을 정도로 교육적이며 쉽게 기술되어 있어 이 분야에 관한 지식이 필요한 학생이나 직장인에게 필수적인 책이다. 특히 컬러로 된 그림들과 저자의 친절한 설명은 이 책을 읽는 재미를 배가해준다. 굳이 수 년간 대학에서 이 분야를 전공하지 않고서도 마이크로프로세서 설계에 대해 알고 싶은 사람들에게 강력히 추천할만하다.
[ 이 책에서 다루는 내용 ]
♦ 컴퓨터와 마이크로프로세서의 구성 요소
♦ 프로그래밍의 기초(산술 명령어, 메모리 명령어, 제어 명령어, 데이터 타입)
♦ 중상급 마이크로프로세서 개념(분기 예측 및 예측 수행)
♦ 중상급 컴퓨터 개념(ISA, CISC 및 RISC, 메모리 계층, 명령어 인코딩 및 디코딩)
♦ 64비트 컴퓨터와 32비트 컴퓨터 비교
♦ 캐쉬와 컴퓨터 성능
[ 이 책에서 다루는 프로세서 ]
♦ 인텔 오리지널 펜티엄 및 펜티엄 프로
♦ 인텔 펜티엄 II, 펜티엄 III
♦ 인텔 펜티엄 4
♦ 인텔 펜티엄 M, 코어 듀오, 코어 2 듀오
♦ 파워PC 600 시리즈 및 700 시리즈, 7400
♦ 모토로라 G4e 및 G5(파워4)
[ 추천의 글 ]
프로세서 구조를 다루는 많은 책들이 있어 왔지만, 근래에 보기 드문 좋은 책이 나왔다. 이 책은 자세하고 멋진 일러스트레이션과 함께 프로세서가 동작하는 구조를 아주 명쾌하게 설명하고 있다. 저자는 프로세서의 기본 구성과 동작원리를 쉽게 설명하기 위해 DLW-1라는 단순한 가상 프로세서를 예로 들고 있다. 이런 단순화한 접근 방법은 처음으로 프로세서 구조를 공부하고자 하는 학생이나 엔지니어, 심지어 비전공자까지도 프로세서의 구조를 쉽게 이해할 수 있게 도와준다.
지금은 프로세서의 구조와 파이프라인, 캐쉬의 개념을 제대로 모르고서는 고급 소프트웨어 개발자라고 말하기 어려운 시대다. 일반 소비자들이 제품에 바라는 경험과 기대치는 날로 커지고 있다. PC에서 보던 동영상을 그대로 PMP에서 보기를 원하고 GUI도 좀더 화려해지기를 바란다. 심지어 PC에서 동작하는 플래시 컨텐츠를 휴대용 기기에서도 재생하기를 원하고 있다. 이렇듯 소비자의 기대치는 높아지고 있는 반면, 임베디드 제품에서 사용하는 프로세서의 능력에는 한계가 있다. 원가에 민감한 임베디드 제품을 개발할 때 프로세서가 제공하는 정해진 능력을 최대한 활용할 수 있는 소프트웨어를 작성하기 위해서는 프로세서를 숙지하고 세세히 이해하고 있어야 한다.
물론 이 책은 기본적으로 프로세서를 설계할 전공자들이 봐야 할 책이다. 하지만 그저 책을 훑어 읽어 내려가는 것만으로 프로세서 구조와 동작을 쉽게 이해할 수 있기 때문에 프로세서 설계와 관계 없는 소프트웨어 개발자도 이 책을 보면 많은 도움을 받을 수 있을 것이다. 특히 임베디드 소프트웨어 개발자라면 반드시 꼭 읽어야 한다. 이런 점에서 이 책은 컴퓨터공학을 전공하지 않은 소프트웨어 개발자에게도 많은 도움을 줄 것으로 확신한다.
성원호
디오이즈(www.dioiz.com) 대표
에이콘 임베디드 시스템 프로그래밍 시리즈 에디터
디오이즈(www.dioiz.com) 대표
에이콘 임베디드 시스템 프로그래밍 시리즈 에디터
[ 이 책의 구성 ]
『인사이드 머신: 그림으로 배우는 컴퓨터 아키텍처와 마이크로프로세서』는 컴퓨터 아키텍처 부분의 명저인 (하지만 읽기는 쉽지 않은) 헤네시와 패터슨의 책과, 컴퓨터 아키텍처를 본격적으로 알고 싶어하는 사람들이 보기에는 너무 쉬운 책들 사이의 간극을 메우기 위해 쓴 책이다. 컴퓨터를 좀 사용해본 독자들은(스크립트 언어라도, 일단 프로그램을 작성해본 경험이 있는 사람이라면) 이 책을 통해 오늘날 컴퓨터 프로세서가 어떤 식으로 동작하는지 깊이 있는 지식을 얻을 수 있을 것이다. 이 책을 읽고 난 독자는 혼자 힘으로도 앞서 소개한 헤네시와 패터슨의 책을 더욱 쉽게 읽을 수 있을 것이고, 대학교 정규 수업을 받으며 좀더 체계적인 지식을 쌓을 수 있게 될 것이다.
이 책은 여러 프로세서에서 같은 문제를 어떤 방식으로 해결하는지 비교해서 설명한다. 각 장은 앞 장의 내용을 알고 있다고 가정하고 쓰여 있기 때문에 초중급 독자는 가급적 앞에서부터 순서대로 읽기를 권한다. 한편 컴퓨터 아키텍처에 이미 상당한 지식이 있는 독자라면 원하는 내용만 골라 읽어도 괜찮다. 이 책은 각 장의 내용을 상세히 나눠놓아서, 원할 경우 특정 프로세서의 기능을 쉽게 참고할 수 있게 했다.
이 책의 1장에서 4장까지는 이후 실제 프로세서들에 대한 설명을 이해하기 위한 기본 개념을 설명했다. 여기에서는 DLW라는 매우 단순한 프로세서를 예로 들어 명령어와 데이터의 개념, 어셈블리 프로그래밍, 수퍼스칼라, 파이프라인, 프로그래밍 모델, 기계어 등에 대해 설명한다.
중반부는 인텔의 펜티엄 계열 프로세서와 IBM, 모토로라의 파워PC 계열 프로세서에 대해 설명한다. 이를 통해 독자는 각 프로세서 계열에서 마이크로아키텍처와 ISA가 어떤 식으로 진화해 왔는지 알 수 있다. 이 과정에서 실제 프로세서를 예로 들어 예측 수행, 벡터 처리, 명령어 변환 등의 고급 기법들에 대해 살펴볼 것이다. 중반부 설명에서 필자가 사용한 방법은 ‘비교 분석법’이다. 각 프로세서의 참신한 기능을 설명할 때면, 비슷한 문제를 해결하기 위해 경쟁 제품과 이전 제품들은 어떤 기법을 사용했었는지 비교해서 설명한다. 특히 7장과 8장에서는 각기 다른 접근 기법을 사용한 인텔의 펜티엄4와 모토로라의 MPC 7450(G4e)을 상세히 비교 분석했다.
9장에서는 64비트 컴퓨터에 대한 개념을 설명하고 널리 사용되는 x86 ISA에 대한 64비트 확장을 알아본다. 이어 10장에서는 최초로 출시된 64비트 프로세서인 IBM 파워PC 970에 대해 설명한다. 파워PC 970은 이 책에서 다루는 마지막 파워PC 계열의 프로세서로, 이에 대한 설명은 IBM의 파워4 메인프레임 프로세서에도 거의 동일하게 적용된다. 11장은 오늘날 대부분 컴퓨터에서 사용되는 메모리 계층의 구조와 기능에 대해 설명한다.
마지막 장인 12장은 인텔의 최신 프로세서인 펜티엄 M, 코어 듀오, 코어 2 듀오에 대해 알아본다. 12장에서는 책으로 출판된 자료나 인터넷상에서 공개된 자료를 통틀어 이들 프로세서에 대한 가장 상세한 부분까지 설명하고 있다. 심지어 일부 정보는 이 책을 통해 처음으로 공개된다.
목차
목차
- 1장 컴퓨터 동작의 기본 개념 1
- 계산기 모델 2
- 문서관리원 모델 3
- 스토어 프로그램 컴퓨터 4
- 문서관리원 모델 다시 보기 6
- 레지스터 파일 7
- RAM: 레지스터만으로는 부족할 때 8
- 문서관리원 모델의 확장 9
- 예: 두 수 더하기 10
- 코드 스트림 살펴 보기:프로그램 10
- 명령어의 종류 11
- DLW-1 기본 아키텍처 및 산술 명령어 포맷 12
- 메모리 접근 자세히 보기: 레지스터와 직접값 비교 14
- 직접값 14
- 상대 레지스터 주소 지정 16
- 2장 프로그램 실행의 원리 19
- 연산코드와 기계어 19
- DLW-1의 기계어 19
- 산술 명령어의 바이너리 인코딩 21
- 메모리 접근 명령어의 바이너리 인코딩 23
- 예제 프로그램을 기계어로 바꾸기 25
- 프로그래밍 모델과 ISA 26
- 프로그래밍 모델 26
- 명령어 레지스터와 프로그램 카운터 26
- 명령어 페치: 명령어 레지스터 채우기 28
- 간단한 프로그램 실행 예제: 페치-실행 루프 28
- 클럭 29
- 분기 명령어 30
- 무조건 분기 30
- 조건 분기 30
- 부록: 부팅 34
- 연산코드와 기계어 19
- 3장 파이프라인 35
- 명령어의 생명 주기 36
- 명령어의 기본 흐름 38
- 파이프라인 40
- 프로세서에의 적용 43
- 단일 사이클 프로세서 43
- 파이프라인 프로세서 45
- 파이프라인으로 인한 속도 향상 48
- 프로그램 수행시간과 완료율 51
- 프로그램 수행시간과 완료율의 관계 52
- 명령어 산출량과 파이프라인 멈춤 53
- 명령어 지연시간과 파이프라인 멈춤 57
- 파이프라인의 한계 58
- 4장 슈퍼스칼라 수행 61
- 수퍼스칼라 수행과 IPC 64
- 수퍼스칼라의 수행 유닛 65
- 기본적인 숫자 포맷과 산술 연산 66
- 산술 논리 유닛 67
- 메모리 접근 유닛 69
- 마이크로아키텍처와 ISA 69
- ISA의 역사 71
- 복잡한 하드웨어에서 복잡한 소프트웨어로 73
- 파이프라인 및 수퍼스칼라 설계에 따른 변화 74
- 데이터 해저드 74
- 구조 해저드 76
- 레지스터 파일 77
- 제어 해저드 78
- 5장 펜티엄 79
- 오리지널 펜티엄 80
- 캐쉬 81
- 펜티엄 프로세서의 파이프라인 82
- 분기 유닛과 분기 예측 85
- 펜티엄 프로세서의 백엔드 87
- 펜티엄의 x86 지원 91
- 정리: 역사적 관점에서 본 펜티엄 프로세서 92
- 인텔 P6 마이크로아키텍처: 펜티엄 프로 93
- 프론트엔드와 백엔드의 분리 94
- P6 파이프라인 100
- P6에서의 분기 예측 102
- P6 백엔드 102
- CISC, RISC 및 명령어 변환 103
- P6 마이크로아키텍처의 명령어 디코드 유닛 106
- P6의 x86 지원 107
- 정리: 역사적 관점에서 본 P6 마이크로아키텍처 107
- 결론 110
- 오리지널 펜티엄 80
- 6장 파워PC 프로세서: 600계열, 700계열, 1400계열 111
- 파워PC의 역사 111
- 파워PC 601 112
- 601의 파이프라인과 프론트엔드 112
- 601의 백엔드 115
- 지연시간과 산출량 다시 보기 117
- 정리: 역사적 관점에서 본 601 118
- 파워PC 603과 603e 119
- 603의 백엔드 119
- 603e의 프론트엔드, 명령어 창, 분기 예측 122
- 정리: 역사적 관점에서 본 603과 603e 122
- 파워PC 604 123
- 604의 파이프라인과 백엔드 123
- 604의 프론트엔드와 명령어 창 126
- 정리: 역사적 관점에서 본 604 129
- 파워PC 604e 129
- 파워PC 750 (G3) 130
- 750의 프론트엔드, 명령어창, 분기 명령어 130
- 정리: 역사적 관점에서 본 750 132
- 파워PC 7400 (G4) 133
- G4의 벡터 유닛 135
- 정리: 역사적 관점에서 본 G4 135
- 결론 135
- 7장 인텔 펜티엄 4와 모토로라 G4e 137
- 속도 중독 - 펜티엄 4 138
- 펜티엄 4와 G4e의 문제 접근 방법과 설계 철학 140
- G4e 아키텍처 및 파이프라인 144
- 스테이지 1, 2: 명령어 페치 145
- 스테이지 3: 디코드/디스패치 145
- 스테이지 4: 이슈 146
- 스테이지 5: 수행 146
- 스테이지 6, 7: 완료 및 쓰기 147
- G4e와 펜티엄 4에서의 분기 예측 147
- 펜티엄 4 아키텍처 148
- 명령어 창의 확장 149
- 트레이스 캐쉬 149
- 펜티엄 4의 파이프라인 155
- 스테이지 1, 2: 트레이스 캐쉬 - 포인터 155
- 스테이지 3, 4: 트레이스 캐쉬 - 페치 155
- 스테이지 5: 드라이브 155
- 스테이지 6~8: 할당 및 리네임(ROB) 155
- 스테이지 9: 큐 156
- 스테이지 10~12: 스케줄링 156
- 스테이지 13~14: 이슈 157
- 스테이지 15~16: 레지스터 파일 158
- 스테이지 17: 수행 158
- 스테이지 18: 플래그 158
- 스테이지 19: 분기 점검 158
- 스테이지 20: 드라이브 158
- 스테이지 21 이후: 완료 및 커밋 159
- 펜티엄 4의 명령어 창 159
- 8장 인텔 펜티엄 4와 모토로라 G4e: 백엔드 161
- 피연산자 포맷 161
- 정수 수행 유닛 163
- G4e의 IU: 자주 발생하는 경우를 빠르게 163
- 펜티엄 4의 IU: 자주 발생하는 경우를 2배 빠르게 164
- 부동소수점 유닛 165
- G4e의 FPU 166
- 펜티엄 4의 FPU 167
- G4e와 펜티엄 4의 FPU에 대한 맺음말 168
- 벡터 수행 유닛 168
- 벡터 연산이란 168
- 벡터 다시 보기: 알티벡 명령어 169
- 알티벡 벡터 연산 170
- G4e의 VU: 제대로 구현된 SIMD 173
- 인텔 MMX 174
- SSE와 SSE2 175
- 펜티엄 4의 벡터 유닛 176
- SSE2를 사용한 부동소수점 성능 향상 177
- 결론 177
- 9장 64비트 컴퓨터와 x86-64 179
- 인텔 IA-64와 AMD x86-64 179
- 왜 64비트인가? 181
- 64비트 컴퓨터란? 181
- 64비트의 활용 영역 183
- 표현 영역 183
- 표현 범위 증가로 인한 이득 184
- 가상 주소 공간과 물리 주소 공간 185
- 64비트 주소의 이점 186
- 64비트로 된 대안: x86-64 187
- 레지스터의 확장 187
- 레지스터 수의 증가 187
- 모드 변환 189
- 오래된 기능의 퇴출 192
- 결론 192
- 10장 G5: IBM 파워PC 970 193
- 설계 철학 194
- 캐쉬와 프론트엔드 194
- 분기 예측 195
- 트레이드오프: 디코드, 크랙, 그룹 196
- 970의 디스패치 규칙 198
- 프리디코드와 그룹 디스패치 199
- 970의 그룹 디스패치 기법에 대한 결론 199
- 파워PC 970의 백엔드 200
- 정수 유닛, 조건 레지스터 유닛, 분기 유닛 200
- 동일하지 않은 정수 유닛 201
- 정수 유닛 지연시간 및 산출량 202
- CRU 202
- 970의 정수 성능에 대한 결론 203
- 로드 스토어 유닛 203
- 프론트 사이드 버스 204
- 부동소수점 유닛 205
- 파워PC 970에서의 벡터 처리 206
- 부동소수점 이슈 큐 209
- 정수 및 로드 스토어 이슈 큐 210
- BU 및 CRU 이슈 큐 210
- 벡터 이슈 큐 211
- 970 그룹 디스패치 기법의 성능 211
- 결론 213
- 11장 캐쉬와 시스템 성능 215
- 캐쉬의 기초 215
- 1차 캐쉬 217
- 2차 캐쉬 218
- 예: 메모리 계층 내에서의 데이터 이동 219
- 캐쉬 미스 220
- 데이터/코드의 집약성 220
- 데이터의 공간 집약성 221
- 코드의 공간 집약성 221
- 코드와 데이터의 시간 집약성 223
- 집약성: 결론 224
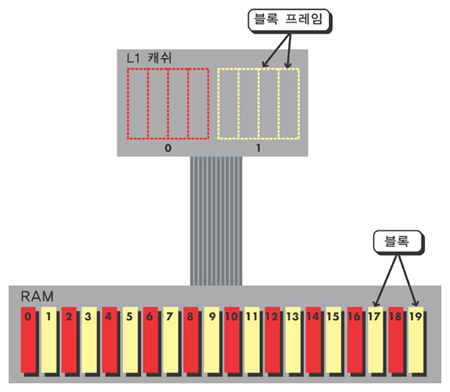
- 캐쉬의 구조: 블록과 블록 프레임 225
- 태그 RAM 226
- 완전 연관 매핑 226
- 집적 매핑 227
- N웨이 집합 연관 매핑 229
- 4웨이 집합 연관 매핑 229
- 2웨이 집합 연관 매핑 231
- 2웨이 집합 연관 매핑과 직접 매핑 231
- 2웨이 집합 연관 매핑과 4웨이 집합 연관 매핑 232
- 캐쉬의 집합 연관성: 결론 232
- 시간/공간/집약성과 캐쉬의 교체 정책 및 블록 크기와의 관계 233
- 고체/방출 정책의 종류 233
- 블록의 크기 234
- 쓰기 정책 라이트 스루와 라이트백 235
- 결론 236
- 캐쉬의 기초 215
- 12장 인텔 펜티엄 M, 코어 듀오, 코어 2 듀오 232
- 코드명과 브랜드명 235
- 전력 효율성을 중시한 컴퓨터의 등장 238
- 전력 밀도 239
- 동적 전력 밀도 239
- 정적 전력 밀도 240
- 펜티엄 M 241
- 페치 단계 241
- 디코드 단계: 마이크로옵 퓨전 242
- 분기 예측 246
- 스택 수행 유닛 248
- 파이프라인과 백엔드 248
- 정리: 역사적 관점에서 본 펜티엄 M 프로세서 248
- 코어 듀오/솔로 249
- 인텔이 설계한 멀티코어 프로세서 249
- 코어 듀오의 기능 향상 253
- 정리:역사적 관점에서 본 코어 듀오 256
- 코어 2 듀오 256
- 페치 단계 258
- 디코드 단계 259
- 코어의 파이프라인 260
- 코어의 백엔드 260
- 향상된 벡터 처리 264
- 메모리 명확화: 예측 수행의 결과 스트림 버전 266
관련 블로그 글
『인사이드 머신』재미있게 읽고 쉽게 배우자!

이 책 『인사이드 머신: 그림으로 배우는 컴퓨터 아키텍처와 마이크로프로세서』는 우리처럼 실제 프로세서가 어떻게 동작하는지 궁금해하는 사람들을 위해 쓰여졌다.
아마도 세상에서 가장 단순한 가상의 프로세서인 DLW-1으로 시작해서 1990년대의 펜티엄 계열의 프로세서와 파워PC 프로세서를 거쳐 출시된 지 얼마 안된 코어 2 듀오 프로세서에 이르기까지, 저자는 배경지식이 없는 초보자도 쉽게 이해할 수 있도록 수많은 프로세서의 동작 원리에 대해 친절하게 알려준다. 이 과정을 통해 여러분은 그 좋다는 파워PC 프로세서가 언젠가부터 왜 사라지기 시작했는지, 요즘 들어 프로세서의 클럭 속도는 왜 예전처럼 빨라지지 않는지에 대한 근본적인 이유를 알 수 있게 된다.
이 책이 나오기 전까지는 이 정도의 지식을 얻기 위해 수십 편의 논문을 읽고 고민해야 했었던 난제를 풀어주고 있는 것이다.
- 옮긴이의 말 중에서

서울대 컴공과 대학 동기로 나란히 지금 UC 산디에고에서 공부 중인 역자 전동환, 안익진 님 고생 많으셨습니다. 전동환 님은 에이콘의 스테디 셀러인『RTOS를 이용한 임베디드 시스템 디자인』『임베디드 시스템 펌웨어 분석』『GREAT CODE : 제1권 하드웨어의 이해』등을 번역하신 임베디드 및 프로그래밍 분야의 특급 역자로서 이번에도 미국에서 구글닥스, PDF 파일 교환 등 더욱 진보된(!) 방법으로 번역을 진행하며 좋은 책 만드는 데 일조해주셨습니다. (전동환님 동생분은 지금 아침 6시 45분 MBC 뉴스를 진행하고 계시는 전종환 아나운서라고 합니다. 아침 잠이 많은 관계로 아직 한번도 못봤는데 곧 한번 볼게요! -0-)
막판 마무리때는 지구 한 바퀴를 돌아 낮밤을 교대로 24시간 풀 가동으로 진행했던지라 효율도 높았지요. 무엇보다도 좋은 문장으로 원고의 품질을 높여주시고 꼼꼼하게 작업해주신 역자분께 감사합니다.
자, 이제 미투데이에서 프리버즈님도 탐을 냈던 하드웨어 그림책 등장입니다. :)


프로세서 구조를 다루는 많은 책들이 있어 왔지만, 근래에 보기 드문 좋은 책이 나왔다. 이 책은 자세하고 멋진 일러스트레이션과 함께 프로세서가 동작하는 구조를 아주 명쾌하게 설명하고 있다.컴퓨터 아키텍처와의 즐겁고 재미있는 여행, 여러분께 추천합니다!
물론 이 책은 기본적으로 프로세서를 설계할 전공자들이 봐야 할 책이다. 하지만 그저 책을 훑어 읽어 내려가는 것만으로 프로세서 구조와 동작을 쉽게 이해할 수 있기 때문에 프로세서 설계와 관계 없는 소프트웨어 개발자도 이 책을 보면 많은 도움을 받을 수 있을 것이다.
- 성원호 / 임베디드 시리즈 에디터

크리에이티브 커먼즈 라이센스 이 저작물은 크리에이티브 커먼즈 코리아 저작자표시 2.0 대한민국 라이센스에 따라 이용하실 수 있습니다.
[출간예정] 『인사이드 머신』

존 스토크스 지음 / 전동환 안익진 옮김 / 320페이지 / 26,000원 / 올컬러
단언컨대 이 책은 내가 지금까지 본 것 중 가장 잘 쓰여진 컴퓨터 아키텍처 책이다. 명료한 설명에 논리적인 구성, 최신 내용을 담고 있다. 이 분야에 관한 지식이 필요한 학생이나 직장인을 위한 필독서이다.- 존 스트로만 / 인텔 사의 기술 매니저
이 책은 컴퓨터 아키텍처의 고전인, 하지만 읽기는 쉽지 않은 헤네시/패터슨의 저서와 엔지니어에게는 너무 기초적인 “컴퓨터는 어떻게 동작하는가”류의 서적 사이의 간극을 메워주는 역할을 한다. 이 책은 읽기 쉬우며, 마이크로프로세서 분야에서 몇 년의 실무 경험이 있는 사람도 새로 배우는 것이 있을 정도로 교육적이다. 특히 컬러로 구성된 그림들은 정말 훌륭하다.
– 아마존 리뷰어 calvinnme "Texan refugee"
이 책을 다 읽을 때쯤이면, 2.8Ghz 프로세서가 3.2Ghz 프로세서보다 훨씬 빠를 수도 있음을 알게 될 것이다. 컬러로 된 그림들과 저자의 친절한 설명 덕분에 이 책은 ‘재미있게’ 읽을 수 있다. 전공을 하지 않고서도 마이크로프로세서의 설계에 대해 배울 수 있는 길이 이 책에 모두 담겨있다.
- 아마존 리뷰어 “Thomas Duff "Duffbert"
최근 이 책의 원서가 아마존 서평 별 5개에, 컴퓨터/인터넷 부문 베스트셀러 4위까지 오르며 호평을 받고 있습니다. 모두 한결같이 하는 이야기가 있습니다.
진작 이런 책이 나왔으면 내가 고생을 안했을 텐데... 그림으로 알기 쉽게 설명되어 있어서 이해하기도 쉽다. 누구나 꼭 읽어봐야 할 책!
하드웨어 책 답지 않게 올 컬러 장정으로 눈에 쏙 들어오는 그림과 사례를 들어 설명하는 재미있는 서술 방식으로 쓰여진 이 책. 컴퓨터 아키텍처 책도 이렇게 쉽고 재미있게 읽을 수 있다는 걸 직접 느껴보세요~ :) 3월 말에 찾아갑니다!
크리에이티브 커먼즈 라이센스 이 저작물은 크리에이티브 커먼즈 코리아 저작자표시 2.0 대한민국 라이센스에 따라 이용하실 수 있습니다.
도서 오류 신고
정오표
[ p21 세 번째 문단 ]
명령어의 1-3비트, 2-4비트는 연산코드이다.
→ 명령어의 1-3비트는 연산코드이다.
[ p22 상단 표 4행 ]
p.22 맨위의 표 4번째 항목
add A, D, C
→ sub A, D, C
[ p22 하단 표 3, 4행 ]
add 5, a, c
sub 25, d, c
→ add 5, A, C
sub 25, D, C
[ p23 표 ]
add C,8,A 10001000 00001000
→ load #12, A 10100000 00001100
[ p33 프로그램 2-3 코드 열]
sub A, B, C
jumpz #106
add A, B, C
→ sub A, B, A
jumpz #C
add A, 15, A
[ p57 '명령어 지연시간과 파이프라인 멈춤' 절 4행]
그림 3-6에서 시각적으로 → 그림 3-7에서 시각적으로
[ p64 세 번째 문단 1행 ]
클럭 당 1개 이상의 → 1개를 넘어선
[ p74 프로그램 4-1 2행 코드 열]
add A, B, C → add C, D, D
[ p96 아래에서 7행 ]
그림 5-3 → 표 5-3
[ p103 그림 5-9 ]
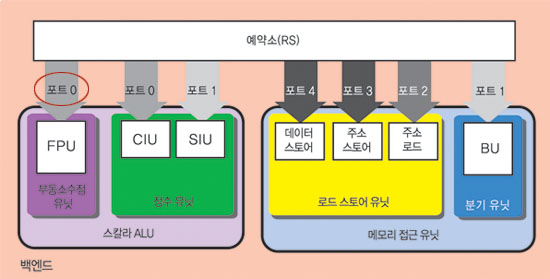
[ p106 2행 ]
x86 명령어는 → x86 명령어를
[ p111 아래에서 5행 ]
RISC 마이트로프로세스 → RISC 마이크로프로세스
[ p114 그림 6-1 ]
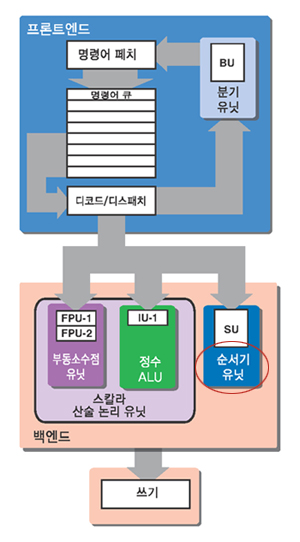
[ p136 1행 ]
604년 306의 → 604는 603의
[ p173 마지막 절 제목 ]
단순한 정수 벡터 유닛 → 단순한 정수 벡터 유닛(VSIU)
[ p182 그림 9-2 ]
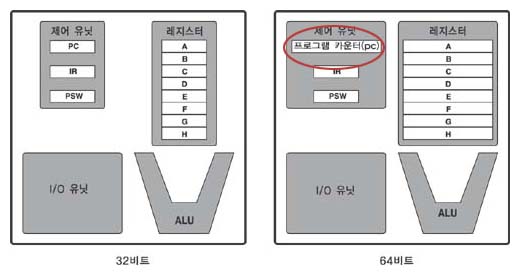
[ p197 ● 항목 부분 ]
● 2개의 ~
● 2개 이상의 ~
→ ● 정확하게 2개의 ~
● 3개 이상의 ~
[ p206 ● 항목 부분 ]
● 부동소수점 명령어가 아닌 3개 이상의
→ ● 부동소수점 명령어가 아닌 4개 이상의
[ p220 네 번째 문단 3행 ]
230페이지 '시간/공간 집약성 다시 보기: 교체 정책 및 블록 크기'
→ 232페이지 '시간/공간 집약성 다시 보기: 교체 정책 및 블록 크기'
[ p225 2행 ]
이 방식에 따라 특정 메모리 블록이 저잘될 수 있는
→ 이 방식에 따라 특정 메모리 블록이 저장될 수 있는
[ p225 ● 항목 부분 ]
● 요데이터가 캐쉬에 있는가 → ● 요청한 데이터가 캐쉬에 있는가
[ p229 그림 11-8 교체 ]
[ p242 아래에서 4행 ]
1개 이상의 → 2개 이상의
[ p250 아래에서 3행 ]
1개 이상의 코어를 → 2개 이상의 코어를
[ p260 '코어의 백엔드' 절 두 번째 단락 1행 ]
과거 이슈 포트의 → 이슈 포트의
[ p260 '코어의 백엔드' 절 세 번째 단락 2행 ]
최대 5개의 명령어을 → 최대 5개의 명령어를
명령어의 1-3비트, 2-4비트는 연산코드이다.
→ 명령어의 1-3비트는 연산코드이다.
[ p22 상단 표 4행 ]
p.22 맨위의 표 4번째 항목
add A, D, C
→ sub A, D, C
[ p22 하단 표 3, 4행 ]
add 5, a, c
sub 25, d, c
→ add 5, A, C
sub 25, D, C
[ p23 표 ]
add C,8,A 10001000 00001000
→ load #12, A 10100000 00001100
[ p33 프로그램 2-3 코드 열]
sub A, B, C
jumpz #106
add A, B, C
→ sub A, B, A
jumpz #C
add A, 15, A
[ p57 '명령어 지연시간과 파이프라인 멈춤' 절 4행]
그림 3-6에서 시각적으로 → 그림 3-7에서 시각적으로
[ p64 세 번째 문단 1행 ]
클럭 당 1개 이상의 → 1개를 넘어선
[ p74 프로그램 4-1 2행 코드 열]
add A, B, C → add C, D, D
[ p96 아래에서 7행 ]
그림 5-3 → 표 5-3
[ p103 그림 5-9 ]
[ p106 2행 ]
x86 명령어는 → x86 명령어를
[ p111 아래에서 5행 ]
RISC 마이트로프로세스 → RISC 마이크로프로세스
[ p114 그림 6-1 ]
[ p136 1행 ]
604년 306의 → 604는 603의
[ p173 마지막 절 제목 ]
단순한 정수 벡터 유닛 → 단순한 정수 벡터 유닛(VSIU)
[ p182 그림 9-2 ]
[ p197 ● 항목 부분 ]
● 2개의 ~
● 2개 이상의 ~
→ ● 정확하게 2개의 ~
● 3개 이상의 ~
[ p206 ● 항목 부분 ]
● 부동소수점 명령어가 아닌 3개 이상의
→ ● 부동소수점 명령어가 아닌 4개 이상의
[ p220 네 번째 문단 3행 ]
230페이지 '시간/공간 집약성 다시 보기: 교체 정책 및 블록 크기'
→ 232페이지 '시간/공간 집약성 다시 보기: 교체 정책 및 블록 크기'
[ p225 2행 ]
이 방식에 따라 특정 메모리 블록이 저잘될 수 있는
→ 이 방식에 따라 특정 메모리 블록이 저장될 수 있는
[ p225 ● 항목 부분 ]
● 요데이터가 캐쉬에 있는가 → ● 요청한 데이터가 캐쉬에 있는가
[ p229 그림 11-8 교체 ]
[ p242 아래에서 4행 ]
1개 이상의 → 2개 이상의
[ p250 아래에서 3행 ]
1개 이상의 코어를 → 2개 이상의 코어를
[ p260 '코어의 백엔드' 절 두 번째 단락 1행 ]
과거 이슈 포트의 → 이슈 포트의
[ p260 '코어의 백엔드' 절 세 번째 단락 2행 ]
최대 5개의 명령어을 → 최대 5개의 명령어를