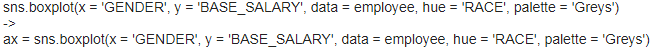Pandas Cookbook [과학 연산, 시계열 분석, 파이썬을 이용한 시각화, 정돈된 데이터 만들기]
- 원서명Pandas Cookbook: Recipes for Scientific Computing, Time Series Analysis and Data Visualization using Python (ISBN 9781784393878)
- 지은이시어도어 페트로우(Theodore Petrou)
- 옮긴이CRAS 금융경제 연구소
- ISBN : 9791161751252
- 40,000원
- 2018년 03월 30일 펴냄 (절판)
- 페이퍼백 | 620쪽 | 188*235mm
- 시리즈 : acorn+PACKT
판매처
- 현재 이 도서는 구매할 수 없습니다.
책 소개
소스 코드 파일은 여기에서 내려 받으실 수 있습니다.
요약
Pandas가 가진 모든 기능을 친절한 예제와 설명, 실제 파이썬 코드를 통한 실습을 통해 설명한다. Pandas의 핵심인 DataFrame과 Series를 주축으로, 대부분의 함수, 메서드, 속성을 설명하고 각각이 가진 장단점과 메모리 사용량과 처리 시간도 비교해 준다. 또한 금융데이터에 있어 가장 중요한 시계열 자료를 처리하는 다양한 방법은 물론 SQL 데이터베이스와 연결하는 방법도 알려준다.
이와 함께 정돈된 데이터(Tidy data)에 대한 정의와 함께 데이터를 정돈하기 위한 방법과 절차에 대해 자세히 알아보고 matplotlib, 파이썬 plot, seaborn을 이용한 데이터 시각화에 대해 자세히 설명하고 각각의 장단점을 상세히 설명한다.
이 책에서 다루는 내용
■ 모든 데이터셋의 탐색이 가능하도록 해주는 Pandas의 기본 지식 마스터
■ 쿼리와 선택을 통해 데이터 중 원하는 부분만 부분집합으로 적절히 골라내는 방법
■ 데이터를 종합하거나 각 그룹으로 변환하기 전 개별 그룹으로 분할하는 방법
■ 데이터 분석 및 시각화가 용이하도록 데이터를 정돈된 형식으로 재구성
■ 정리되지 않은 실제 데이터를 머신 러닝에서 사용할 수 있도록 준비
■ SQL 유사 연산 기능을 통해 서로 다른 소스의 데이터 병합
■ 독보적인 시계열 데이터 처리 능력
■ matplitlib나 seaborn을 사용한 멋지면서도 동시에 통찰을 얻을 수 있는 시각화 기능
이 책의 대상 독자
이 책은 단순한 레시피에서 고급 레시피까지 거의 100가지 정도의 레시피를 다루고 있다. 모든 레시피는 최신 파이썬 문법과 구문을 사용해 작성됐다. ‘작동 원리’ 절에서는 레시피의 복잡한 각 단계에 대해 상세한 설명을 제공한다. 종종 ‘추가 사항’ 절에서 완전히 새로운 레시피에 대한 정보를 얻을 수 있다. 이 책은 방대한 Pandas 코드를 제공한다.
일반적으로 처음 6개 장의 레시피는 간단하며, 나머지 5개 장에 비해 기본적이고 근본적인 Pandas 연산에 중점을 두고 있고, 나머지 5개 장은 고급 연산과 프로젝트에 기반을 둔 레시피를 소개한다. 이 책의 난이도는 광범위하기 때문에 초보자와 숙련자 모두에게 유용하다. 따라서 Pandas를 일상적으로 사용하는 사람도 Pandas의 관용구에 익숙해지지 않으면 마스터할 수 없다. 이 점은 Pandas의 방대한 영역에서 비롯된다. 대부분 동일한 연산을 수행할 수 있는 여러 가지 방법이 존재하는데 사용자가 원하는 결과를 얻을 수는 있지만 비효율적인 방법을 사용할 가능성이 있으며, 동일한 문제를 해결하는 Pandas 솔루션의 속도 차이가 몇 제곱 이상 다른 경우도 많다.
책을 읽기 위한 필수 지식은 오직 파이썬뿐이다. 독자가 리스트, 집합, 딕셔너리, 튜플 등과 같은 파이썬의 내장 데이터 저장소에 어느 정도 익숙하다고 가정한다.
이 책의 구성
1장, ‘Pandas 기초’에서는 Pandas 데이터 구조를 이루는 두 구성 요소인 Series와 DataFrame를 해부하고 용어를 정리한다. 각 열은 동일한 데이터 형식을 가져야 하는데, 각 데이터 형식을 알아본다. 이를 통해 Series와 DataFrame의 메서드를 호출하고 체인시키면서 두 요소의 진정한 힘을 배우게 될 것이다.
2장, ‘DataFrame 필수 연산’에서는 데이터 분석을 위해 가장 중요하고 보편적인 연산에 대해 알아본다.
3장, ‘데이터 분석 시작’에서는 데이터를 읽어 들인 후, 해야 할 반복적인 작업을 개발하는 데 도움을 줄 것이다. 이외에 흥미로운 점도 많이 발견하게 될 것이다.
4장, ‘데이터의 부분 집합 선택’에서는 서로 다른 부분 집합 선택에 있어 혼동되는 부분 등 여러 주제에 대해 다룬다.
5장, ‘불리언 인덱싱’에서는 불리언 조건을 이용해 데이터의 부분 집합을 선택하는 쿼리 프로세스를 다룬다.
6장, ‘인덱스 정렬’에서는 아주 중요하지만 종종 잘못 이해되고 있는 인덱스(index) 객체를 다룬다. 인덱스를 잘못 다루면 수많은 잘못된 결과를 초래하는데, 6장에서는 강력한 결과를 얻기 위한 올바른 사용법에 대해 알아본다.
7장, ‘종합, 필터링, 변환을 위한 종합’에서는 데이터를 분석하는 동안 항상 필요한 강력한 그룹화 기능에 대해 다룬다. 목적에 맞는 그룹에 적용할 사용자 정의 함수를 구성할 수 있게 될 것이다.
8장, ‘데이터를 정돈된 형태로 재구성’에서는 정돈된 데이터에 대해 설명하고 왜 중요한지 알아본다. 또 서로 다른 혼란된 형태로 된 데이터를 정돈하는 법에 대해 다룬다.
9장, ‘Pandas 객체 병합’에서는 DataFrames와 Series를 수직과 수평으로 병합하는 여러 메서드에 대해 알아본다. 또 웹 스크래핑을 통해 트럼프와 오바마 대통령의 국정 수행 평가 점수를 비교하고 SQL 관계형 데이터베이스에 연결해본다.
10장, ‘시계열 분석’은 가능한 모든 시간 차원에 따라 분해를 위한 시계열 기능의 강력한 고급 기능에 대해 알아본다.
11장, ‘Matplotlib, Pandas, Seaborn을 이용한 시각화’에서는 Pandas의 모든 도식화의 기본이되는 matplotlib 라이브러리를 소개한다. 그런 다음, Pandas plot 메서드와 seaborn 라이브러리 등 Pandas에서 직접적으로 제공되지 않는 다양하고 심미적인 시각화 기능에 대해 알아본다.
목차
목차
- 1장. Pandas 기초
- 소개
- DataFrame 해부
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- DataFrame의 주요 구성 요소 이용
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- 데이터 형식 이해하기
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- 데이터 단일 열을 Series로 선택하기
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- Series 메서드 호출
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- Series에 연산자 사용하기
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- Series 메서드를 함께 사용하기
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 인덱스를 의미 있게 만들기
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- 열과 행 이름 다시 짓기
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 열의 생성과 삭제
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- 2장. DataFrame 필수 연산
- 소개
- DataFrame에서 복수 열 선택
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 메서드를 사용한 열 선택
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- 열 이름 일목요연하게 정렬하기
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- 전체 DataFrame에 대한 연산
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- DataFrame 메서드 체인으로 묶기
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- DataFrame에서 연산자 이용
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- 누락값 비교
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- DataFrame 연산의 방향 바꾸기
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- 대학 캠퍼스의 다양성 지수 발견
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- 3장. 데이터 분석 시작
- 소개
- 데이터 분석 루틴 개발
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 데이터 딕셔너리
- 참고문헌
- 데이터 형식 변경을 통한 메모리 절약
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- 최대에서 최소 선택
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 정렬에 의해 각 그룹의 최대 선택
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- sort_values를 사용해 nlargest를 복제
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 추적 지정 주문가 계산
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- 4장. 데이터의 부분 집합 선택
- 소개
- Series 데이터 선택
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- DataFrame 행 선택
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- DataFrame의 행과 열을 동시에 선택하기
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 정수와 레이블을 동시에 사용해 데이터 선택
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- 스칼라 더 빠르게 선택하기
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 게으른 행 슬라이스
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 사전 순서로 슬라이스
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 5장. 불리언 인덱싱
- 소개
- 불리언 통계량 계산
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- 다중 불리언 조건 구축
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- 불리언 인덱싱을 사용한 필터링
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- 인덱스를 사용한 불리언 인덱싱의 복제
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 고유한 정렬된 인덱스를 사용한 선택
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- 주가 전망
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- SQL WHERE 절 해석
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- 주식 시장 수익률의 정규성 검정
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- query 메서드를 사용한 불리언 인덱싱의 가독성 개선
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- where 메서드를 사용한 Series 보존
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- DataFrame 행 마스크
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- 불리언, 정수 위치, 레이블을 이용한 선택
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- 6장. 인덱스 정렬
- 소개
- 인덱스 객체 관찰
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- 카디션 곱 생성
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- 인덱스 폭발
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 서로 다른 인덱스에 값 채우기
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 다른 DataFrames의 열 추가
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- 각 열의 최댓값 부각하기
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- 메서드 체인을 사용한 idxmax 복제
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 가장 흔한 최대값 찾기
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 7장. 종합을 위한 그룹화, 필터링 그리고 변환
- 소개
- 종합에 대한 정의
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- 복수 열과 함수를 사용한 그룹화와 집계
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 그룹화 후 MultiIndex 제거
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 종합 함수 커스터마이징
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- *args와 **kwargs를 사용한 종합 함수 커스터마이징
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- groupby 객체 조사
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- 소수 인종이 다수인 주 찾기
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- 체중 감량 내기를 통한 변환
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- apply를 이용한 주별 가중 평균 SAT 점수 계산
- 준비 단계
- 작동 원리
- 추가 사항
- 참고문헌
- 연속 변수에 의한 그룹화
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- 도시 간 총 비행 횟수 계산
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- 최장 연속 정시 비행 찾기
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- 8장. 정돈된 형태로 데이터 재구성
- 소개
- stack을 이용해 변숫값을 변수 이름으로 정돈
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- 복수 변수 그룹을 동시에 스태킹
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- 스택된 데이터 되돌리기
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- groupby 종합 후 Unstacking
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- groupby 종합으로 pivot_table 복제
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 쉬운 재구축을 위해 레벨 재명명
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 복수 변수가 열 이름으로 저장됐을 때의 정돈
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- 복수 변수가 열값으로 저장된 경우의 정돈
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- 같은 셀에 여러 값이 저장된 경우의 정돈
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 변수가 열 이름과 값에 저장된 경우의 정돈
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 동일 표에 복수 관측 단위가 저장된 경우의 정돈
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- 9장. Pandas 객체 합치기
- 소개
- DataFrames에 새로운 행 추가
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 복수 DataFrames 연결
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 트럼프와 오바마 대통령 국정 수행 능력 평가 비교
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- concat, join, merge 사이의 차이점 이해하기
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- SQL 데이터베이스에 연결
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- 10장. 시계열 분석
- 소개
- 파이썬과 Pandas의 날짜 도구 차이 이해
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- 시계열을 현명하게 분할하기
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- DatetimeIndex와만 작동하는 메서드 사용하기
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- 주간 범죄 건수 알아보기
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- 주별 범죄와 교통사고를 별도로 종합
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 범죄를 주별과 연도로 측정
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- DatetimeIndex에서 익명 함수를 사용한 그룹화
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- Timestamp와 다른 열을 이용한 그룹화
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- merge_asof를 사용해 범죄율이 20% 낮은 마지막 시기 찾기
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 11장. Matplotlib, Pandas, Seaborn을 이용한 시각화
- 소개
- matplotlib 다뤄 보기
- 준비 단계
- matplotlib에 대한 객체지향 가이드
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- matplotlib를 이용한 데이터 시각화
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- Pandas를 이용한 도식화 기초
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- 참고문헌
- 비행 데이터셋 시각화
- 준비 단계
- 방법
- 작동 원리
- 참고문헌
- 영역 그래프를 스태킹해 새로운 추세 발견
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- seaborn과 pandas의 차이점 이해
- 준비 단계
- 방법
- 작동 원리
- 참고문헌
- seaborn Grid를 사용한 다변량 분석
- 준비 단계
- 방법
- 작동 원리
- 추가 사항
- seaborn을 사용해 다이어몬드 데이터셋에 있는 심슨의 역설 발견
- 준비 단계
- 방법
- 작동 원리
- seaborn과 pandas의 차이점 이해
도서 오류 신고
정오표
정오표
[p.45]

[p.45]
컬러 이미지 다운로드
[p.49 : 6행]
또 인데스가
->
또 인덱스가
[p.142]
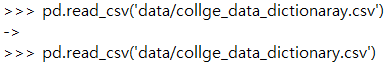
[p.142]
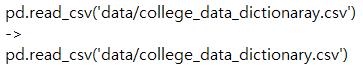
[p.146 : 6번 코드]

[p.472 : 1번 코드]

[p.472 : 2와 3 사이]
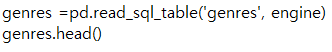
[p.529 : 4번 코드]

[p.553]

[p.595]