


Programming in Scala 3/e [창시자가 직접 집필한 스칼라 언어의 바이블]
- 원서명Programming in Scala: Updated for Scala 2.12 (ISBN 9780981531687)
- 지은이마틴 오더스키(Martin Odersky), 렉스 스푼(Lex Spoon), 빌 베너스(Bill Venners)
- 옮긴이오현석, 반영록, 이동욱
- ISBN : 9788960777736
- 50,000원
- 2017년 05월 23일 펴냄
- 페이퍼백 | 872쪽 | 188*250mm
- 시리즈 : 프로그래밍 언어
판매처
개정판책 소개
요약
스칼라는 여러 함수 언어적 기법과 객체지향 기법을 한데 잘 녹여서 루비나 파이썬 같은 동적 언어 못지않게 간결하면서 풍부한 표현력을 가진 언어다. 지난 몇 년간 빅데이터나 머신 러닝 등의 최첨단 분야에 널리 쓰이고 있다. 스칼라를 만든 마틴 오더스키 등이 집필한 이 책은 스칼라의 다양한 측면을 완벽하게 설명한 스칼라 언어의 바이블이다.
함수, 트레이트, 암시적 변환, 모듈 등 스칼라의 기본 문법과 컬렉션 사용법, 컬렉션의 내부 구조, 객체지향 및 함수 프로그래밍을 활용하는 방법을 다룬다. 또한 퓨처를 사용한 동시성 프로그래밍, 자바와의 조합, 파싱, GUI 프로그래밍 같은 응용을 설명한 2판의 내용을 수정, 보완했으며, 최신 버전인 스칼라 2.12에 맞춰서 문자열 인터폴레이션이나 와일드카드 타입 등의 내용이 추가됐다. 차근차근 따라하다 보면 숙련된 스칼라 개발자가 될 수 있으며, 동시에 다양한 프로그래밍 패러다임을 한 언어에 자연스럽게 녹이는 방법과, 각각을 적재적소에 활용하는 방법을 배울 수 있다.
이 책에서 다루는 내용
여러분의 학습을 돕기 위해 주의 깊게 쓰여졌다. 앞의 몇 장을 통해 기본적인 내용을 배우고 나면 간단한 작업을 수행하는 데 스칼라를 사용할 수 있다. 전체적인 내용은 앞에서 다룬 개념을 바탕으로 새로운 개념을 배울 수 있도록 잘 배열되어 있다. 따라서 각 단계를 차근차근 밟으면 스칼라 언어와 그 언어에 담겨있는 프로그래밍에 대한 여러 아이디어를 통달할 수 있다.
이 책은 종합적인 자습서이자 참고서로 스칼라 언어의 모든 특징과 중요한 라이브러리를 다룬다.
3판은 스칼라 2.9부터 시작해 스칼라 2.12에 이르기까지 새로 도입된 여러 기능을 다루는 내용을 추가하고, 책의 내용을 스칼라 2.12의 최신 흐름에 맞춰서 변경했다. 변경된 부분은 다음과 같다.
■ 스프링 인터폴레이션
■ 함수형 퓨처
■ 암시적 클래스
■ 새로운 값 클래스(AnyVal) 정의
■ 타입클래스와 맥락 바운드(context bound)
■ 최신 스칼라 프로그래밍 스타일
■ 스칼라 2.12의 자바 SAM (단일 추상 메서드)지원
이 책에 쏟아진 찬사
이 책은 지금까지 내가 읽어본 최고의 프로그래밍 책 중 하나다. 문체와 간결성, 철저한 설명이 마음에 든다. 이 책은 내가 던질 수 있는 모든 의문에 답한다. 항상 책이 나보다 한발 앞서 있다. 저자들은 코드를 던져주고 모든 걸 받아들이라고 강요하지 않는다. 어떤 일이 벌어지는지 제대로 알 수 있도록 항상 자세한 설명을 제공한다.
- 켄 에거베리(Ken Egervari) / 수석 소프트웨어 아키텍트
이 책은 명확하고 철저하며, 따라가기 쉽게 구성돼 있다. 게다가 예제도 훌륭하고 유용한 팁도 제공한다. 이 책 덕분에 스칼라 언어를 빠르고 효과적으로 적용할 수 있었다. 스칼라 언어의 유연함과 우아함을 깊이 느껴보고 싶은 프로그래머에게 가장 좋은 책이다.
- 래리 모로니(Larry Morroni) / 모로니 테크놀로지스 사(Morroni Technologies, Inc.) 대표
이 책은 훌륭한 스칼라 자습서다. 각 장의 개념이나 예제를 설명할 때, 앞에서 다룬 내용을 바탕으로 설명하기 때문에 따라가기 쉽다. 언어 구성요소를 정성 들여 깊이 있게 설명하며, 때때로 자바와의 차이점을 설명하는 예제도 제공한다. 또한 스칼라 언어 외에 컨테이너와 액터 같은 일부 라이브러리도 설명한다.
읽기 쉬운 이 책은 내가 최근에 읽은 책 중 잘 쓰여진 책으로 꼽을 만하다. 스칼라 언어를 더 잘 알고 싶은 모든 프로그래머에게 추천하고 싶다.
- 매튜 토드(Matthew Todd)
추천사
여러분은 아주 적절한 때에 이 책을 선택한 것이다. 스칼라가 채택되는 속도가 점점 빨라지고, 커뮤니티는 활발하며, 관련된 일자리도 충분하다. 재미를 위해 코딩을 하든 이익을 위해 코딩을 하든(또는 두 가지 모두를 목적으로 하든) 스칼라는 재미와 생산성을 약속하며 이에 저항하기는 어렵다. 내게 있어 프로그래밍의 참 재미는 어렵고 흥미진진한 문제를 단순하면서도 복잡한 해법으로 처리해나가는 데 있다. 스칼라의 사명은 이를 가능하게 할 뿐만 아니라, 더 즐기기 좋게 만들어주는 것이다.
스칼라 2.5를 처음 시험해본 후 스칼라의 문법적, 개념적 균일성에 매료됐다. 타입 파라미터 자체에는 타입 파라미터가 있을 수 없다는 불균일성을 발견하자마자 2006년 한 컨퍼런스에서 마틴 오더스키에게 그 제약을 해결하기 위한 인턴십을 제안했다. 내가 기여한 부분이 받아들여져서, 스칼라 2.7부터는 타입 생성자 다형성에 대한 지원이 들어갔다. 그때부터 스칼라 컴파일러의 대부분에 기여해왔다. 2012년에는 마틴 실험실의 박사 후 과정 연구원에서 타입세이프 사(현 라이트벤드)의 팀 리드로 자리를 옮겼다. 동시에 스칼라도 버전 2.10에 이르러 실용적이면서 학술적인 언어라는 모판을 떠나 기업을 위한 강건한 언어라는 논으로 자리를 옮겼다.
스칼라 2.10은 학술 연구를 바탕으로 빠르게 특성을 추가하면서 배포하는 것에서 기업의 사용 장려와 언어의 단순화로 목표를 바꿨다. 우리는 주요 버전 간의 이진(바이너리) 호환성처럼 박사 논문거리가 되지 못하는 주제로 주의를 돌리기 시작했다. 스칼라 플랫폼을 계속 진화시키고 더 세련되게 다듬고자 하는 욕구와 안정성 사이에서 균형을 잡기 위해, 핵심 라이브러리를 더 작게 줄여서 전체적인 플랫폼의 진화를 안정시키고자 했다. 이를 달성하기 위한 첫 번째 프로젝트는 스칼라 2.11부터 표준 라이브러리를 모듈화하기 시작한 것이었다.
라이트벤드는 변화 속도를 줄이기 위해 라이브러리의 변경과 컴파일러의 변경을 번갈아 진행하기로 결정했다. 이 책은 스칼라 2.12를 다룬다. 스칼라 2.12는 새로운 컴파일러 백엔드와 최적화기를 포함시켜 자바 8의 새로운 기능을 대부분 살린 컴파일러 릴리즈가 될 것이다. 자바와의 상호 운용성을 살리고 JVM 최적화의 이점을 똑같이 누리기 위해 스칼라는 함수를 자바 8 컴파일러와 똑같은 바이트코드로 컴파일한다. 그와 비슷하게 스칼라 트레이트는 디폴트 메소드가 들어 있는 자바 인터페이스로 컴파일된다. 이 두 가지 컴파일 방식은 예전의 스칼라 컴파일러가 수행해야만 했던 여러 마술을 줄여준다. 그로 인해 컴파일 시간은 줄고 실행 시점의 성능이 좋아지며, 이진 호환성 보장도 더 편해진다!
이러한 자바 8 플랫폼에 대한 개선은 스칼라에 있어 매우 흥미로운 점이다. 또한 자바가 스칼라가 십여 년간 다져왔던 길을 따라서 발전하고 있는 모습을 보는 일도 매우 보람 있다. 자바의 변화에도 불구하고 불변성을 기본으로 하고, 식을 균일하게 다루며(이 책에서 return문을 찾아보기 힘들 것이다), 패턴 매치, 정의 지점의 변성 지정(자바는 사용 지점의 변성 지정을 사용하기 때문에 함수의 서브타입 지정이 상당히 이상해진다) 등을 제공하기 때문에 스칼라를 사용하면 더 나은 함수형 프로그래밍을 경험할 수 있다! 좀 노골적으로 말하자면 함수형 프로그래밍에는 깔끔한 람다 문법 외에도 많은 것들이 존재한다.
이 언어를 지키는 집사로서 우리의 목표는 핵심 언어를 개발하는 것 못지않게 에코시스템을 키워나가는 것이다. 수많은 훌륭한 라이브러리, 뛰어난 IDE와 도구, 그리고 커뮤니티의 친절하고 협력적인 구성원들로 인해 스칼라가 성공할 수 있었다. 스칼라와 함께했던 최초의 10년은 한결같이 즐거웠다. 언어를 구현하는 사람으로서 다양한 분야에서 스칼라를 즐기고 있는 여러 프로그래머를 만날 수 있었던 것은 흥미진진하고 고무적인 일이었다.
나는 스칼라로 프로그래밍하는 것(programming in scala)을 좋아한다. 스칼라 커뮤니티를 대신해 여러분을 환영한다!
아드리안 무어스(Adriaan Moors) 미국 캘리포니아 주 샌프란시스코 2016년 1월 14일
이 책의 대상 독자
주요 대상 독자는 스칼라로 프로그램을 작성하는 법을 배우고 싶은 프로그래머다. 다음 프로젝트를 스칼라로 진행하고 싶다면 이 책은 바로 당신을 위한 것이다. 또한 새로운 개념을 배워서 생각의 지평을 넓히고 싶은 프로그래머에게도 재미있을 것이다. 예를 들어 자바 프로그래머는 이 책을 읽고 다양한 함수형 프로그래밍 개념을 익히고 더 발전된 객체지향 아이디어도 배울 수 있다. 스칼라와 그 아이디어에 대해 배우고 나면 분명 더 나은 프로그래머가 되어 있으리라 믿는다.
이 책에서는 독자 여러분이 일반적인 프로그래밍 지식을 갖췄다고 가정한다. 스칼라 자체는 프로그래밍을 처음 배울 때도 적합한 언어이긴 하지만, 이 책은 프로그래밍을 가르쳐주지는 않는다.
다시 말해 프로그래밍 언어에 대한 선행 지식이 필요하지는 않다. 대부분의 프로그래머가 스칼라를 자바 플랫폼에서 사용하기는 하지만, 독자들이 자바에 대해 알고 있으리라 가정하지는 않는다. 그러나 많은 독자가 자바에 익숙하리라 예상하기 때문에 때때로 자바와 스칼라를 비교해서 자바 개발에 익숙한 독자들의 이해를 도울 것이다.
이 책의 구성
1장, ‘확장 가능한 언어’에서는 스칼라 설계와 그 이유를 설명하고, 배경과 역사를 설명한다.
2장, ‘스칼라 첫걸음’에서는 기초 프로그래밍 과업을 스칼라로 처리하는 방법을 보여준다. 각각의 작동 이유를 자세히 설명하지는 않는다. 2장의 목표는 스칼라 코드를 직접 타이핑하고 실행하는 것이다.
3장, ‘스칼라 두 번째 걸음’에서는 스칼라에 더 빨리 적응할 수 있도록 기본 프로그래밍 과제를 좀 더 보여준다. 3장을 마치고 나면 간단한 스크립트 작업에 스칼라를 활용할 수 있을 것이다.
4장, ‘클래스와 객체’에서는 스칼라의 기본 객체지향 빌딩 블록을 자세히 설명하고, 스칼라 애플리케이션을 컴파일하고 실행하는 방법을 보여준다.
5장, ‘기본 타입과 연산’에서는 스칼라의 기본 타입과 그 리터럴을 설명한다. 그리고 각 타입에 사용할 수 있는 연산과 우선순위 및 결합 법칙을 설명한다. 마지막으로, 풍부한 래퍼(wrapper)에 대해 설명한다.
6장, ‘함수형 객체’에서는 스칼라의 객체지향적 측면을 더 깊이 파고든다. 변경 불가능한 함수형 유리수(functional rational number)를 예제로 사용한다.
7장, ‘내장 제어 구문’에서는 스칼라가 제공하는 제어 구조인 if, while, for, try, match를 어떻게 활용할 수 있는지 보여준다.
8장, ‘함수와 클로저’에서는 함수 언어의 기본 빌딩 블록인 함수에 대해 자세히 설명한다.
9장, ‘흐름 제어 추상화’에서는 스칼라가 어떻게 스스로 제어 추상화를 만들고 기본 제어 구조를 보완할 수 있는지 설명한다.
10장, ‘상속과 구성’에서는 스칼라가 객체지향 프로그래밍을 어떻게 지원하는지 논의한다. 다루는 주제는 4장만큼 기초적인 부분은 아니지만, 실무에서는 더 자주 부딪치는 부분이다.
11장, ‘스칼라의 계층구조’에서는 스칼라의 상속 계층을 설명하고, 모든 계층에서 사용할 수 있는 일반적인 메소드와 바닥(최하층) 타입에 대해 설명한다.
12장, ‘트레이트’에서는 스칼라의 믹스인(mixin) 조합의 메커니즘을 다룬다. 12장에서는 트레이트(trait)가 어떻게 작동하는지를 보여주고, 일반적인 용례를 설명하며, 트레이트가 전통적인 다중 상속을 어떻게 향상시킬 수 있는지 보여준다.
13장, ‘패키지와 임포트’에서는 대규모 프로그래밍에서 생기는 문제점을 논의한다. 최상위 패키지, 임포트 명령, protected나 private 같은 접근 제어 수식자 등에 대해 설명한다.
14장, ‘단언문과 단위 테스트’에서는 스칼라의 단언문(assert) 메커니즘을 다루고, 스칼라에서 사용할 수 있는 여러 테스트 도구를 간략히 살펴본다. 특히 스칼라 테스트(ScalaTest)에 초점을 맞춰 설명한다.
15장, ‘케이스 클래스와 패턴 매치’에서는 캡슐화하지 않은 일반적인 데이터 구조의 작성을 지원하는 구성요소 쌍을 소개한다. 특히 케이스 클래스(case class)와 패턴 매치(pattern match)는 트리 구조 같은 재귀적 데이터를 만들 때 유용하다.
16장, ‘리스트’에서는 스칼라 프로그램에서 가장 일반적으로 사용하는 데이터 구조인 리스트에 대해 자세히 설명한다.
17장, ‘컬렉션’에서는 리스트, 배열, 튜플(tuple), 집합(set), 맵(map) 같은 기본 스칼라 컬렉션 사용법을 보여준다.
18장, ‘상태가 있는 객체’에서는 상태가 있는(변경 가능한) 객체를 설명하고, 스칼라에서 이를 표현하는 방법을 배운다. 18장 뒷부분에서는 상태가 있는 객체를 실제로 활용하는 이산 이벤트 시뮬레이션(discrete event simulation)을 다룬다.
19장, ‘타입 파라미터화’에서는 13장에서 소개한 정보 은닉 기법의 일부를 구체적인 예를 들어 설명한다. 예제는 완전한 함수형인 큐 클래스를 만드는 것이다. 19장에서는 타입 파라미터의 변성(variance)에 대해 설명하고, 변성과 정보 은닉의 관계를 이야기한다.
20장, ‘추상 멤버’에서는 스칼라가 지원하는 모든 추상 멤버를 설명한다. 메소드뿐 아니라 필드나 타입도 추상 멤버로 정의할 수 있다.
21장, ‘암시적 변환과 암시적 파라미터’에서는 소스 코드에서 프로그래머가 지겨워할 수 있는 부분을 생략해도 컴파일러가 대신 필요한 내용을 채워 넣도록 돕는 두 가지 요소를 알려준다.
22장, ‘리스트 구현’에서는 List 클래스 구현을 설명한다. 스칼라 리스트가 어떻게 동작하는지 이해하는 일은 중요하다. 더 나아가 이 구현을 통해 스칼라의 특징 중 몇 가지를 활용하는 방법을 보여주기도 한다.
23장, ‘for 표현식 다시 보기’에서는 for 표현식을 map, flatMap, filter, foreach 등을 호출하는 명령으로 바꾸는 방법을 보여준다.
24장, ‘컬렉션 자세히 들여다보기’에서는 스칼라 컬렉션 라이브러리를 자세히 설명한다.
25장, ‘스칼라 컬렉션의 아키텍처’에서는 컬렉션 라이브러리를 어떻게 만들었는지 보여주고 컬렉션을 직접 구현하는 방법을 설명한다.
26장, ‘익스트랙터’에서는 케이스 클래스뿐 아니라, 임의의 클래스에 패턴 매치를 어떻게 할 수 있는지 보여준다.
27장, ‘애노테이션’에서는 애노테이션(annotation)을 통한 언어 확장을 사용하는 방법을 알려준다. 표준 애노테이션에 대해 설명하고, 직접 애노테이션을 만드는 방법도 알아본다.
28장, ‘XML 다루기’에서는 스칼라로 XML을 처리하는 방법을 설명한다. XML을 생성하고, 파싱하고, 파싱한 XML을 처리할 수 있는 여러 숙어를 보여준다.
29장, ‘객체를 사용한 모듈화 프로그래밍’에서는 스칼라의 객체를 모듈 시스템으로 활용하는 방법을 알려준다.
30장, ‘객체의 동일성’에서는 equals 메소드를 작성할 때 고려해야 할 사항을 설명한다. 피해야 할 함정이 몇 가지 있다.
31장, ‘스칼라와 자바의 결합’에서는 스칼라와 자바를 한 프로젝트에서 함께 사용할 경우 생기는 문제를 논의하고, 그 해결책을 제안한다.
목차
목차
- 1장. 확장 가능한 언어
- 1.1 여러분의 마음에서 점점 자라가는 언어
- 1.2 스칼라의 확장성이 가능한 이유
- 1.3 왜 스칼라인가
- 1.4 스칼라의 뿌리
- 1.5 결론
- 2장. 스칼라 첫걸음
- 2.1 1단계: 스칼라 인터프리터 사용법을 익히자
- 2.2 2단계: 변수를 정의해보자
- 2.3 3단계: 함수를 정의해보자
- 2.4 4단계: 스칼라 스크립트를 작성해보자
- 2.5 5단계: while로 루프를 돌고, if로 결정해보자
- 2.6 6단계: foreach와 for를 사용해 이터레이션해보자
- 2.7 결론
- 3장. 스칼라 두 번째 걸음
- 3.1 7단계: 배열에 타입 파라미터를 지정해보자
- 3.2 8단계: 리스트를 사용해보자
- 3.3 9단계: 튜플을 사용해보자
- 3.4 10단계: 집합과 맵을 써보자
- 3.5 11단계: 함수형 스타일을 인식하는 법을 배우자
- 3.6 12단계: 파일의 내용을 줄 단위로 읽자
- 3.7 결론
- 4장. 클래스와 객체
- 4.1 클래스, 필드, 메소드
- 4.2 세미콜론 추론
- 4.3 싱글톤 객체
- 4.4 스칼라 애플리케이션
- 4.5 App 트레이트
- 4.6 결론
- 5장. 기본 타입과 연산
- 5.1 기본 타입
- 5.2 리터럴
- 5.3 문자열 인터폴레이션
- 5.4 연산자는 메소드다
- 5.5 산술 연산
- 5.6 관계 연사과 논리 연산
- 5.7 비트 연산
- 5.8 객체 동일성
- 5.9 연산자 우선순위와 결합 법칙
- 5.10 풍부한 래퍼
- 5.11 결론
- 6장. 함수형 객체
- 6.1 분수 클래스 명세
- 6.2 Rational 생성
- 6.3 toString 메소드 다시 구현하기
- 6.4 선결 조건 확인
- 6.5 필드 추가
- 6.6 자기 참조
- 6.7 보조 생성자
- 6.8 비공개 필드와 메소드
- 6.9 연산자 정의
- 6.10 스칼라의 식별자
- 6.11 메소드 오버로딩
- 6.12 암시적 타입 변환
- 6.13 주의사항
- 6.14 결론
- 7장. 내장 제어 구문
- 7.1 if 표현식
- 7.2 while 루프
- 7.3 for 표현식
- 7.4 try 표현식으로 예외 다루기
- 7.5 match 표현식
- 7.6 break와 continue 문 없이 살기
- 7.7 변수 스코프
- 7.8 명령형 스타일 코드 리팩토링
- 7.9 결론
- 8장. 함수와 클로저
- 8.1 메소드
- 8.2 지역 함수
- 8.3 1급 계층 함수
- 8.4 간단한 형태의 함수 리터럴
- 8.5 위치 표시자 문법
- 8.6 부분 적용한 함수
- 8.7 클로저
- 8.8 특별한 형태의 함수 호출
- 8.9 꼬리 재귀
- 8.10 결론
- 9장. 흐름 제어 추상화
- 9.1 코드 중복 줄이기
- 9.2 클라이언트 코드 단순하게 만들기
- 9.3 커링
- 9.4 새로운 제어 구조 작성
- 9.5 이름에 의한 호출 파라미터
- 9.5 이름에 의한 호출 사용
- 9.6 결론
- 10장. 상속과 구성
- 10.1 2차원 레이아웃 라이브러리
- 10.2 추상 클래스
- 10.3 파라미터 없는 메소드 정의
- 10.4 클래스 확장
- 10.5 메소드와 필드 오버라이드
- 10.6 파라미터 필드 정의
- 10.7 슈퍼클래스의 생성자 호출
- 10.8 override 수식자 사용
- 10.9 다형성과 동적 바인딩
- 10.10 final 멤버 선언
- 10.11 상속과 구성 사용
- 10.12 above, beside, toString 구현
- 10.13 팩토리 객체 정의
- 10.14 높이와 너비 조절
- 10.15 한데 모아 시험해보기
- 10.16 결론
- 11장. 스칼라의 계층구조
- 11.1 스칼라의 클래스 계층구조
- 11.2 여러 기본 클래스를 어떻게 구현했는가
- 11.3 바닥에 있는 타입
- 11.4 자신만의 값 클래스 정의
- 11.5 결론
- 12장. 트레이트
- 12.1 트레이트의 동작 원리
- 12.2 간결한 인터페이스와 풍부한 인터페이스
- 12.3 예제: 직사각형 객체
- 12.4 Ordered 트레이트
- 12.5 트레이트를 이용해 변경 쌓아 올리기
- 12.6 왜 다중 상속은 안 되는가
- 12.7 트레이트냐 아니냐, 이것이 문제로다
- 12.8 결론
- 13장. 패키지와 임포트
- 13.1 패키지 안에 코드 작성하기
- 13.2 관련 코드에 간결하게 접근하기
- 13.3 임포트
- 13.4 암시적 임포트
- 13.5 접근 수식자
- 13.6 패키지 객체
- 13.7 결론
- 14장. 단언문과 테스트
- 14.1 단언문
- 14.2 스칼라에서 테스트하기
- 14.3 충분한 정보를 제공하는 실패 보고
- 14.4 명세로 테스트하기
- 14.5 프로퍼티 기반 테스트
- 14.6 테스트 조직과 실행
- 14.7 결론
- 15장. 케이스 클래스와 패턴 매치
- 15.1 간단한 예
- 15.2 패턴의 종류
- 15.3 패턴 가드
- 15.4 패턴 겹침
- 15.5 봉인된 클래스
- 15.6 Option 타입
- 15.7 7패턴은 어디에나
- 15.8 복잡한 예제
- 15.9 결론
- 16장. 리스트
- 16.1 리스트 리터럴
- 16.2 리스트 타입
- 16.3 리스트 생성
- 16.4 리스트 기본 연산
- 16.5 리스트 패턴
- 16.6 List 클래스의 1차 메소드
- 16.7 List 클래스의 고차 메소드
- 16.8 List 객체의 메소드
- 16.9 여러 리스트를 함께 처리하기
- 16.10 스칼라의 타입 추론 알고리즘 이해
- 16.11 결론
- 17장. 컬렉션
- 17.1 시퀀스
- 17.2 집합과 맵
- 17.3 변경 가능 컬랙션과 변경 불가능 컬렉션
- 17.4 컬렉션 초기화
- 17.5 튜플
- 17.6 결론
- 18장. 변경 가능한 객체
- 18.1 무엇이 객체를 변경 가능하게 하는가
- 18.2 재할당 가능한 변수와 속성
- 18.3 사례 연구: 이산 이벤트 시뮬레이션
- 18.4 디지털 회로를 위한 언어
- 18.5 시뮬레이션 API
- 18.6 회로 시뮬레이션
- 18.7 결론
- 19장. 타입 파라미터화
- 19.1 함수형 큐
- 19.2 정보 은닉
- 19.3 변성 표기
- 19.4 변성 표기 검사
- 19.5 하위 바운드
- 19.6 반공변성
- 19.7 객체의 비공개 데이터
- 19.8 상위 바운드
- 19.9 결론
- 20장. 추상 멤버
- 20.1 추상 멤버 간략하게 돌아보기
- 20.2 타입 멤버
- 20.3 추상 val 변수
- 20.4 추상 var
- 20.5 추상 val 초기화
- 20.6 추상 타입
- 20.7 경로에 의존하는 타입
- 20.8 세분화한 타입
- 20.9 열거형
- 20.10 사례 연구: 통화 변환
- 20.11 결론
- 21장. 암시적 변환과 암시적 파라미터
- 21.1 암시적 변환
- 21.2 암시 규칙
- 21.3 예상 타입으로의 암시적 변환
- 21.4 호출 대상 객체 변환
- 21.5 암시적 파라미터
- 21.6 맥락 바운드
- 21.7 여러 변환을 사용하는 경우
- 21.8 암시 디버깅
- 21.9 결론
- 22장. 리스트 구현
- 22.1 List 클래스 개괄
- 22.2 ListBuffer 클래스
- 22.3 실제 List 클래스
- 22.4 외부에서 볼 때는 함수형
- 22.5 결론
- 23장. For 표현식 다시 보기
- 23.1 for 표현식
- 23.2 n 여왕 문제
- 23.3 for 식으로 질의하기
- 23.4 for 표현식 변환
- 23.5 역방향 적용
- 23.6 for 일반화
- 23.7 결론
- 24장. 컬렉션 자세히 들여다보기
- 24.1 변경 가능, 변경 불가능 컬렉션
- 24.2 컬렉션 일관성
- 24.3 Traversable 트레이트
- 24.4 Iterable 트레이트
- 24.5 시퀀스 트레이트: Seq, IndexedSeq, LinearSeq
- 24.6 집합
- 24.7 맵
- 24.8 변경 불가능한 구체적인 컬렉션 클래스
- 24.9 변경 가능한 구체적인 컬렉션 클래스
- 24.10 배열
- 24.11 문자열
- 24.12 성능 특성
- 24.13 동일성
- 24.14 뷰
- 24.15 이터레이터
- 24.16 컬렉션 처음 만들기
- 24.17 자바와 스칼라 컬렉션 변환
- 24.18 결론
- 25장. 스칼라 컬렉션의 아키텍처
- 25.1 빌더
- 25.2 공통 연산 한데 묶기
- 25.3 새 컬렉션 통합
- 25.4 결론
- 26장. 익스트랙터
- 26.1 예제: 전자우편 주소 추출
- 26.2 익스트랙터
- 26.3 변수가 없거나 1개만 있는 패턴
- 26.4 가변 인자 익스트랙터
- 26.5 익스트랙터와 시퀀스 패턴
- 26.6 익스트랙터와 케이스 클래스
- 26.7 정규표현식
- 26.8 결론
- 27장. 애노테이션
- 27.1 애노테이션이 왜 필요한가
- 27.2 애노테이션 문법
- 27.3 표준 애노테이션
- 27.4 결론
- 28장. XML 다루기
- 28.1 반 구조화 데이터
- 28.2 XML 개요
- 28.3 XML 리터럴
- 28.4 직렬화
- 28.5 XML 분석
- 28.6 역 직렬화
- 28.7 저장하기와 불러오기
- 28.8 XML에 대한 패턴 매치
- 28.9 결론
- 29장. 객체를 사용한 모듈화 프로그래밍
- 29.1 문제
- 29.2 조리법 애플리케이션
- 29.3 추상화
- 29.4 모듈을 트레이트로 분리하기
- 29.5 실행 시점 링킹
- 29.6 모듈 인스턴스 추적
- 29.7 결론
- 30장. 객체의 동일성
- 30.1 스칼라에서의 동일성
- 30.2 동일성 비교 메소드 작성
- 30.3 파라미터화한 타입의 동일성 정의
- 30.4 equals와 hashCode 요리법
- 30.5 결론
- 31장. 스칼라와 자바의 결합
- 31.1 스칼라를 자바에서 사용하기
- 31.2 애노테이션
- 31.3 와일드카드 타입
- 31.4 스칼라와 자바를 함께 컴파일하기
- 31.5 자바 8과 스칼라 2.12의 통합
- 31.6 결론
- 32장. 퓨처와 동시성
- 32.1 낙원의 골칫거리
- 32.2 비동기 실행과 Try
- 32.3 Future의 사용
- 32.4 Future 테스트
- 32.5 결론
- 33장. 콤비네이터 파싱
- 33.1 예제: 산술식
- 33.2 파서 실행
- 33.3 기본 정규표현식 파서
- 33.4 또 다른 예: JSON
- 33.5 파서의 결과
- 33.6 콤비네이터 파서 구현
- 33.7 문자열 리터럴과 정규표현식
- 33.8 어휘분석과 파싱
- 33.9 오류 보고
- 33.10 백트래킹과 LL(1)
- 33.11 결론
- 34장. GUI 프로그래밍
- 34.1 첫 번째 스윙 애플리케이션
- 34.2 패널과 레이아웃
- 34.3 이벤트 처리
- 34.4 예제: 섭씨/화씨 변환기
- 34.5 결론
- 35장. SCells 스프레드시트
- 35.1 화면 프레임워크
- 35.2 데이터 입력과 화면 표시 분리하기
- 35.3 식
- 35.4 식의 파싱
- 35.5 계산
- 35.6 연산 라이브러리
- 35.7 변경 전파
도서 오류 신고
정오표
정오표
[p.83 : 하단 참고 1행]
표현식에서 :: 는 왼쪽에 있는
->
표현식에서 :: 는 오른쪽에 있는
[p.139 : 변경 불가능한 객체의 장단점 비교 상자 1행]
첫째, 변경 가능한 객체는
->
첫째, 변경 불가능한 객체는
[p.205 : 13행]
변수 funcValue는
->
변수 funValue는
[p.335 : 3행]
case Some => s
->
case Some(s) => s
[p.336 : 15행]
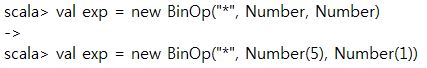
[p.506 : 리스트 21.4의 2행]
Ordered[T]
->
Ordering[T]
[p.508 : 본문 2행]
Ordered[T]
->
Ordering[T]
[p.508 : 본문 2행]
T가 Ordered[T]
->
T가 Ordering[T]