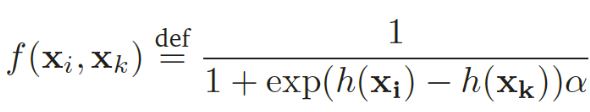책 소개
요약
머신 러닝에 관련된 기초 수학 정의와 선형 회귀, 로지스틱 회귀, SVM을 기초 신경망부터 CNN, RNN에 이르는 주제를 담은 책으로, 1960년대의 초창기 기술부터 지금까지 나온 머신 러닝 기법 중에서 실전에서 유용하면서 머신 러닝 입문자가 기초를 다지는 데 딱 필요한 만큼 설명하는 책이다.
프로젝트 초반에 주어지는 문제를 머신 러닝으로 해결할 수 있는지 알아보고, 어떤 기법을 적용해야 하는지 판단하는 데 필요한 지식을 제시한다.
이 책에 쏟아진 찬사
“저자는 머신 러닝에 관한 내용을 100페이지에 담아내는, 굉장히 유용하면서도 불가능에 가까울 정도로 힘든 작업을 했다. 이론뿐만 아니라 실전 기법 측면에서 현업 종사자에게 꼭 필요한 주제만으로 잘 구성했으며, 머신 러닝 서적 중에서 거의 유일한 100페이지(원서 기준)짜리 책이라는 것을 이해하는 독자라면 이 책을 통해 기초를 탄탄하게 다질 수 있다.”
ㅡ 피터 노빅(Peter Norvig)/
구글 리서치 디렉터이자 전 세계에서 가장 인기 있는 인공지능 교과서인 『Artificial Intelligence: A Modern Approach』의 저자
“이 책이 다루는 다양한 주제를 단 100페이지(+α)에 담았다니 굉장히 놀랍다. 부르코프는 수식도 거침없이 소개하는데, 머신 러닝을 간략하게 소개하는 책에서는 거의 찾아볼 수 없는 이 점이 이 책의 매력이다. 개인적으로 핵심 개념을 단 몇 마디로 정리하는 설명 방식이 매우 마음에 든다. 이 책은 머신 러닝에 입문하는 사람만이 아니라 어느 정도 익숙한 이들에게도 이 분야의 다양한 주제를 접할 수 있다는 점에서 큰 도움이 될 것이다.”
ㅡ 오렐리앙 제롱(Aurélien Géron)/ 시니어 AI 엔지니어이자 아마존 베스트셀러인 『Hands-On Machine Learning with Scikit-Learn and TensorFlow』의 저자
“세계 최고의 전문 엔지니어가 소개하는 뛰어난 머신 러닝 입문서다.”
ㅡ 카롤리스 우르보나스/ 아마존 데이터 사이언스 부서장
“대학원에서 통계학을 전공하면서 머신 러닝을 배우려 할 때 있었으면 좋았을 책이다.”
ㅡ 차오 한/ 루시드웍스 R&D 부서장, VP
“안드리는 자잘한 내용을 잘라내고 첫 페이지부터 본론으로 들어가는 식으로 이 책을 정말 잘 구성해냈다.”
ㅡ 수짓 바라크헤디/ 이베이 엔지니어링 부서장
“엄청난 시간을 투자하지 않고도 일상 업무에 머신 러닝을 적용하려는 엔지니어를 위한 훌륭한 책”
ㅡ 디팍 아가왈/ 링크드인 AI 담당 VP
“머신 러닝을 처음 배우기에 좋은 책”
ㅡ 빈센트 폴렛/ 뉘앙스 연구 부서장
추천의 글
최근 20년 사이에 우리가 다룰 수 있는 데이터의 양은 폭발적으로 늘어났으며, 이에 따라 통계학과 머신 러닝 응용에 대한 관심도 덩달아 급증했다. 그 파급 효과는 상당하다. 10년 전, 내가 선택 과목인 통계 학습을 개설할 때 MBA 과정의 모든 학생이 강의실을 가득 채울 정도로 인기가 많아서 동료 교수들이 깜짝 놀랄 정도였다(당시 개설된 선택 과목 중 대부분은 수강생 채우기에 급급했기 때문이다). 현재는 ‘비즈니스 애널리틱스(Business Analytics)’라는 석사 과정을 제공하고 있는데, 이 과정은 우리 학교의 특화된 석사 과정 중에서도 가장 규모가 크며, 지원자 수는 MBA 과정 지원자 수에 맞먹을 정도다. 그동안 이 과정의 과목 수가 많이 늘어났음에도 모든 수업마다 수강생이 가득 차서 불만이라는 의견은 여전히 나오고 있다. 이는 우리 학교에서만 볼 수 있는 현상이 아니다. 데이터 사이언스와 머신 러닝 전공자에 대한 수요가 늘어나면서 이 분야의 학위 과정이 급속도로 늘고 있다.
이렇게 수요가 급증하는 배경에는 단순하지만 불가피한 한 가지 사실이 있다. 바로 머신 러닝 기법은 사회 과학, 경영학, 생물학, 의학을 비롯한 수많은 분야에서 기존과는 상당히 다른 접근 방식을 제공한다는 것이다. 그로 인해 머신 러닝을 배경으로 하는 전문가의 수요가 엄청나게 늘어났다. 그런데 이러한 기술을 학생에게 가르치기는 쉽지 않다. 기존에 나온 자료들은 대부분 실전과는 동떨어진 이론 위주인 데다, 오래전 통계학에서 다루던 피팅(fitting) 알고리즘과 이에 기반한 예측기만 다루기 때문이다. 정작 현실에서 마주치는 문제를 풀기 위해 다양한 기법을 구현해야 하는 연구원이나 엔지니어들에게 도움이 되는 자료는 드물다. 이들은 주어진 문제에 적합한 기법을 선정할 수 있도록 다양한 기법의 가정과 장단점을 파악해야 한다. 하지만 피팅 알고리즘에 관한 이론적 배경이나 세부 사항은 이러한 요구 사항과 다소 거리가 있다. 내가 『ISLR(An Introduction to Statistical Learning: with Applications in R)』을 집필한 동기는 바로 이들을 위한 자료를 제공하기 위해서였다. 이 책에 대한 열광적인 호응만 봐도 실제로 그런 독자층이 적지 않다는 사실을 입증한다.
안드리 부르코프의 책도 성격이 비슷하다. 『ISLR』과 마찬가지로, 이론에 관한 세부 사항은 가볍게 넘기고 다양한 기법을 구현하는 데 필요한 핵심만 전달하고 있다. 이 책은 ‘데이터 사이언스를 위한' 간략한 매뉴얼 같다. 예상컨대 학교에서뿐만 아니라 실전에서도 반드시 참고할 만한 필독서로 자리매김할 것이다. 100페이지(실제로는 이보다 살짝 많은) 분량으로 구성돼 있어서 단숨에 읽기에도 충분하다. 분량은 적지만, 고전 선형 회귀와 로지스틱 회귀부터 SVM과 딥러닝, 부스팅, 랜덤 포레스트와 같은 최신 주제까지 머신 러닝의 핵심 주제를 거의 모두 망라해 다룬다. 각각의 주제는 결코 부족하지 않은 수준으로 설명하고 있으며, 더 깊이 알고 싶은 독자를 위해 이 책의 위키 사이트에 관련 자료도 제공하고 있다. 고급 수학과 통계 이론을 알아야만 이 책을 읽을 수 있는 것은 아니며, 심지어 프로그래밍 경험이 없어도 된다. 따라서 머신 러닝 기법을 알고 싶은 사람이라면 누구나 이 책을 읽을 수 있다. 머신 러닝 박사 과정을 시작하는 사람이라면 반드시 이 책을 읽어야 한다. 숙련된 독자도 레퍼런스처럼 활용하기에 좋다. 또한 이 책은 몇 가지 알고리즘에 대해 파이썬 코드도 함께 제공한다(파이썬은 현재 머신 러닝 분야에서 가장 인기 있는 프로그래밍 언어다). 나는 머신 러닝을 본격적으로 배우고 싶은 입문자뿐만 아니라, 어느 정도 머신 러닝에 대한 경험이 있으면서 실력을 쌓으려는 전문가에게도 이 책을 강력히 추천한다.
ㅡ 가레스 제임스(Gareth James) /USC(서던캘리포니아 대학) 데이터 사이언스 및 오퍼레이션학과 교수 베스트셀러 『An Introduction to Statistical Learning: with Applications in R』의 공저자
개인적으로 지난 수년 간 설명해 온 말이며, 내 저서 제목처럼 “인공지능이란 없다(Artificial Intelligence does not exist).” 최소한 지난 10년 동안 들어왔던 ‘우리 대신 생각해주는 기계’는 순전히 할리우드식 판타지이자, 가장 비이성적인 공포라고 볼 수 있다. 기계는 우리가 학습하라고 제시한 것 외에는 학습하지 않는다. 생각하지도 않고, 숙고하지도 않는다. 르네 데카르트가 1637년에 한 말인 “생각한다. 고로 나는 존재한다(Cogito, ergo sum).”에 따르면 생각해야 존재할 수 있는 것이다. 따라서 기계는 존재하지 않는다.
태곳적부터 우리는 일상생활에 필요한 작업을 하거나 문제 해결을 도와줄 기계나 로봇을 만들고자 노력해왔으며, 이런 기계나 로봇이 우리처럼 행동하거나 문제를 풀도록 가르쳤다. 그러다가 1950년대 후반에 들어서 인공지능과 머신 러닝이란 단어가 ‘뉴런을 수학적으로 모델링한 것’이라는 의미로 등장하면서부터 상황은 급변하기 시작했다. 용어에는 오해의 소지가 다분했지만 분야 자체는 상당히 흥미로웠다. 특히 빅데이터 시대가 도래하면서 아직 초기 단계에 불과하기는 하지만 머신 러닝은 뛰어난 도구를 개발하는 데 공헌했다.
따라서 머신 러닝은 실제로 존재하고 응용 분야는 나날이 확장되고 있으며, 이러한 도구들, 즉 우리를 도와주는 ‘비서들’은 가까운 미래에 더욱 다양하게 등장할 것이다. 머신 러닝의 응용 분야는 지금도 활발히 적용되고 있는 이미지 분야부터 헬스케어와 DNA 연구에 이르기까지 다양하게 확장하고 있다. 특히 DNA 연구에서 머신 러닝은 유전자의 기능 조합을 분석하기 위한 다양한 방법을 제시했다. 머신 러닝은 운송 영역에도 적용돼 인식과 계획 관련 기술을 좀 더 정교하게 발전시켜서 매일 출퇴근하는 동안 안전하고 안락한 교통 수단을 제공해줄 수도 있고, 기발한 방식으로 개체들을 연결해 일상생활을 윤택하게 만들어줄 것이다.
머신 러닝이 인간의 삶에 갑자기 들이닥치면서 우리 모두 머신 러닝에 어떤 식으로든 관심을 가질 수밖에 없게 됐다. 그중 일부는 머신 러닝의 작동 원리만큼은 확실하게 이해해야 한다. 또 어떤 이들은 가장 적합한 알고리즘을 선택하고 시스템을 배치하는 단계에서 치명적인 편향이 발생하지 않도록 데이터셋을 올바르게 정의하고, 만들고, 고를 수 있을 정도로 다양한 머신 러닝 기법을 깊이 있게 이해해야 한다. 그 외의 사람들도 최소한 머신 러닝 기술의 한계와 잠재적인 위험을 잘 파악해서 차분한 마음으로 활용할 수 있어야 한다.
안드리 부르코프의 책에서는 바로 이러한 것들을 설명하고 있다. 복잡한 수학 이론에서 헤매지 않고 꼭 필요한 기초만 강조함으로써, 고전 통계 기법부터 최신 딥러닝 기법에 이르기까지 머신 러닝이 제공하는 다양한 기법을 빠르게 습득할 수 있다. 이 책은 사람들이 헷갈리기 쉬운 개념과 용어들을 명확하고 간결하고 논리적으로 정리해준다. 나아가 실전에서 알고리즘을 효과적으로 구현할 수 있도록 파이썬 코드 예제도 제시하고 있다.
입문자부터 실력 있는 전문가에 이르기까지 다양한 독자가 이 책을 레퍼런스로 삼아 머신 러닝의 모든 측면을 확실히 이해하고 마스터할 수 있을 것이다.
ㅡ 뤽 줄리아 박사(Dr. Luc JULIA)
/삼성 이노베이션 CTO & SVP
베스트셀러 『L'intelligence artificielle n'existe pas』의 저자
이 책의 대상 독자
이 책은 1960년대부터 지금까지 개발된 머신 러닝에 관련된 기술 중에서도 활용 가치가 높다고 증명된 것만 소개한다. 머신 러닝을 처음 배우는 독자들은 이 책에 나온 내용만 잘 익혀도 이 분야를 이해하고 질문을 제대로 던질 수 있게 된다.
머신 러닝에 대한 경험을 어느 정도 갖춘 현업 엔지니어는 이 책에 나온 내용을 가이드로 삼아서 실력을 더욱 향상시킬 수 있다. 이 책은 또한 프로젝트 초반에 브레인스토밍을 하는 데도 유용하다. 특히 프로젝트에서 해결해야 할 비즈니스적인 문제나 기술적인 문제에 ‘머신 러닝’을 적용할 수 있는지, 만약 그렇다면 어떤 기법을 적용해야 하는지를 파악하는 데 도움이 된다.
이 책의 활용 방법
머신 러닝을 처음 학습하는 독자는 반드시 처음부터 끝까지 빠짐없이 모두 읽길 바란다. 그중 특정한 주제에 대해 깊이 알고 싶다면, 각 절에 나온 QR 코드를 따라가보길 바란다.
QR 코드 페이지에는 참고 문헌, 비디오, Q&A, 코드 예제, 튜토리얼을 비롯한 다양한 자료가 있다. 이 내용은 저자를 비롯한 전 세계 독자들이 꾸준히 업데이트한다.
상세 이미지

목차
목차
- 1장. 개요
- 1.1 머신 러닝이란
- 1.2 학습 유형
- 1.2.1 지도 학습
- 1.2.2 비지도 학습
- 1.2.3 준지도 학습
- 1.2.4 강화 학습
- 1.3 지도 학습의 원리
- 1.4 훈련 데이터로 만든 모델이 처음 보는 데이터에 대해서도 효과적인 이유
- 2장. 수학 정의와 표기법
- 2.1 표기법
- 2.1.1 데이터 구조
- 2.1.2 대문자 시그마 기호
- 2.1.3 대문자 파이 기호
- 2.1.4 집합 연산
- 2.1.5 벡터 연산
- 2.1.6 함수
- 2.1.7 max와 min, arg max와 arg min 연산
- 2.1.8 대입 연산자
- 2.1.9 도함수와 기울기
- 2.2 확률 변수
- 2.3 비편향 추정량
- 2.4 베이즈 규칙
- 2.5 파라미터 추정
- 2.6 파라미터 vs. 하이퍼파라미터
- 2.7 분류 vs. 회귀
- 2.8 모델 기반 학습 vs. 사례 기반 학습
- 2.9 표층 학습 vs. 심층 학습
- 3장. 기본 알고리즘
- 3.1 선형 회귀
- 3.1.1 문제 정의
- 3.1.2 해결 방법
- 3.2 로지스틱 회귀
- 3.2.1 문제 정의
- 3.2.2 해결 방법
- 3.3 결정 트리 학습
- 3.3.1 문제 정의
- 3.3.2 해결 방법
- 3.4 SVM
- 3.4.1 노이즈를 다루는 방법
- 3.4.2 본질적으로 비선형적인 경우에 대처하는 방법
- 3.5 kNN
- 4장. 학습 알고리즘 심층 분석
- 4.1 학습 알고리즘의 기본 구성 요소
- 4.2 경사 감소법
- 4.3 머신 러닝 엔지니어의 작업 방식
- 4.4 학습 알고리즘에서 주의할 점
- 5장. 핵심 기법
- 5.1 특징 공학
- 5.1.1 원핫 인코딩
- 5.1.2 비닝
- 5.1.3 정규화
- 5.1.4 표준화
- 5.1.5 결측값 처리 방법
- 5.1.6 데이터 대체 기법
- 5.2 학습 알고리즘 결정하기
- 5.3 세 가지 집합
- 5.4 언더피팅과 오버피팅
- 5.5 규제화
- 5.6 모델 성능 평가 방법
- 5.6.1 혼동 행렬
- 5.6.2 정밀도와 재현율
- 5.6.3 정확도
- 5.6.4 비용 민감 정확도
- 5.6.5 AUC
- 5.7 하이퍼파라미터 튜닝
- 5.7.1 교차 검증
- 6장. 신경망과 딥러닝
- 6.1 신경망
- 6.1.1 다계층 퍼셉트론의 예
- 6.1.2 피드포워드 신경망 구조
- 6.2 딥러닝
- 6.2.1 CNN
- 6.2.2 RNN
- 7장. 문제와 해결 방법
- 7.1 커널 회귀
- 7.2 다중 클래스 분류
- 7.3 단일 클래스 분류
- 7.4 다중 레이블 분류
- 7.5 앙상블 학습
- 7.5.1 부스팅과 배깅
- 7.5.2 랜덤 포레스트
- 7.5.3 그래디언트 부스팅
- 7.6 레이블 시퀀스 학습
- 7.7 시퀀스-투-시퀀스 학습
- 7.8 액티브 러닝
- 7.9 준지도 학습
- 7.10 원샷 러닝
- 7.11 제로샷 러닝
- 8장. 고급 기법
- 8.1 불균형 데이터셋 처리하기
- 8.2 모델 조합하기
- 8.3 신경망 학습시키기
- 8.4 고급 규제화
- 8.5 다중 입력 처리하기
- 8.6 다중 출력 처리하기
- 8.7 전이 학습
- 8.8 알고리즘 효율
- 9장. 비지도 학습
- 9.1 밀도 추정
- 9.2 군집화
- 9.2.1 K-평균
- 9.2.2 DBSCAN과 HDBSCAN
- 9.2.3 군집 개수 결정하기
- 9.2.4 다른 군집화 알고리즘
- 9.3 차원 축소
- 9.3.1 PCA
- 9.3.2 UMAP
- 9.4 아웃라이어 탐지
- 10장. 그 밖에 다양한 학습 기법
- 10.1 메트릭 학습
- 10.2 랭킹 학습
- 10.3 추천 학습
- 10.3.1 FM
- 10.3.2 DAE
- 10.4 자가 지도 학습: 단어 임베딩
- 11장. 결론
- 11.1 이 책에서 다루지 않은 내용
- 11.1.1 토픽 모델링
- 11.1.2 가우시안 프로세스
- 11.1.3 일반화 선형 모델
- 11.1.4 확률 그래픽 모델
- 11.1.5 마르코프 체인 몬테 카를로
- 11.1.6 GAN
- 11.1.7 유전 알고리즘
- 11.1.8 강화 학습
- 11.2 감사의 글
도서 오류 신고
정오표
정오표
[p.86 : 수식]
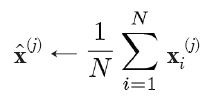
->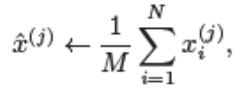
[p.86 : 아래서 10행 첫 시작 내용 추가]
여기서 M은 특징 j의 값이 존재하는 예제의 갯수로서 N보다 작고, x_i의 합을 구할 때는 특징 j의 값이 없는 예제는 제외한다.
[p.122 : 아래서 4행]
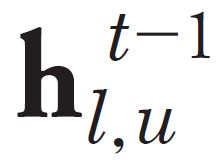
->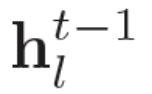
[p.124 : 3행 -1]
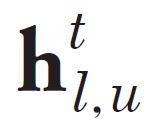
->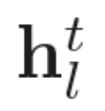
[p.124 : 3행-2]
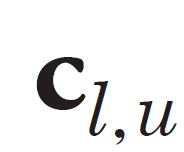
->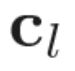
[p.124 : 4문단 1행]
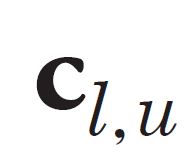
->
[p.141 : 아래서 1행]
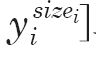
->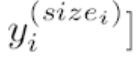
[p.141 : 아래서 2행-1]
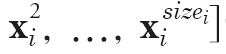
->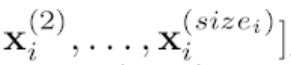
[p.141 : 아래서 2행-2]
->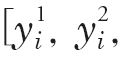
[p.141 : 아래서 3행]
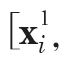
->
[p.194 : 수식]
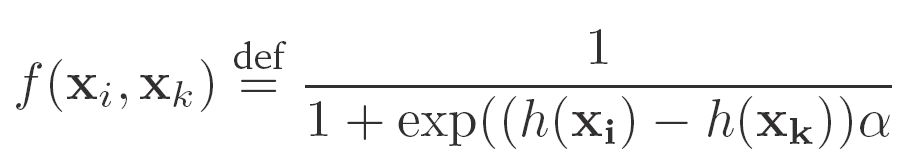
->