


추천 엔진을 구축하기 위한 기본서 [R, 파이썬, 스파크, 머하웃, Neo4j를 이용해 추천 엔진 구축 시작하기]
- 원서명Building Recommendation Engines (ISBN 9781785884856)
- 지은이수레시 고라칼라(Suresh K. Gorakala)
- 옮긴이테크 트랜스 그룹 T4
- ISBN : 9791161750460
- 33,000원
- 2017년 09월 06일 펴냄 (절판)
- 페이퍼백 | 424쪽 | 188*235mm
- 시리즈 : acorn+PACKT
판매처
- 현재 이 도서는 구매할 수 없습니다.
책 소개
소스 코드 파일은 여기에서 내려 받으실 수 있습니다.
본문에 쓰인 컬러 이미지는 여기에서 내려 받으세요.
요약
R, 파이썬(Python), 스파크(Spark), 머하웃(Mahout), Neo4j 기술을 이용하여 협업 필터링, 컨텐츠 기반 추천 엔진, 상황 인지 추천 엔진과 같은 추천 엔진을 구현하는 가이드를 제공한다. 산업계에서 광범위하게 사용되는 다양한 추천 엔진들을 다루기 때문에 실무에 있어서 기본 내용들을 한눈에 파악할 수 있다. 추천 시스템을 구축할 때 일상적으로 사용되는 유명한 데이터 마이닝 기술을 파악할 수 있으며, 추천 엔진의 미래에 대해서 설명하기 때문에 추천 엔진에 대해서 많은 인사이트를 얻을 수 있도록 돕는다.
이 책에서 다루는 내용
■ 첫 번째 추천 엔진 구축 방법
■ 추천 엔진을 구축하는 데 필요한 도구
■ 공동 작업, 콘텐츠 기반 및 교차 추천과 같은 추천 시스템의 다양한 기법
■ 업무를 쉽게 할 수 있는 효율적인 의사 결정 시스템
■ 다양한 프레임워크에서의 머신 러닝 알고리즘
■ 실제 코드 예제를 사용한 다양한 버전의 추천 엔진 마스터링
■ 다양한 추천 시스템의 탐색과 R, 파이썬, 스파크 등의 기술을 이용하는 구현 방법
이 책의 대상 독자
이 책은 R, 파이썬, 스파크, Neo4j, 하둡을 사용한 추천 엔진과 복잡한 예측 의사 결정 시스템을 이해하고 구축하려는 초보자나 관련 경험이 있는 데이터 과학자를 대상으로 한다.
이 책의 구성
1장. '추천 엔진 소개'에서는 데이터 과학자들에게 추천 기능에 대해 다시 설명하고, 초보자들을 위해 추천 엔진을 다룬다. 그리고 사람들이 일상생활에서 사용하는 인기 있는 추천 엔진을 소개하고 인기 있는 추천 엔진의 장점과 단점을 살펴본다.
2장. '첫 번째 추천 엔진 구축하기'에서는 추천 엔진의 세계로 떠나기 전에 영화 추천 엔진을 어떻게 만드는지 간단히 살펴본다.
3장. '추천 엔진 이해'에서는 사용자 기반 협업 필터링 추천 엔진, 항목 기반 협업 필터링, 콘텐츠 기반 추천 엔진, 컨텍스트 기반 추천인(recommender), 하이브리드 추천인, 머신 러닝 모델 및 수학 모델과 같은 모델 기반 추천인 시스템 등 널리 사용되는 다양한 권장 엔진 기술을 설명한다.
4장. '추천 엔진에서 사용되는 데이터 마이닝 기법'에서는 유사성 측정, 분류, 회귀, 차원 축소 기술과 같은 추천 엔진 구축에서 사용되는 다양한 머신 러닝 기술을 다룬다. 추천 엔진의 예측 성능을 테스트하는 평가 측정 항목도 설명한다.
5장. '협업 필터링 추천 엔진 구축하기'에서는 R과 파이썬에서 사용자 기반 협업 필터링과 항목 기반 협업 필터링을 작성하는 방법을 다룬다. 또한 R과 파이썬에서 사용할 수 있는 다양한 라이브러리도 살펴본다. 이 라이브러리는 추천 엔진 구축 시에 광범위하게 사용된다.
6장. '개인화 추천 엔진 구축하기'에서는 R과 파이썬, 그리고 콘텐츠 기반 추천 시스템 및 상황 인식 권장 엔진을 작성하는 데 사용되는 다양한 라이브러리를 사용해 개인화 추천 엔진을 만드는 방법을 설명한다.
7장. '스파크를 사용해 실시간 추천 엔진 구축하기'에서는 실시간 추천 시스템을 구축하는 데 필요한 스파크 및 MLlib의 기본에 대해 설명한다.
8장. 'Neo4j로 실시간 추천 엔진 구축하기'에서는 graphDB와 Neo4j의 기본 개념을 살펴보고 Neo4j를 사용해 실시간 추천 시스템을 구축하는 방법을 설명한다.
9장. '머하웃을 이용한 추천 엔진 구축하기'에서는 확장 가능한 추천 시스템을 구축하는 데 필요한 하둡과 머하웃의 기본 빌딩 블록에 대한 내용을 다룬다. 또한 머하웃과 SVD를 사용해 확장 가능한 시스템을 구축하고, 단계별로 구현하는 데 필요한 아키텍처 관련 내용도 다룬다.
10장. '추천 엔진의 미래: 다음은 무엇일까?'에서는 이전까지 배운 내용을 요약해 설명한다. 그리고 의사 결정 시스템 구축에 사용되는 사례와 추천 시스템의 미래 모습도 살펴본다.
목차
목차
- 1장. 추천 엔진 소개
- 추천 엔진 정의
- 추천 시스템의 필요성
- 추천 시스템을 운영하는 빅데이터
- 추천 시스템 종류
- 협업 필터링 추천 시스템
- 콘텐츠 기반 추천 시스템
- 하이브리드 추천 시스템
- 상황 인식 추천 시스템
- 기술 발전에 따른 추천 시스템의 발전
- 확장 가능한 추천 시스템을 위한 머하웃
- 실시간 확장 가능 추천 시스템을 위한 아파치 스파크
- 실시간 그래프 기반 추천 시스템을 위한 Neo4j
- 요약
- 2장. 첫 번째 추천 엔진 구축하기
- 기본 추천 엔진 구축하기
- 데이터 로드 및 형식 변환
- 사용자 사이의 유사도 계산
- 사용자의 등급 예측
- 요약
- 기본 추천 엔진 구축하기
- 3장. 추천 엔진 이해
- 추천 엔진의 진화
- 최근접 이웃 기반 추천 엔진
- 사용자 기반 협업 필터링
- 아이템 기반 협업 필터링
- 장점
- 단점
- 콘텐츠 기반 추천 시스템
- 아이템 프로필 생성
- 사용자 프로필 생성
- 장점
- 단점
- 상황 인식 추천 시스템
- 상황의 정의
- 사전 필터링 방식
- 사후 필터링 방식
- 장점
- 단점
- 하이브리드 추천 시스템
- 가중 방식
- 혼합 방식
- 캐스케이드 방식
- 특징 조합 방식
- 장점
- 모델 기반 추천 시스템
- 확률적 접근법
- 머신 러닝 접근법
- 수학적 접근법
- 장점
- 요약
- 4장. 추천 엔진에서 사용되는 데이터 마이닝 기법
- 이웃 기반 기법
- 유클리드 거리
- 코사인 유사도
- 자카드 유사도
- 피어슨 상관계수
- 수학적 모델 기법
- 행렬 인수 분해
- 교대 최소 제곱
- 특이값 분해
- 머신 러닝 기법
- 선형 회귀
- 분류 모델
- 선형 분류
- KNN 분류
- 서포트 벡터 머신
- 결정 트리
- 앙상블 방법
- 클러스터링 기법
- K-평균 클러스터링
- 차원 축소
- 주성분 분석
- 벡터 공간 모델
- 단어 빈도
- 단어 빈도-역문서 빈도
- 평가 기법
- 교차 검증
- 정규화
- 평균 제곱근 오차
- 평균 절대 오차
- 정확도와 재현율
- 요약
- 이웃 기반 기법
- 5장. 협업 필터링 추천 엔진 구축하기
- RStudio에 recommenderlab 패키지 설치하기
- recommenderlab 패키지에서 사용 가능한 데이터 세트
- Jester5K 데이터 세트 탐색
- 설명
- 사용법
- 형식
- 상세 설명
- Jester5K 데이터 세트 탐색
- 데이터 세트 탐색하기
- 평가 값 탐색하기
- recommenderlab으로 사용자 기반의 협업 필터링 구축하기
- 훈련 데이터와 테스트 데이터 준비하기
- 사용자 기반 협업 모델 생성하기
- 테스트 세트에서의 예측
- 데이터 세트 분석하기
- k-교차 검증을 통한 추천 모델 평가하기
- 사용자 기반 협업 필터링 평가하기
- 아이템 기반 추천인 모델 구축하기
- IBCF 추천인 모델 구축하기
- 모델 평가
- 메트릭을 사용한 모델 정확도
- 플롯을 사용한 모델 정확도
- IBCF의 매개변수 튜닝하기
- 파이썬을 사용한 협업 필터링
- 필요한 패키지 설치하기
- 데이터 소스
- 데이터 탐사
- 평가 행렬 표현
- 훈련과 테스트 세트 생성하기
- UBCF를 구축하는 단계
- 사용자 기반 유사도 계산
- 활성 사용자의 알려지지 않은 평가 예측하기
- k-최접 이웃과의 사용자 기반 협업 필터링
- 최접 N 이웃 찾기
- 아이템 기반 추천
- 모델 평가하기
- k-최접 이웃에 대한 훈련 모델
- 모델 평가하기
- 요약
- 6장. 개인화 추천 엔진 구축하기
- 개인화 추천인 시스템
- 콘텐츠 기반 추천인 시스템
- 콘텐츠 기반 추천 시스템 구축하기
- R을 사용한 콘텐츠 기반 추천
- 데이터 세트 설명
- 파이썬을 사용한 콘텐츠 기반 추천
- 데이터 세트 설명
- 사용자 활동
- 아이템 프로필 생성
- 사용자 프로필 생성
- 상황 인식 추천인 시스템
- 상황 인식 추천인 시스템 구축하기
- R을 사용한 상황 인식 추천
- 상황 정의하기
- 상황 프로필 생성하기
- 상황 인식 추천 생성하기
- 요약
- 7장. 스파크를 사용해 실시간 추천 엔진 구축하기
- 스파크 2.0
- 스파크 아키텍처
- 스파크 구성 요소
- 스파크 코어
- 스파크 SQL을 이용한 구조화된 데이터
- 스파크 스트리밍을 사용하는 스트리밍 분석
- MLlib를 사용하는 머신 러닝
- GraphX를 사용한 그래픽 계산
- 스파크의 장점
- 스파크 셋업하기
- SparkSession에 대해
- RDD
- ML 파이프라인에 대해
- 교대 최소 제곱을 이용한 협업 필터링
- pyspark를 사용한 모델 기반 추천 시스템
- MLlib 추천 엔진 모듈
- 추천 엔진 접근 방식
- 구현 방법
- 데이터 로딩
- 데이터 탐색
- 기본 추천 엔진 만들기
- 예측하기
- 사용자 기반 협업 필터링
- 모델 평가
- 모델 선택 및 하이퍼 매개변수 튜닝
- 교차 유효성 검사
- CrossValidator
- 학습 유효성 검사 분할
- ParamMaps/매개변수 설정하기
- 평가자 객체 설정하기
- 구현 방법
- 요약
- 스파크 2.0
- 8장. Neo4j로 실시간 추천 엔진 구축하기
- 서로 다른 그래프 데이터베이스 식별
- 레이블이 지정된 프로퍼티 그래프
- GraphDB 핵심 개념 이해하기
- 레이블이 지정된 프로퍼티 그래프
- Neo4j
- Cypher 쿼리 언어
- Cypher 쿼리 기본
- 노드 문법
- 관계 문법
- 첫 번째 그래프 만들기
- 노드 만들기
- 관계 만들기
- 관계에 프로퍼티 설정하기
- csv에서 데이터 불러오기
- Cypher 쿼리 언어
- Neo4j 윈도우 버전 설치하기
- 리눅스에서 Neo4j 설치하기
- Neo4j 다운로드하기
- Neo4j 설정하기
- 명령행에서 Neo4j 시작하기
- 추천 엔진 만들기
- 데이터를 Neo4j로 보내기
- Neo4j를 사용해 추천 정보 만들기
- 유클리드 거리를 이용한 협업 필터링
- 코사인 유사성을 사용한 협업 필터링
- 요약
- 서로 다른 그래프 데이터베이스 식별
- 9장. 머하웃을 이용한 추천 엔진 구축하기
- 머하웃: 개요
- 머하웃 설정하기
- 독립 모드: 라이브러리로서 머하웃 사용하기
- 분산 모드용 머하웃 설정하기
- 머하웃의 코어 빌딩 블록
- 사용자 기반 협업 추천 엔진의 컴포넌트
- 머하웃을 사용해 추천 엔진 만들기
- 데이터 세트 내용
- 사용자 기반의 협업 필터링
- 아이템 기반의 협업 필터링
- 협업 필터링 평가하기
- 사용자 기반 추천인 평가
- 아이템 기반 추천인 평가
- SVD 추천
- 머하웃을 이용한 분산 추천
- 하둡에서의 ALS 추천 방법
- 확장 가능한 시스템 아키텍처
- 요약
- 10장. 추천 엔진의 미래: 다음은 무엇일까?
- 추천 엔진의 미래
- 추천 엔진의 단계
- 단계 1: 일반적인 추천 엔진
- 단계 2: 개인화된 추천인 시스템
- 단계 3: 미래 지향적 추천 시스템
- 검색의 종료
- 웹 검색의 종말
- 웹에서의 새로운 등장
- 차선책
- 유스케이스 고려
- 스마트 홈
- 헬스케어 추천인 시스템
- 추천 뉴스
- 인기 있는 방법론
- 세렌디피티
- 추천 엔진의 시간적 측면
- A/B 테스트
- 피드백 메커니즘
- 요약
관련 블로그 글
고객의 취향을 저격하는 추천 시스템 개발하기

사용자의 선호, 습관, 소비 등의 데이터를 분석해 그 결과를 기반으로 사용자에게 알맞은 정보나 콘텐츠, 상품을 추천하는 기술을 추천 시스템이라고 한다. 셀 수 없이 많고 다양한 정보의 바다에서 시간을 들여 검색하지 않고도 관심 있는 분야의 콘텐츠와 상품을 쉽게 찾을 수 있기 때문에 추천 시스템은 다양한 분야에서 활용되고 있다.
초창기의 추천 시스템은 그다지 정확하지 않았지만 시간이 지나 기술의 발달과 빅데이터를 기반으로 한 분석과 활용으로 현재는 매우 정교해저 여러 분야에서 추천 시스템을 적용하고 있으며, 사용자도 이를 적극 활용하고 있다.
구글, 아마존, 페이스북, 유튜브, 넷플릭스 등의 미국 기업뿐만 아니라 국내 기업에서도 사용자의 활동, 습관 등의 데이터를 수집하고, 딥러닝 기술을 이용해 그 데이터를 분석한 결과를 기반으로 개인 취향에 맞는 콘텐츠를 추천한다. 그리고 이런 추천 시스템의 효과는 어마어마하다.
아마존의 경우 판매의 35%가 추천 엔진으로부터 비롯됐으며, 넷플릭스의 경우 구독자의 80%가 추천 시스템을 통해 영화를 선택한다고 추정할 뿐 아니라 추천 엔진 덕분에 연간 10억 달러를 절약할 수 있다고 밝혔다. 네이버 역시 인공지능 기반 추천 시스템을 적용해 뉴스 소비량은 약 17%, 동영상 소비량은 약 18% 증가했으며, 이런 성과를 바탕으로 점차 적용 범위를 확대하고 있다.(역자 서문 中)
추천 시스템은 사용자들의 선호도를 이용해서 선택 가능한 많은 집합들로부터 아이템들을 필터링하는 협업 필터링 추천 시스템, 아이템 속성과 해당 아이템 속성에 대한 사용자 선호도를 사용해 콘텐츠 기반 추천 엔진을 구축하는 콘텐츠 기반 추천 시스템, 견고한 시스템을 구축하기 위해 다양한 추천 시스템들을 결합해 시스템을 구축하는 하이브리드 추천 시스템, 현재 시각, 계절, 분위기, 장소, 시스템이 제공하는 옵션 등과 같은 상황에 따라 추천 항목을 제안하는 상황 인식 추천 시스템 등 목적과 사용 기법에 따라 종류가 있다. 물론 이 책에서도 다양한 추천 시스템과 추천 엔진에 대한 이론을 소개하고 있으며, 협업 필터링 방식의 추천 엔진은 실제로 구현해보는 내용도 다루고 있다.
이 같은 다양한 기술을 바탕으로 한 추천 시스템은 주위에서도 쉽게 찾아볼 수 있다.
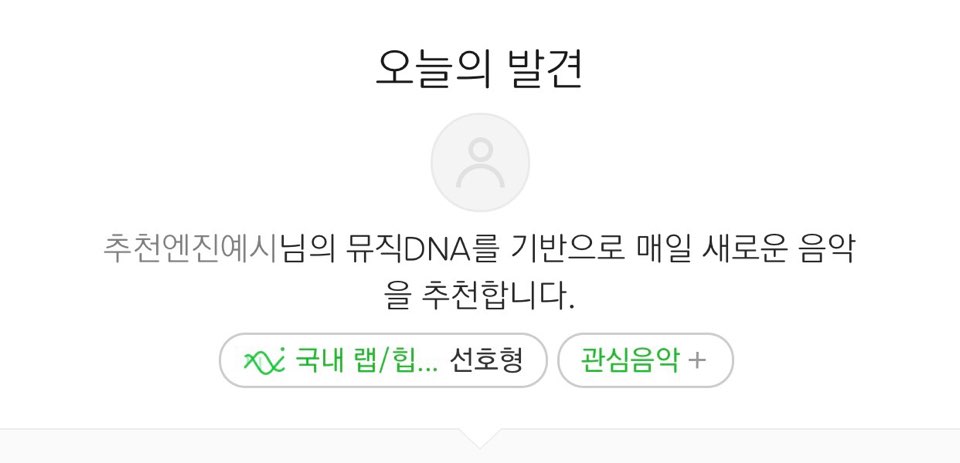
<멜론> <왓챠(영화 평가 애플리케이션)>
사용자의 이용 내역과 선호 표시 등을 바탕으로 유형을 분석하고, 이와 유사한 콘텐츠를 추천하고 있다.
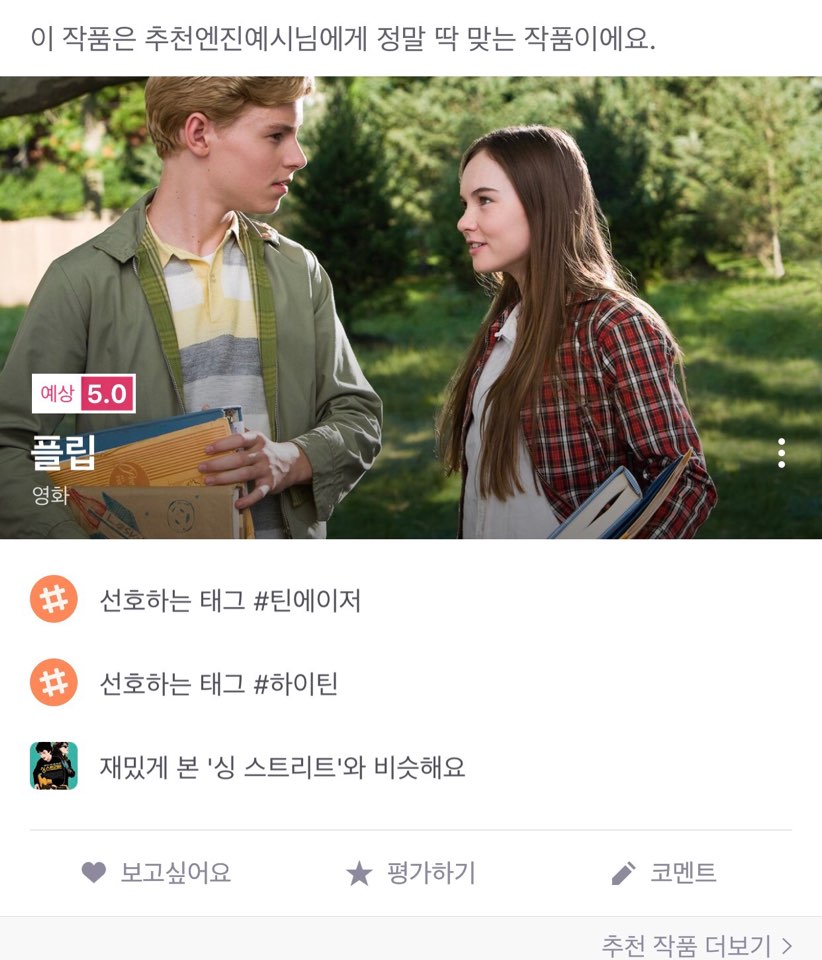
<네이버 TV> <쿠팡>

<아마존>
특정 콘텐츠(상품)를 선택했을 때 해당 콘텐츠의 유형, 인물, 속성 등과 연관된 콘텐츠를 추천한다.
끊임 없는 정보의 축적과 기술의 발달로 추천 시스템은 점점 다양해지고 정교해지고 있으며, 기업들은 추천 엔진에 많은 토자를 하고 다양한 방식의 적용으로 성능 향상을 위해 노력하고 있다.
추천 시스템의 원리부터 실제 추천 엔진의 구현까지 다루고 있는 이 책은 추천 엔진에 대한 이론과 실무에 대한 기본적인 내용을 모두 파악하는 데 도움을 주는 기본서다. 추천 엔진에 관심이 있고 추천 엔진의 현재와 미래에 대한 분석을 통해 통찰력을 가지고 싶다면 이 책을 읽어보길 바란다.

크리에이티브 커먼즈 라이센스 이 저작물은 크리에이티브 커먼즈 코리아 저작자표시 2.0 대한민국 라이센스에 따라 이용하실 수 있습니다.
도서 오류 신고
정오표
정오표
수정 사항은 여기에서 볼 수 있습니다.
[p.67 : 아래서 3행]
이러한 유형의 시스템에서 주요 관계자는 사용자, 제품, 그리고 등급/순위/제품 선호도와 같은 사용자의 선호도 정보다.
->
"이러한 유형의 시스템에서 주요 관계자는 사용자, 제품 그리고 등급/순위/제품 선호도와 같은 '사용자의 선호'도 정보로 사용한다.
[p.193 : 아래에서 5행(정식 URL의 접속 불가)]
http://files.grouplens.org/datasets/movielens/ml-100k.zip
->
https://www.kaggle.com/prajitdatta/movielens-100k-dataset