책 소개
요약
스파크는 빅데이터 분석을 위한 가장 핵심적인 기술 중 하나다. 이 책에서는 스파크의 개념 및 설치, 활용법의 상세한 설명으로 독자들의 이해를 돕는다. 또한 스파크와 통합되는 타 기술들과 빅데이터 분석에 관한 전반적인 지식도 다룬다. 대중적으로 익숙한 파이썬을 활용한 소스 코드로 독자들이 쉽게 따라 하며 학습할 수 있도록 구성했다.
이 책에서 다루는 내용
■ 빅데이터 및 하둡 에코 시스템에서 스파크의 진화하는 역할 이해
■ 다양한 배포 모드를 사용해 스파크 클러스터 생성
■ 스파크 클러스터 및 응용 프로그램의 제어 및 최적화
■ 마스터 스파크 코어 RDD API 프로그래밍 기술
■ 공유 변수, RDD 스토리지 및 파티셔닝을 포함한 고급 APl 플랫폼 구성으로 스파크 루틴을 확장, 가속 및 최적화
■ SQL 및 비관계형 데이터 저장소로 스파크를 효율적으로 통합
■ 스파크 스트리밍 및 아파치 카프카를 사용한 스트림 처리 및 메시징 수행
■ SparkR 및 스파크 Mllib를 사용한 예측 모델링 구현
이 책의 대상 독자
빅데이터 분야에 입문하거나 축적한 지식을 이 영역에 통합하려는 데이터 분석가 및 엔지니어를 대상으로 하는 책이다. 스파크는 빅데이터에 탁월한 프로세싱 프레임워크로서 현재 빅데이터 분야에서 전문적인 기술을 보유한 엔지니어가 많이 사용하고 있다.
파이썬 프로그래밍 경험이 있는 사람이라면 이 책을 볼 때 더 이해하기 쉬우므로 파이썬에 관한 경험은 유용하지만, 반드시 필요한 것은 아니다. 데이터 분석 및 조작과 관련한 훌륭한 실무 지식도 도움이 될 수 있다. 특히 빅데이터 영역으로 커리어를 확장하고자 하는 데이터 웨어하우스 전문가에게 적합하다.
이 책의 구성
1부, ‘스파크 기초’에서는 스파크를 배치하는 방법, 기본적인 데이터 처리 작업을 위해 스파크의 사용법을 확실하게 이해하도록 설계된 네 개의 장이 포함돼 있다.
1장, ‘빅데이터, 하둡 및 스파크 소개’에서는 스파크 프로젝트의 기원과 진화를 비롯해 빅데이터 에코 시스템에 대한 개념을 설명한다. 스파크 프로젝트의 핵심 속성은 스파크가 무엇인지, 어떻게 사용되는지, 하둡 프로젝트와는 어떤 관련이 있는지 등을 설명한다.
2장, ‘스파크 배포’에서는 다양한 스파크 클러스터 배포 모드와 스파크를 활용하는 다양한 방법을 포함해 스파크 클러스터를 배포하는 방법을 보여 준다.
3장, ‘스파크 클러스터 아키텍처의 이해’에서는 스파크 클러스터 및 응용 프로그램의 작동 방식에 관해 설명하고 스파크의 작동 방식을 확실히 이해하도록 돕는다.
4장, ‘스파크 프로그래밍 기초 학습’에서는 탄력적인 분산 데이터 세트(RDD, Resilient Distributed Dataset) API를 사용해서 스파크의 블록으로 구성된 기본 프로그래밍에 대해 중점적으로 다룬다.
2부, ‘스파크 응용’에서는 스트리밍 응용 프로그램, 데이터 과학 및 머신 러닝과 함께 사용되는 스파크 코어의 확장 및 응용에 관해 다음 네 개의 장에서 다룬다.
5장, ‘스파크 코어 API를 사용한 고급 프로그래밍’에서는 다양한 공유 변수 및 RDD 스토리지, 파티션 개념 및 구현을 포함해서 스파크 루틴을 확장, 가속, 최적화하는 데 사용되는 고급 구문을 설명한다.
6장, ‘스파크로 SQL 및 NoSQL 프로그래밍하기’에서는 스파크가 방대한 SQL 환경 및 비관계형 저장소와 통합하는 것에 관해 설명한다.
7장, ‘스파크를 사용한 스트림 처리 및 메시징’에서는 스파크 스트리밍 프로젝트와 기본 DStream 객체를 소개한다. 또한 스파크를 아파치 카프카와 같은 대중적인 메시징 시스템과 함께 사용하는 방법도 다룬다.
8장, ‘스파크를 사용한 데이터 과학 및 머신 러닝 소개’에서는 스파크에서 머신 러닝을 구현하는 데 사용되는 스파크 MLlib 하위 프로젝트뿐만 아니라 R과 스파크를 함께 사용하는 예측 모델링에 관해 소개한다.
목차
목차
- 1부. 스파크 기초
- 1장. 빅데이터, 하둡 및 스파크 소개
- 빅데이터, 분산 컴퓨팅 및 하둡 소개
- 빅데이터와 하둡의 간략한 역사
- 하둡
- 아파치 스파크 소개
- 아파치 스파크 배경
- 스파크 사용
- 스파크 프로그래밍 인터페이스
- 스파크 프로그램의 제출 유형
- 스파크 응용 프로그램의 입력/출력 유형
- 스파크 RDD
- 스파크와 하둡
- 파이썬을 이용한 함수 프로그래밍
- 파이썬 함수 프로그래밍에서 사용되는 데이터 구조
- 파이썬 객체 직렬화
- 파이썬 함수형 프로그래밍 기초
- 요약
- 빅데이터, 분산 컴퓨팅 및 하둡 소개
- 2장. 스파크 배포
- 스파크 배포 모드
- 로컬 모드
- 스파크 독립실행형
- 얀에서의 스파크
- 메소스에서의 스파크
- 스파크 설치 준비
- 스파크 가져오기
- 리눅스나 맥 OS X에서 스파크 설치하기
- 윈도우에 스파크 설치하기
- 스파크 설치 탐색
- 다중노드(Multi-Node) 스파크 독립실행형 클러스터 배포
- 클라우드에서 스파크 배포
- 아마존 웹 서비스
- 구글 클라우드 플랫폼
- 데이터브릭스
- 요약
- 스파크 배포 모드
- 3장. 스파크 클러스터 아키텍처의 이해
- 스파크 응용 프로그램의 해부
- 스파크 드라이버
- 스파크 작업자 및 실행자
- 스파크 마스터와 클러스터 매니저
- 독립실행형 스케줄러를 사용하는 스파크 응용 프로그램
- 얀에서 실행되는 스파크 응용 프로그램
- 얀에서 실행되는 스파크 응용 프로그램의 배포 모드
- 클라이언트 모드
- 클러스터 모드
- 로컬 모드 재검토
- 요약
- 스파크 응용 프로그램의 해부
- 4장. 스파크 프로그래밍 기초 학습
- RDD의 소개
- RDD에 데이터 로드하기
- 하나 이상의 파일에서 RDD 생성하기
- 하나 이상의 텍스트 파일에서 RDD를 만드는 방법
- 오브젝트 파일에서 RDD 만들기
- 데이터 소스에서 RDD 만들기
- JSON 파일에서 RDD 만들기
- 프로그래밍 방식으로 RDD 생성하기
- RDD 연산
- 주요 RDD 개념
- 기본 RDD 변환
- 기본 RDD 액션
- PairRDD의 변환
- 맵리듀스 및 워드 카운트(Word Count) 연습
- 조인(Join) 변환
- 스파크에서 데이터세트 조인하기
- 세트(Sets)의 변환
- 숫자(numeric) RDD의 변환
- 요약
- 2부. 스파크 응용
- 5장. 스파크 코어 API를 사용한 고급 프로그래밍
- 스파크의 공유변수
- 브로드캐스트 변수
- 어큐뮬레이터
- 연습: 브로드캐스트 변수 및 어큐뮬레이터 사용
- 스파크의 데이터 파티셔닝
- 파티셔닝 개요
- 파티션 제어
- 함수 재분할
- 파티션 별 또는 파티션 인식 API 메소드
- RDD 저장 옵션
- RDD 리니지 재검토
- RDD 저장 옵션
- RDD 캐싱
- RDD 유지
- RDD를 유지하거나 캐시할 시기 선택하기
- RDD 체크포인트 지정
- 연습: RDD 체크포인트
- 외부 프로그램으로 RDD 처리하기
- 스파크를 사용해 데이터 샘플링하기
- 스파크 응용 프로그램 및 클러스터 구성 이해하기
- 스파크 환경변수
- 스파크 구성 속성
- 스파크 최적화하기
- 초기 필터, 자주 필터
- 연관연산 최적화하기
- 함수 및 클로저의 영향 이해하기
- 데이터 수집을 위한 고려 사항
- 응용 프로그램 조정 및 최적화를 위한 구성 매개변수
- 비효율적인 파티셔닝 피하기
- 응용 프로그램 성능 문제 진단하기
- 요약
- 스파크의 공유변수
- 6장. 스파크로 SQL 및 NoSQL 프로그래밍하기
- 스파크 SQL 소개
- 하이브 소개
- 스파크 SQL 아키텍처
- 데이터프레임 시작하기
- 데이터프레임 사용
- 캐싱, 지속 및 데이터프레임 재구성
- 데이터프레임 출력 저장
- 스파크 SQL 액세스하기
- 연습: 스파크 SQL 사용하기
- NoSQL 시스템에서 스파크 사용하기
- NoSQL 소개
- HBase와 스파크 사용하기
- 연습: HBase로 스파크 사용하기
- 카산드라와 함께 스파크 사용하기
- DynamoDB에서 스파크 사용하기
- 기타 NoSQL 플랫폼
- 요약
- 스파크 SQL 소개
- 7장. 스파크를 사용한 스트림 처리 및 메시징
- 스파크 스트리밍 소개
- 스파크 스트리밍 아키텍처
- DStream 소개
- 연습: 스파크 스트리밍 시작하기
- State 연산
- 슬라이딩 윈도우 연산
- 구조화된 스트리밍
- 구조화된 스트리밍 데이터 소스
- 구조화된 스트리밍 데이터 싱크
- 출력 모드
- 구조화된 스트리밍 연산
- 메시징 플랫폼에서 스파크 사용
- 아파치 카프카
- 연습: 카프카와 스파크 사용하기
- 아마존 킨시스
- 요약
- 스파크 스트리밍 소개
- 8장. 스파크를 사용한 데이터 과학 및 머신 러닝 소개
- 스파크 및 R
- R 소개
- R에 스파크 사용하기
- 연습: SparkR과 함께 RStudio 사용하기
- 스파크로 머신 러닝하기
- 머신 러닝 입문서
- 스파크 MLlib를 사용한 머신 러닝
- 연습: 스파크 MLlib를 사용해서 Recommender 구현하기
- 스파크 ML을 사용한 머신 러닝
- 스파크와 함께 노트북 사용하기
- 주피터(IPython) 노트북과 스파크 사용하기
- 스파크에서 아파치 제플린 노트북 사용하기
- 요약
- 스파크 및 R
도서 오류 신고
정오표
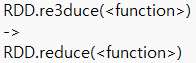
정오표
[p.123 : 3행]