통계학으로 배우는 머신러닝 2/e [스탠퍼드대학교 통계학과 교수에게 배우는 머신러닝의 원리]
- 원서명Elements of Statistical Learning: Data Mining, Inference, and Prediction, Second Edition (ISBN 9780387848570)
- 지은이트레버 헤이스티(Trevor Hastie), 로버트 팁시라니(Robert Tibshirani), 제롬 프리드먼(Jerome Friedman)
- 옮긴이이판호
- ISBN : 9791161754727
- 60,000원
- 2020년 11월 30일 펴냄
- 하드커버 | 844쪽 | 155*235mm
- 시리즈 : acorn ADVANCED, 데이터 과학
책 소개
2021년 대한민국학술원 우수학술도서 선정도서
요약
머신러닝을 통한 모델 학습을 통계학적 체계 내에서 설명한다. 다양한 통계 이론을 살펴보고, 회귀에서 신경망에 이르는 머신러닝 알고리즘에서 이들이 어떠한 의의가 있는지 배울 수 있다. 단순히 머신러닝 모델을 적용하는 것을 넘어 모델의 이론적 배경을 이해함으로써 데이터에서 더욱 깊은 인사이트를 얻고자 하는 사람에게 추천한다.
이 책의 대상 독자
통계학, 인공지능, 공학, 금융 등 다양한 분야의 연구자와 학생을 위해 썼다. 이 책을 읽는 독자가 선형회귀를 포함한 기본 주제를 다루는 통계학의 기초 강의를 적어도 하나는 수강했기를 기대한다.
학습법의 포괄적인 안내서를 쓰기보다는 가장 중요한 기술 몇 가지를 설명하고자 했다. 또한 하부 개념과 고려 사항을 설명해 연구자가 학습법을 판단할 수 있게 했다. 수학적 세부 사항보다는 개념을 강조해 직관적인 방식으로 작성했다.
우리는 자연스럽게 통계학자로서의 배경과 전문 분야를 반영하게 될 것이다. 그러나 과거 8년 동안 신경망, 데이터 마이닝과 머신러닝에 관한 콘퍼런스에 참여했으며, 이러한 흥미진진한 분야에 크게 영향을 받았다.
이 책의 구성
복잡한 방법을 완전히 파악하려 하기 전에 반드시 간단한 방법부터 이해해야 한다. 따라서 2장에서 지도 학습 문제에 관한 개요를 제공한 다음 3장과 4장에서 회귀와 분류를 위한 선형 방법을 논의한다. 5장에서는 단일 예측변수를 위한 스플라인(spline), 웨이블렛(wavelet)과 정칙화/벌점화법을 설명하며, 6장에서는 커널 방법과 국소 회귀(local regression)를 다룬다. 이들 방법 모두 고차원 학습 기법의 중요한 기본 토대가 된다. 모델 평가와 선택이 7장의 주제이며, 편향과 분산의 개념, 과적합 및 모형 선택을 위한 교차 검증과 같은 방법을 다룬다. 8장은 최대가능도, 베이지안 추론과 부트스트랩, EM 알고리즘, 깁스 샘플링, 배깅(bagging)의 개요를 포함해 모형 추론과 평균화에 관해 논의한다. 부스팅(boosting)이라 부르는 과정은 10장에서 집중적으로 다룬다.
9장부터 13장까지는 지도 학습을 위한 일련의 구조적 방법을 설명한다. 특히 9장과 11장에서는 회귀를 다루며 12장과 13장에서는 분류에 집중한다. 14장에서는 비지도 학습을 위한 방법에 관해 설명한다. 최근에 알려진 기법인 랜덤 포레스트와 앙상블 학습은 15장과 16장에서 논의한다. 무방향 그래프 모델은 17장에서 설명하며, 마지막으로 18장에서 고차원 문제를 공부한다.
각 장의 마지막에서는 관측치와 예측자의 개수에 따라 어떻게 연산이 확장되는지 등을 포함해 데이터 마이닝 응용법에 중요한 연산적 고려 사항에 관해 논의한다. 각 장은 자료를 위한 배경 참조를 제공하는 참고문헌으로 마무리된다.
먼저 1장부터 4장까지 순서대로 읽기를 추천한다. 7장 또한 모든 학습법에 관련된 핵심 개념을 다루므로 의무적으로 읽어야 한다. 책의 나머지는 독자의 흥미에 따라 순서대로 읽거나 혹은 선택해서 읽을 수 있다.
상세 이미지

목차
목차
- 1장. 소개
- 2장. 지도 학습의 개요
- 2.1 소개
- 2.2 변수 타입과 용어
- 2.3 예측을 위한 단순한 두 접근법: 최소 제곱과 최근접이웃
- 2.3.1 선형 모델과 최소 제곱42
- 2.3.2 최근접이웃 방법
- 2.3.3 최소제곱에서 최근접이웃까지
- 2.4 통계적 결정 이론
- 2.5 고차원에서의 국소적 방법
- 2.6 통계적 모델, 지도 학습 및 함수 근사60
- 2.6.1 결합분포 Pr(X , Y )를 위한 통계적 모델
- 2.6.2 지도 학습
- 2.6.3 함수 근사
- 2.7 구조화된 회귀 모델
- 2.7.1 문제의 어려움
- 2.8 제한된 추정량의 종류
- 2.8.1 조도 벌점과 베이즈 방법
- 2.8.2 커널법과 국소 회귀
- 2.8.3 기저함수와 딕셔너리 방법
- 2.9 모델 선택과 편향 - 분산 상반관계
- 참고문헌
- 연습 문제
- 3장. 회귀를 위한 선형법
- 3.1 소개
- 3.2 선형회귀 모델과 최소제곱
- 3.2.1 예제: 전립선암
- 3.2.2 가우스-마코프 정리
- 3.2.3 단순 일변량 회귀로부터의 다중회귀
- 3.2.4 다중 출력
- 3.3 부분집합 선택
- 3.3.1 최량 부분집합 선택
- 3.3.2 전진 및 후진 스텝별 선택
- 3.3.3 전진 - 스테이지별 회귀
- 3.3.4 전립선암 데이터 예제(계속)
- 3.4 수축법
- 3.4.1 릿지회귀
- 3.4.2 라쏘
- 3.4.3 논의: 부분집합 선택, 릿지회귀 그리고 라쏘
- 3.4.4 최소각회귀
- 3.5 유도된 입력 방향을 사용하는 방법들
- 3.5.1 주성분회귀
- 3.5.2 부분최소제곱
- 3.6 논의: 선택법과 수축법 비교
- 3.7 다중 결과 수축 및 선택
- 3.8 라쏘 및 관련된 경로 알고리즘에 관한 추가 내용
- 3.8.1 증가적 전진 스테이지별 회귀
- 3.8.2 조각별 - 선형 경로 알고리즘
- 3.8.3 댄치그 선택자
- 3.8.4 그룹화 라쏘
- 3.8.5 라쏘의 추가적인 속성
- 3.8.6 경로별 좌표 최적화
- 3.9 연산적 고려 사항
- 참고문헌
- 연습 문제
- 4장. 분류를 위한 선형법
- 4.1 소개
- 4.2 지시행렬의 선형회귀
- 4.3 선형판별분석
- 4.3.1 정칙판별분석
- 4.3.2 LDA를 위한 연산
- 4.3.3 축소된 랭크 선형판별분석
- 4.4 로지스틱회귀
- 4.4.1 로지스틱회귀 모델 적합
- 4.4.2 예제: 남아프리카인 심장병
- 4.4.3 이차근사 및 추론
- 4.4.4 L1 정칙화 로지스틱회귀
- 4.4.5 로지스틱회귀 아니면 LDA?
- 4.5 분리초평면
- 4.5.1 로젠블랫의 퍼셉트론 학습 알고리즘
- 4.5.2 최적 분리초평면
- 참고문헌
- 연습 문제
- 5장. 기저전개와 정칙화
- 5.1 소개
- 5.2 조각별 다항식과 스플라인
- 5.2.1 자연 삼차 스플라인
- 5.2.2 예제: 남아프리카 심장 질환(계속)
- 5.2.3 예제: 음소 인식
- 5.3 필터링과 특성 추출
- 5.4 평활 스플라인
- 5.4.1 자유도와 평활자 행렬
- 5.5 평활화 매개변수의 자동적 선택
- 5.5.1 자유도 고정하기
- 5.5.2 편향 - 분산 상반관계
- 5.6 비모수적 로지스틱회귀
- 5.7 다차원 스플라인
- 5.8 정칙화 및 재생 커널 힐베르트 공간
- 5.8.1 커널에 의해 생성된 함수의 공간
- 5.8.2 RKHS 예시
- 5.9 웨이블릿 평활화
- 5.9.1 웨이블릿 기저와 웨이블릿 변환
- 5.9.2 적응적 웨이블릿 필터링
- 참고문헌
- 연습 문제
- 부록: 스플라인 연산
- B - 스플라인
- 평활 스플라인의 연산
- 6장. 커널 평활법
- 6.1 1차원 커널 평활자
- 6.1.1 국소 선형회귀
- 6.1.2 국소 다항회귀
- 6.2 커널의 너비 선택하기
- 6.3 Rp에서의 국소 회귀
- 6.4 Rp에서의 구조적 국소 회귀 모델
- 6.4.1 구조화 커널
- 6.4.2 구조화 회귀함수
- 6.5 국소 가능도 및 다른 모델
- 6.6 커널 밀도 추정 및 분류
- 6.6.1 커널 밀도 추정
- 6.6.2 커널 밀도 분류
- 6.6.3 단순 베이즈 분류기
- 6.7 방사기저함수와 커널
- 6.8 밀도 추정과 분류를 위한 혼합 모델
- 6.9 연산 고려 사항
- 참고문헌
- 연습 문제
- 6.1 1차원 커널 평활자
- 7장. 모델 평가 및 선택
- 7.1 소개
- 7.2 편향, 분산, 모델 복잡도
- 7.3 편향-분산 분해
- 7.3.1 예제: 편향 - 분산 상반관계
- 7.4 훈련 오류율에 관한 낙관도
- 7.5 표본-내 예측오차의 추정값
- 7.6 매개변수의 유효 개수
- 7.7 베이즈 접근법과 BIC
- 7.8 최소 설명 길이
- 7.9 밥닉-체브넨키스 차원
- 7.9.1 예제(계속)
- 7.10 교차 검증
- 7.10.1 K-겹 교차 검증
- 7.10.2 교차 검증을 하는 잘못된 그리고 옳은 방법
- 7.10.3 교차 검증은 정말로 작동하는가?
- 7.11 부트스트랩법
- 7.11.1 예제(계속)
- 7.12 조건부 혹은 기대 테스트 오차
- 참고문헌
- 연습 문제
- 8장. 모델 추론과 평균화
- 8.1 소개
- 8.2 부트스트랩과 최대가능도 방법
- 8.2.1 평활화 예제
- 8.2.2 최대가능도 추정
- 8.2.3 부트스트랩 대 최대가능도
- 8.3 베이즈 방법
- 8.4 부트스트랩과 베이즈 추정 사이의 관계
- 8.5 EM 알고리즘
- 8.5.1 2 - 성분 혼합모델
- 8.5.2 일반적인 EM 알고리즘
- 8.5.3 최대화 - 최대화 과정으로써의 EM
- 8.6 사후분포로부터 표본 추출을 위한 MCMC
- 8.7 배깅
- 8.7.1 예제: 시뮬레이션 데이터로 된 트리
- 8.8 모델 평균화와 스태킹
- 8.9 확률적 검색: 범핑
- 참고문헌
- 연습 문제
- 9장. 가법 모델, 트리 및 관련 방법들
- 9.1 일반화 가법 모델
- 9.1.1 가법 모델 적합시키기
- 9.1.2 예제: 가법 로지스틱회귀
- 9.1.3 요약
- 9.2 트리 기반 방법
- 9.2.1 배경
- 9.2.2 회귀 트리
- 9.2.3 분류 트리
- 9.2.4 다른 문제들
- 9.2.5 스팸 예제(계속)
- 9.3 PRIM: 범프 헌팅
- 9.3.1 스팸 예제(계속)
- 9.4 MARS: 다변량 적응적 회귀 스플라인
- 9.4.1 스팸 데이터(계속)
- 9.4.2 예제(시뮬레이션된 데이터)
- 9.4.3 다른 문제들
- 9.5 전문가 계층 혼합
- 9.6 결측 데이터
- 9.7 연산 고려 사항
- 참고문헌
- 연습 문제
- 9.1 일반화 가법 모델
- 10장. 부스팅과 가법 트리
- 10.1 부스팅법
- 10.1.1 개요
- 10.2 부스팅 적합과 가법 모델
- 10.3 전진 스테이지별 가법 모델링
- 10.4 지수손실과 에이다 부스트
- 10.5 왜 지수손실인가?
- 10.6 손실함수와 로버스트성
- 10.7 데이터 마이닝을 위한 “기성품” 같은 과정
- 10.8 예제: 스팸 데이터
- 10.9 부스팅 트리
- 10.10 경사 부스팅을 통한 수치적 최적화
- 10.10.1 최급하강
- 10.10.2 경사 부스팅
- 10.10.3 경사 부스팅의 구현
- 10.11 부스팅을 위한 적절한 크기의 트리
- 10.12 정칙화
- 10.12.1 수축
- 10.12.2 부표집
- 10.13 해석
- 10.13.1 예측변수의 상대 중요도
- 10.13.2 부분 의존도 도표
- 10.14 삽화
- 10.14.1 캘리포니아 주택
- 10.14.2 뉴질랜드 물고기
- 10.14.3 인구통계 데이터
- 참고문헌
- 연습 문제
- 10.1 부스팅법
- 11장. 신경망
- 11.1 소개
- 11.2 사영추적 회귀
- 11.3 신경망
- 11.4 신경망 적합시키기
- 11.5 신경망을 훈련시킬 때의 문제
- 11.5.1 시작값
- 11.5.2 과적합
- 11.5.3 입력변수의 척도화
- 11.5.4. 은닉 유닛과 층의 개수
- 11.5.5 복수의 최솟값들
- 11.6 예제: 시뮬레이션 데이터
- 11.7 예제: 우편번호 데이터
- 11.8 논의
- 11.9 베이즈 신경망과 NIPS 2003 챌린지
- 11.9.1 베이즈, 부스팅, 배깅
- 11.9.2 성능 비교
- 11.10 연산 고려 사항
- 참고문헌
- 연습 문제
- 12장. 서포트벡터머신과 유연한 판별식
- 12.1 도입
- 12.2 서포트벡터분류기
- 12.2.1 서포트벡터분류기 연산하기
- 12.2.2 혼합 예제(계속)
- 12.3 서포트벡터머신과 커널
- 12.3.1 분류를 위한 SVM 연산
- 12.3.2 벌점화 방법으로서의 SVM
- 12.3.3 함수 추정과 재생커널
- 12.3.4 SVM과 차원성의 저주
- 12.3.5 SVM 분류기를 위한 경로 알고리즘
- 12.3.6 회귀를 위한 서포트벡터머신
- 12.3.7 회귀와 커널
- 12.3.8 논의
- 12.4 선형판별분석 일반화
- 12.5 유연한 판별분석
- 12.5.1 FDA 추정값 계산하기
- 12.6 벌점화 판별분석
- 12.7 혼합판별분석
- 12.7.1 예제: 파형 데이터
- 12.8 연산 고려 사항
- 참고문헌
- 연습 문제
- 13장. 프로토타입 방법과 최근접이웃법
- 13.1 개요
- 13.2 프로토타입법
- 13.2.1 K- 평균 군집화
- 13.2.2 학습 벡터 양자화
- 13.2.3 가우스 혼합
- 13.3 K-최근접이웃 분류기
- 13.3.1 예제: 비교 연구
- 13.3.2 예제: K - 최근접이웃과 이미지 장면 분류
- 13.3.3 불변 계량과 탄젠트 거리
- 13.4 적응적 최근접이웃법
- 13.4.1 예제
- 13.4.2 최근접이웃을 위한 전역 차원 축소
- 13.5 연산 고려 사항
- 참고문헌
- 연습 문제
- 14장. 비지도 학습
- 14.1 개요
- 14.2 연관성 규칙
- 14.2.1 시장 바스켓 분석
- 14.2.2 아프리오리 알고리즘
- 14.2.3 예제: 시장 바스켓 분석
- 14.2.4 지도 학습 같은 비지도
- 14.2.5 일반화 연관성 규칙
- 14.2.6 지도 학습법의 선택
- 14.2.7 예제: 시장 바스켓 분석(계속)
- 14.3 군집분석
- 14.3.1 근접도 행렬
- 14.3.2 속성에 근거한 비유사도
- 14.3.3 개체 비유사도
- 14.3.4 군집화 알고리즘
- 14.3.5 조합적 알고리즘
- 14.3.6 K - 평균
- 14.3.7 K - 평균 연군집화로서의 가우스 혼합
- 14.3.8 예제: 인간 종양 미세 배열 데이터
- 14.3.9 벡터 양자화
- 14.3.10 K- 중위점
- 14.3.11 실제적인 문제
- 14.3.12 계층적 군집화
- 14.4 자기 조직화 맵
- 14.5 주성분, 주곡선과 주표면
- 14.5.1 주성분
- 14.5.2 주곡선과 주표면
- 14.5.3 스펙트럼 군집화
- 14.5.4 커널 주성분
- 14.5.5 희박 주성분
- 14.6 비음수행렬 분해
- 14.6.1 원형분석
- 14.7 독립성분분석과 탐색적 사영추적
- 14.7.1 잠재변수와 인자분석
- 14.7.2 독립성분분석
- 14.7.3 탐색적 사영추적
- 14.7.4 ICA의 직접적 접근법
- 14.8 다차원 척도화
- 14.9 비선형 차원 축소와 국소 다차원 척도화
- 14.10 구글 페이지랭크 알고리즘
- 참고문헌
- 연습 문제
- 15장. 랜덤포레스트
- 15.1 개요
- 15.2 랜덤포레스트의 정의
- 15.3 랜덤포레스트의 세부 사항
- 15.3.1 아웃오브백 표본
- 15.3.2 변수 중요도
- 15.3.3 근접도 도표
- 15.3.4 랜덤포레스트와 과적합
- 15.4 랜덤포레스트의 분석
- 15.4.1 분산 및 역상관 효과
- 15.4.2 편향
- 15.4.3 적응적 최근접이웃
- 참고문헌
- 연습 문제
- 16장. 앙상블 학습
- 16.1 개요
- 16.2 부스팅과 정칙화 경로
- 16.2.1 벌점화 회귀
- 16.2.2 “희박성 베팅” 원칙
- 16.2.3 정칙화 경로, 과적합 그리고 마진
- 16.3 학습 앙상블
- 16.3.1 좋은 앙상블 학습하기
- 16.3.2 규칙 앙상블
- 참고문헌
- 연습 문제
- 17장. 무향 그래프 모델
- 17.1 개요
- 17.2 마코프 그래프 및 이들의 속성
- 17.3 연속형 변수를 위한 무향 그래프 모델
- 17.3.1 그래프 구조가 알려져 있을 때 매개변수의 추정
- 17.3.2 그래프 구조의 추정
- 17.4 이산변수를 위한 무향 그래프 모델
- 17.4.1 그래프 구조가 알려져 있을 때 매개변수의 추정
- 17.4.2 은닉 노드
- 17.4.3 그래프 구조의 추정
- 17.4.4 제약된 볼츠만 머신
- 참고문헌
- 연습 문제
- 18장. 고차원 문제: p≪N
- 18.1 p가 N보다 훨씬 클 때
- 18.2 대각 선형판별분석과 최근접 수축 중심점
- 18.3 이차 정칙화 선형 분류기
- 18.3.1 정칙판별분석
- 18.3.2 이차 정칙화로 된 로지스틱회귀
- 18.3.3 서포트벡터분류기
- 18.3.4 특성 선택
- 18.3.5 p ≫ N일 때 연산적인 지름길
- 18.4 L1 정칙화 선형 분류기
- 18.4.1 단백질 질량 분광분석의 라쏘 적용
- 18.4.2 함수형 데이터를 위한 퓨즈화 라쏘
- 18.5 특성을 쓸 수 없을 때의 분류
- 18.5.1 예제: 문자열 커널과 단백질 분류
- 18.5.2 내적 커널과 쌍별 거리를 사용하는 분류 및 다른
- 18.5.3 예제: 초록 분류
- 18.6 고차원 회귀: 지도 주성분
- 18.6.1 잠재변수 모델링과의 연결성
- 18.6.2 부분최소제곱과의 관계
- 18.6.3 특성 선택을 위한 전제조건화
- 18.7 특성 평가와 다중검정 문제
- 18.7.1 오발견율
- 18.7.2 비대칭 절단점과 SAM 과정
- 18.7.3 FDR의 베이즈적 해석
- 18.8 참고문헌
- 연습 문제
도서 오류 신고
정오표
정오표
[p.44 : 아래에서 2행]
f0(X) = β
->
f’(X) = β
[p.83 : 식 3.8 아래]
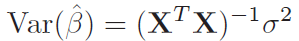
->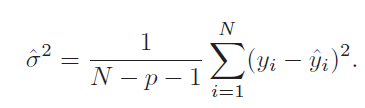
[p. 119 : 식 3.62 아래 4번째 행]
추성분회귀가 릿지회귀와 매우 유사하다는 것을 볼 것이며,
->
[p.120 : 6행]
그러므로 각 크을 구축할 때,
->
그러므로 각 zm을 구축할 때,
[p.120 : 알고리즘 3.3 2.a.]
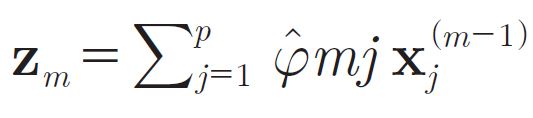
->