


GREAT CODE 제1권 [효율적인 코드 작성의 기초, 하드웨어의 이해 (재출간판)]
- 원서명Write Great Code: Volume 1: Understanding the Machine (ISBN 9781593270032)
- 지은이랜달 하이드(Randall Hyde)
- 옮긴이전동환, 최재식, 강승훈, 김원호
- 감수자히언
- ISBN : 9791161752471
- 30,000원
- 2019년 04월 18일 펴냄
- 페이퍼백 | 460쪽 | 188*235mm
- 시리즈 : 프로그래밍 언어
판매처
개정판책 소개
요약
「전자회로」, 「논리설계」, 「컴퓨터 아키텍처」, 「시스템 프로그래밍」…
대학교에서 이미 배운 과목인데 도무지 정리도 잘 안 되고, 막상 실무에서 사용하려고 하니 가물가물 생각이 잘 떠오르지 않는다면? 최고의 프로그래머가 되기 위해 반드시 알고 넘어가야 할 하드웨어와 컴퓨터 아키텍처에 대한 내용을 이 한 권에 녹여냈다. 컴퓨터 관련 전공 수업을 듣지 못했거나, 내용을 모두 잊어버렸거나, 기존 서적의 난해함에 질린 독자를 위한 필독서다.
이 책에 쏟아진 찬사
정규교육을 받지 못했거나 사수가 제대로 돌봐주지 않는 프로그래머들에게 랜달 하이드의 「GREAT CODE」시리즈는 큰 흥미를 불러일으킬 것이다. 첫 다섯 장과 불리언 로직을 설명한 장만으로도 책은 그 값어치를 충분히 한다.
-UnixRev1ew.com
이 책은 대부분의 프로그래머가 당연하게 받아들이는 것들에 대해 자세히 설명하고 있다.
-「Computer Shopper」
읽는 재미가 있다.
-「VSJ Magazine」
이 책은 초보자용은 아니며, 가장 깊은 단계의 복잡한 컴퓨터 연산에 대해 설명한다. 깊숙한 단계의 작업에 흥미가 있는 프로그래머들에게 매우 도움이 되는 책이다.
-secuntyworld.com
흔히 지나치기 쉬운 부분을 아주 잘 설명하고 있으며 컴퓨터공학 학위의 필독서가 될 만하다. 이 책을 한 번 읽고 나면 효율적으로 작성된 코드에 대해 깊이 이해하고 정확한 평가를 내릴 수 있게 될 것이다. 그리고 스스로도 코드를 효율적으로 작성할 수 있게 될 것이다.
-MacCompanion, ★★★★★
이 책은 어떤 언어를 사용하든 어셈블리 언어를 배우지 않고 뛰어난 코드를 작성하기 위한 방법을 알려주는 필독서 목록에 그 이름을 올려야 한다.
-WebServerTalk
저자는 모든 개발의 핵심과 깊숙이 연관돼 있는 컴퓨터 구조와 관련된 주제를 다룬다.
-「Practical Applications」
전형적인 ‘독학으로 프로그래밍 배우기’ 류의 책과는 다르다. 모든 언어와 모든 단계의 프로그래밍 경험과 관련이 있다. 어서 서점으로 달려가 이 책을 사서 읽기를 권한다.
-BAYLISA Bay Area Large Installation System Administrators
감수의 글
제가 감히 『GREAT CODE 제1권』을 감수하게 되다니, 매우 영광스러운 기회를 갖게 돼 감사하게 생각합니다. Great Code는 그냥 태어나는 것이 아니라, 컴퓨팅 환경을 잘 이해해야만 탄생할 수 있다는 점을 다시 한번 되새기는 기회였습니다. 감수는 번역물이 다루고 있는 내용이나 특정 기술 등에 대해 잘못된 설명이나 논리가 없는지, 그 기술이나 내용 자체에 대해 해당 분야의 전문가나 실무자 등이 내용을 확인하고 수정하는 과정입니다. 『GREAT CODE 제1권』은 저술 당시 최신 컴퓨팅 환경의 예를 들어 기술한 내용이 많습니다만, 어느 시대에도 변하지 않는 원리를 설명하는 데 매우 충실해, 이 내용을 충분히 이해하는 엔지니어라면 누구라도 Great Code를 작성할 수 있도록 잘 구성돼 있습니다. 그런 이유로 감수를 하는 데도 너무 시대에 뒤떨어진 기술을 제외하는 것 이외에는 더 큰 오류를 찾기 어려울 정도로 매우 잘 쓰인 책입니다. 임베디드 소프트웨어 엔지니어라면 누구라도 꼭 한번 읽어보기를 권합니다. 국내 임베디드 엔지니어를 위해 이 책이 절판되지 않도록 애쓰고 계신 에이콘출판사 대표님과 직원 여러분께도 경의를 표하는 바입니다.
히언 / 친절한 임베디드 시스템 개발자되기 강좌, 임베디드 레시피 운영자
이 책에서 다루는 내용
■ 숫자나 문자열, 고급 자료구조 등을 표기하는 방법을 익혀, 컴퓨터가 각 데이터 타입을 사용하는 데 드는 비용을 파악한다.
■ 컴퓨터가 데이터를 구성하는 방법을 익혀, 데이터를 효율적으로 처리하는 방법을 알아낸다.
■ CPU가 동작하는 방식을 익혀, 컴퓨터가 처리하는 방식대로 동작하는 프로그램 코드를 작성한다. 입출력 장치가 동작하는 방식을 이해하면, 그러한 장치에 접근하는 애플리케이션의 성능을 최대화할 수 있다.
■ 메모리 계층 구조를 최적화해 사용하는 방법을 익혀, 최대한 빠른 프로그램을 작성할 수 있다.
이 책의 대상 독자
이 책을 효과적으로 이용하기 위해서 적어도 한 가지 이상의 절차적 프로그램 언어를 다룰 줄 알아야 한다. C/C++, 파스칼(Pascal), 베이직(BASIC), 어셈블리 언어처럼 많이 사용되는 언어뿐 아니라 에이다(Ada), 모듈러2(Modula-2), 포트란(FORTRAN) 같은 언어여도 괜찮다. 또 작은 문제에 대한 명세를 받아서 그 문제에 대한 소프트웨어를 설계하거나 구현할 능력이 있어야 한다. 보통 대학 강의를 한 학기 정도 수강하거나, 독학으로 몇 달만 노력하면 이 책을 공부하는 데 큰 불편함은 없을 것이다.
이 책은 특별한 프로그램 언어를 위한 책은 아니다. 이 책에서 설명하는 개념은 프로그래밍 언어의 종류와 관계없이 적용할 수 있는 것들이다. 여러분의 편의를 위해서 프로그램 예문은 몇 가지 언어(C/C++, 파스칼, 베이직, 어셈블리 등)를 번갈아 가면서 사용할 것이다. 이 책을 쓸 때 여러분이 특정 언어를 알 것이라고 가정하지 않았다. 따라서 이 책에서 예시를 제시할 때는 코드에 대한 정확한 설명을 덧붙일 것이므로, 비록 그 언어에 익숙하지 않더라도 관련 설명을 통해서 프로그램의 동작을 충분히 이해할 수 있을 것이다.
이 책은 다양한 예시에서 다음 언어와 컴파일러를 사용했다.
■ C/C++: GCC, 마이크로소프트 비주얼 C++, 볼랜드 C++
■ 파스칼(Pascal): 볼랜드 델파이(Delphi)/카일릭스(Kylix)
■ 어셈블리: 마이크로소프트 MASM, HLA(the High Level Assembler), Gas(파워 PC용)
■ 베이직(BASIC): 마이크로소프트 비주얼 베이직
이 책의 구성
이 책에서는 프로그래머에게 직접 영향을 줄 수 있거나, 시스템 아키텍트의 의도를 이해하는 데 도움을 줄 수 있는 내용을 주로 다룬다. 컴퓨터 구조를 배우는 궁극적인 목적은 자신만의 CPU나 컴퓨터 시스템을 설계할 능력 배양이 아니라, 기존의 컴퓨터 설계를 가장 잘 활용하는 법을 아는 것이다.
그래도 컴퓨터 구조가 어떤 것인지 감이 오지 않는다면 책의 목차를 살펴보며 생각해 보자.
2장, 4장, 5장에서는 컴퓨터의 기본적인 데이터 표기법을 다룰 것이다. 예를 들어 컴퓨터가 어떠한 방법으로 부호 있는 정수와 부호 없는 정수, 문자, 문자열, 문자 집합, 실수, 분수와 같은 값들을 표현하는지 알아본다. 컴퓨터가 다양한 자료를 어떻게 표현하는지를 충분히 이해하지 못한다면, 특정 작업이 왜 그렇게도 비능률적인지 알 수 없을 것이다. 또 그 이유를 이해하지 못한다면 코드에서 데이터를 제대로 다루지 못할 가능성이 높고, 그 결과 최고의 코드와는 멀어지게 될 것이다.
3장에서는 대부분의 현대적인 컴퓨터 시스템에서 사용하는 이진법의 계산과 비트 오퍼레이션을 다룰 것이다. 대부분의 프로그램 언어가 이진법과 비트 오퍼레이션을 지원하기 때문에 이 책에서는 일반적인 프로그래밍 개론 과정에서 잘 다루지 않는 이진법과 논리 오퍼레이션을 통해 코드를 향상시키는 법에 대해서 알아볼 것이다. 최고의 코드를 작성하는 강력한 프로그래머가 되기 위해서는 널리 시용되는 이런 기법을 익숙하게 구사할 수 있어야 한다.
6장에서는 ‘메모리 계층과 접근’이라는 중요한 주제를 다룬다. 메모리 접근 문제는 현대 컴퓨터에서 시스템 성능 문제를 일으키는 주범이다. 6장은 메모리에 대한 소개를 시작으로 컴퓨터가 메모리에 접근하는 방법 메모리의 성능상 특징에 관해 상세히 설명하겠다.
또 CPU가 메모리에 있는 다양한 자료구조에 접근할 때 사용하는 메모리 지정모드(addressing mode)에 대해서도 알아볼 것이다. 요즘 프로그램 중에서도 프로그램의 세부적인 메모리 접근에 대한 고려가 부족해서 프로그램의 완성도가 떨어지는 경우가 많다. 6장에서는 여러 문제를 해결할 수 있는 기반지식을 제공할 것이다.
7장은 다시 데이터 표현으로 돌아가서 복합 데이터 타입과 메모리 객체를 다룬다. 여기서는 앞 부분의 여러 장에서 다뤘던 내용과는 다르게 포인터, 배열 레코드, 구조체, 공용체 등과 같이 하이 레벨 데이터 타입에 관해 공부하게 된다. 많은 프로그래머가 메모리, 성능상의 문제를 고려하지 않은 채 커다란 복합 데이터 구조를 사용하고 있다. 7장에서는 이런 하이 레벨 복합 데이터 타입을 로우 레벨의 관점으로 설명함으로써 프로그램에서 이 기법을 사용할 때 지불해야 할 비용이 어느 정도인지 알려준다. 결국 이 기법을 좀 더 신중하고 현명하게 사용할 수 있게 될 것이다.
8장에서는 불리언 로직(boolean logic)과 디지털 설계에 관해 다룰 것이다. 8장에서는 CPU 설계와 그 외의 컴퓨터 시스템 요소를 이해하기 위해 필요한 수학적, 논리적 배경 지식을 제공한다. 주로 하드웨어적인 소재를 다루지만, 진정한 최고의 코드를 작성할 때 사용할 수 있는 몇 가지 아이디어도 얻을 수 있다. 특히 if, while 등과 같이 일반적인 고급 언어에서 사용되는 불리언 식을 최적화하는 방법은 유용하게 사용할 수 있다.
9장 역시 8장에 이어 하드웨어적인 내용으로 CPU의 구조에 관해 다룬다. 이 책의 궁극적인 목적이 자신의 CPU를 디자인하는 법을 가르치는 것이 아님에도 불구하고, 기본적인 CPU 설계와 동작을 제대로 이해해야 최고의 코드를 작성할 수 있다. CPU가 코드를 수행하는 방식에 맞춰서 코드를 작성하면, 더 적은 시스템 자원을 사용해서 더 좋은 성능을 얻을 수 있다. 반면에 코드 작성을 CPU 동작에 맞추지 않는다면, 느리고 자원을 많이 사용하는 프로그램이 될 것이다.
10장에서는 CPU 명령어 집합구조(instruction set architecture)에 대해 알아볼 것이다. 모든 CPU에서 명령어는 CPU 동작에 가장 기본이 되는 부분이고, 프로그램 수행시간은 수행되는 명령어의 종류와 수에 직접적인 영향을 받는다. 컴퓨터 구조에서 명령어를 설계하는 방법을 이해하게 되면, 어떤 오퍼레이션이 다른 오퍼레이션보다 시간이 더 걸리는 이유를 알 수 있게 된다. 뿐만 아니라 명령어의 한계와 CPU가 명령어를 해석하는 방식을 이해하면, 형편없는 일련의 코드를 최고의 코드로 탈바꿈시킬 수도 있다.
11장에서는 메모리 이야기로 돌아와서 메모리 아키텍처와 구조에 대해 알아본다. 이 장은 빠른 코드를 작성하는 데 큰 도움이 될 것이다. 여기서는 메모리의 계층에 대해 설명하고 캐시의 성능을 극대화하는 방법, 다른 고속 메모리 구성 요소 등을 알아본다. 최고의 코드는 현대 컴퓨터 애플리케이션의 일반적인 문제인 스래싱(thrashing)을 피해야만 한다. 이 장에서 스래싱을 배우며 애플리케이션에서 낮은 성능의 메모리 접근을 피하는 방법을 알게 될 것이다.
목차
목차
- 1장. 최고의 코드를 위해 알아야 할 것
- 1.1 ‘GREAT CODE’ 시리즈
- 1.2 이 책의 내용
- 1.3 이 책의 대상
- 1.4 최고의 코드의 특징
- 1.5 동작 환경
- 1.6 더 많은 정보를 원한다면
- 2장. 수치 표기법
- 2.1 수란 무엇인가?
- 2.2 수 체계
- 2.3 수치/문자열 변환
- 2.4 내부 수치 표현법
- 2.5 부호 있는 수와 부호 없는 수
- 2.6 2진수의 유용한 속성
- 2.7 부호 확장, 0 확장과 축소
- 2.8 포화
- 2.9 2진화 10진 표기법
- 2.10 고정소수점 표기
- 2.11 스케일 수치 포맷
- 2.12 유리수 표기법
- 2.13 더 많은 정보를 원한다면
- 3장. 2진법 연산과 비트 연산
- 3.1 2진수, 16진수의 연산
- 3.2 비트 논리 연산
- 3.3 2진수와 비트 스트링에 대한 논리 연산
- 3.4 유용한 비트 연산
- 3.5 쉬프트와 로테이트
- 3.6 비트 필드와 묶인 데이터
- 3.7 데이터 묶기와 풀기
- 3.8 더 많은 정보를 원한다면
- 4장. 부동소수점 표기
- 4.1 부동소수점 연산 소개
- 4.2 IEEE 부동소수점 포맷
- 4.3 정규화
- 4.4 라운딩
- 4.5 특별 부동소수점 값
- 4.6 부동소수점 예외
- 4.7 부동소수점 연산
- 4.8 더 많은 정보를 원한다면
- 5장. 문자 표기법
- 5.1 문자 데이터
- 5.2 문자열
- 5.3 문자셋
- 5.4 자신만의 문자셋 설계
- 5.5 더 많은 정보를 원한다면
- 6장 메모리 구조와 접근
- 6.1 기본 시스템 구성 요소
- 6.2 메모리의 물리적 구조
- 6.3 빅 엔디안 구조 vs. 리틀 엔디안 구조
- 6.4 시스템 클럭
- 6.5 CPU 메모리 접근
- 6.6 더 많은 정보를 원한다면
- 7장. 혼합 데이터 타입과 메모리 객체
- 7.1 포인터
- 7.2 배열
- 7.3 레코드/구조체
- 7.4 유니온
- 7.5 더 많은 정보를 원한다면
- 8장. 불리언 로직과 디지털 설계
- 8.1 불리언 대수
- 8.2 불리언 함수와 진리표
- 8.3 함수 번호
- 8.4 불리언 수식의 대수 처리
- 8.5 정규형
- 8.6 불리언 함수의 단순화
- 8.7 결국, 불리언 로직은 컴퓨터에 어떻게 적용되는가?
- 8.8 더 많은 정보를 원한다면
- 9장. CPU 구조
- 9.1 기본적인 CPU 설계
- 9.2 명령어의 해석과 수행: 랜덤 로직 vs. 마이크로코드
- 9.3 단계별 명령어 수행
- 9.4 더 높은 성능의 비결, 병렬성
- 9.5 더 많은 정보를 원한다면
- 10장. 명령어 집합 구조
- 10.1 명령어 집합 설계의 중요성
- 10.2 명령어 설계의 기본적인 목적
- 10.3 가상 프로세서 Y86
- 10.4 80x86 명령어 인코딩
- 10.5 명령어 집합 설계가 프로그래머에게 의미하는 것
- 10.6 더 많은 정보를 원한다면
- 11장. 메모리 구조와 구성
- 11.1 메모리 계층
- 11.2 메모리 계층의 동작방식
- 11.3 메모리 하위시스템에 존재하는 성능 차이
- 11.4 캐쉬의 구조
- 11.5 가상 메모리, 보호 장치, 페이징
- 11.6 스래싱
- 11.7 NUMA와 주변 장치들
- 11.8 메모리 계층을 고려한 소프트웨어 작성
- 11.9 실행 중 메모리의 구성 방식
- 11.10 더 많은 정보를 원한다면
- 12장. 입력과 출력
- 12.1 CPU를 외부와 연결
- 12.2 포트를 시스템에 연결하는 다른 방법들
- 12.3 입출력 메커니즘
- 12.4 입출력 속도 계층
- 12.5 시스템 버스와 각 데이터 전송률
- 12.6 버퍼링
- 12.7 핸드쉐이킹
- 12.8 입출력 포트의 타임아웃
- 12.9 인터럽트와 폴링
- 12.10 보호모드 연산과 장치 드라이버
- 12.11 PC 주변 장치
- 12.12 표준 PC 병렬 포트
- 12.13 직렬 포트
- 12.14 동기 I/O 와 비동기 I/O
- 12.15 I/O 형식의 의미
도서 오류 신고
정오표
정오표
[p.404: 그림 11-6]
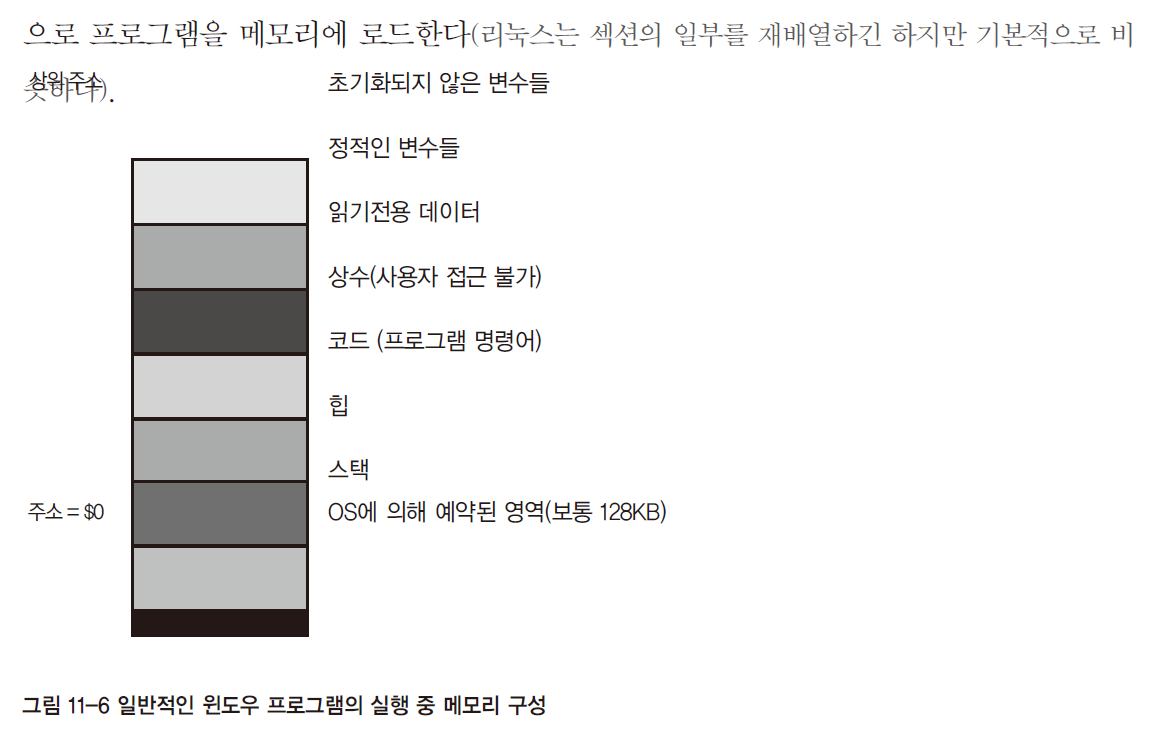
->
[p.90 코드 16행]
mov( packedDate, ax ); // 일(日)
and( $7f, al );
mov( al, year );
->
mov( packedDate, ax ); // 일(日)
shr( 7, ax );
and( %1_1111, al );
mov( al, day );
[p.94 그림 3-8]
오른쪽 12비트까지 색칠
->
오른쪽 13비트까지 색칠(한 칸 더)
[p.96 첫 번째 박스 코드]
Second.Field
->
ThirdField
[p.96 두 번째 박스 코드]
SecondField
->
ThirdField
[p. 97 두 번째 박스 2행]
shr( 21 , eax );
->
shr( 22, eax );
[p.102 아래서 5행]
0.001e0
->
0.01e0
[p.118 두 번째 박스 4행]
return ( (from & 0x7fffffff) I 0x800000 );
->
return ((from & 0x7FFFFF) | 0x800000 );
[p.118 세 번째 박스]
123.45el
->
123.45e1
[p.119 아래서 9행]
void shiftAncl.Round
->
void shiftAndRound
[p.119 아래서 3행]
0xlf
->
0x1f
[p.119 아래서 2행]
0xlff
->
0x1ff
[p.119 아래서 2행]
0xlfff
->
0x1fff
[p.119 아래서 1행]
0xlffff
->
0x1ffff
[p.119 아래서 1행]
0xlfffff
->
0x1fffff