


책 소개
요약
자연어 처리를 위한 AI 모델의 핵심 기술과 활용법에 대해서 다룬다. N-gram으로 접근하는 전통적인 모델 방식의 한계를 설명하고, AI 모델이 그 문제를 어떻게 해결할 수 있는지 설명한다. 어텐션 네트워크의 배경과 핵심 원리를 자세하게 설명하고 있고, 이 구조를 통해서 트랜스포머나 BERT 등의 구조를 설명한다. 또한 자연어 처리에 있어서 메타학습 방법도 간략하게 소개한다.
이 책에서 다루는 내용
◆ N-gram을 이용한 자연어 처리 기법
◆ 자연어 처리를 위한 RNN 기반의 AI 모델 구조 및 장단점
◆ 어텐션 네트워크의 탄생 배경과 핵심 원리
◆ 어텐션 네트워크를 활용한 트랜스포머의 구조
◆ BERT의 구조 및 사전학습/파인튜닝 방법
◆ BERT 이후의 AI 모델들
◆ 자연어 처리에 대한 메타러닝 방법
이 책의 대상 독자
어느 정도 파이썬 코드를 읽고 구현할 수 있으며 머신러닝에 대한 기초 역량이 있는 독자를 대상으로 저술했다. 파이썬을 접해본 적 없거나 머신러닝에 입문하는 독자가 공부하기에 어려울 수 있다.
이 책의 구성
1장에서는 언어 모델에 관한 내용을 다뤘다. 언어 모델이 무엇인지 확률적으로 정의한 후, N-gram 기법을 이용해서 언어 모델을 설명하고 그 과정을 코드를 통해 구현했다. 또한 N-gram 이후에 오랫동안 사용됐던 인공지능 모델인 RNN 계열의 인공지능 모델도 설명했다. RNN 계열의 언어 모델도 간단하게 학습해볼 수 있도록 샘플 코드를 구현했다.
2장에서는 어텐션에 대해서 자세하게 다뤘다. 어텐션은 트랜스포머의 핵심을 이루는 연산이다. 어텐션 연산을 RNN 계열에 추가했을 때 어떠한 장점이 있는지 설명했\하고 관련된 샘플 코드도 공부해볼 수 있도록 구현했다.
3장부터 본격적으로 트랜스포머의 구조를 다뤘다. 2장에서 다룬 어텐션을 기반으로 트랜스포머를 어떻게 구현했는지 구조적으로 설명했다.
4장에서는 BERT 모델에 대해서 설명했다. BERT를 사전 학습하는 방법에 대해서 소개했고, 사전학습된 모델을 파인튜닝하는 방법에 대해서도 소개하며 또한 BERT 이후에 발표된 개선된 모델도 몇 가지 소개했다.
5장에서는 GPT 계열의 모델을 설명했다. GPT2에서부터는 메타러닝의 개념이 추가된다. 자연어 처리에서 메타러닝이 왜 필요하고 어떤 방법으로 학습되는지 소개했다. 다만 GPT2/GPT3의 정확한 학습 방법은 공개되지 않았기 때문에 학습 과정은 코드로 구현하지 못했다.
마지막으로 부록에서는 딥러닝 모델의 양자화에 대해서 살펴본다. 딥러닝 모델의 성능이 비약적으로 발전했지만 그와 동시에 모델의 연산량과 파라미터 수도 굉장히 많아졌다. 큰 모델을 간단하게 경량화할 수 있는 방법으로 양자화가 있다. 부록에서는 양자화의 기본 원리에 대해서 다루고 4장에서 살펴본 BERT를 파인 튜닝해서 학습한 분류 모델을 경량화하는 내용을 다룬다.
상세 이미지

목차
목차
- 1장 다음 단어는요? 언어 모델
- 1.1. 언어 모델은 확률 게임
- 1.2. N-gram 언어 모델
- 1.2.1. 텍스트 전처리
- 1.2.2. 제로 카운트 해결하기
- 1.2.3. N-gram 모델 학습하기
- 1.2.4. N-gram 언어 모델의 한계
- 1.3. Word2Vec 기반의 언어 모델
- 1.4. RNN 기반의 언어 모델
- 1.4.1. RNN의 구조
- 1.4.2. GRU 언어 모델 구현하기
- 1.4.3. GRU 언어 모델로 문장 생성하기
- 2장 집중해 보자! 어텐션
- 2.1. 하나의 벡터로 모든 정보를 담는 RNN
- 2.2. 왜 어텐션(Attention)하지 않지?
- 2.3. 어떻게 어텐션(Attention)하지?
- 2.3.1. 묻고 참고하고 답하기
- 2.3.2. 어텐션 계산해 보기
- 2.3.3. 어텐션 구현하기
- 2.3.4 모델링 학습하기
- 3장 안녕, 트랜스포머
- 3.1. 트랜스포머의 구조
- 3.2. 트랜스포머 구현하기
- 3.2.1. 인코더
- 3.3. Why Transformer
- 3.4. 트랜스포머 학습 결과
- 3.4.1. Perplexity(PPL)
- 3.4.2. BLEU 스코어
- 4장 중간부터 학습하자! 사전학습과 파인튜닝
- 4.1. 사전학습과 Fine-Tuning
- 4.2. BERT
- 4.2.1. BERT의 모델 구조와 이해하기
- 4.2.2. BERT 모델의 입력 이해하기
- 4.2.3. 사전학습 이해하기
- 4.2.4. Masked Language Model(MLM)
- 4.2.5. Next Sentence Prediction(NSP)
- 4.2.6. 사전학습을 위한 데이터셋 준비와 Self-supervised Learning
- 4.2.7. 사전학습 파헤치기
- 4.2.8. 사전학습 정리하기
- 4.2.9. Fine-Tuning 이해하기
- 4.2.10. 텍스트 분류 모델로 파인튜닝하기
- 4.2.11. 질의응답 모델로 파인튜닝하기
- 4.3. GPT
- 4.3.1. GPT의 사전학습
- 4.3.2. Masked Self-Attention
- 4.4. RoBERTa
- 4.4.1. 정적 또는 동적 마스킹 전략
- 4.4.2. NSP 전략
- 4.4.3. 배치 사이즈와 데이터셋 크기
- 4.5. ALBERT
- 4.5.1. Factorized Embedding Parameterization
- 4.5.2. Cross-layer Parameter Sharing
- 4.5.3. Sentence Order Prediction(SOP)
- 4.5.4. ALBERT 정리
- 4.6. ELECTRA
- 4.6.1. 학습 구조
- 4.6.2. RTD
- 4.7. DistilBERT
- 4.7.1. 지식 증류
- 4.7.2. DistilBERT의 구조와 성능 비교
- 4.8. BigBird
- 4.8.1. 전체 문장에 대한 어텐션, 글로벌 어텐션
- 4.8.2. 가까운 단어에만 집중하기, 로컬 어텐션
- 4.8.3. 임의의 토큰에 대한 어텐션, 랜덤 어텐션
- 4.8.4. 토큰 길이에 따른 연산량 비교
- 4.9. 리포머
- 4.9.1. 트랜스포머 구조의 문제점
- 4.9.2. LSH 어텐션
- 4.9.3. Reversible 트랜스포머
- 4.10. GLUE 데이터셋
- 4.10.1. CoLA
- 4.10.2. SST-2 데이터셋
- 4.10.3. MRPC
- 4.10.4. QQP
- 4.10.5. STS-B
- 4.10.6. MNLI
- 4.10.7. QNLI
- 4.10.8. RTE
- 4.10.9. WNLI
- 4.10.10. GLUE 데이터셋의 평가 지표
- 5장 어떻게 배우지? 메타러닝
- 5.1. 학습을 위한 학습, 메타러닝
- 5.2. 메타러닝을 이용한 Amazon 리뷰 감정 분류 학습하기
- 5.2.1. 데이터셋과 데이터로더 만들기
- 5.3. GPT2에서의 메타러닝
- 5.3.1. GPT2를 학습하기 위한 접근 방법
- 5.3.2. GPT2의 학습 데이터셋과 멀티태스크
- 5.3.3. GPT2 성능 평가 결과
- 5.3.4. GP2를 통한 문장 생성
- 5.3.5. GPT2를 이용한 퓨샷 러닝
- 부록. 양자화
- 1.1. 양자화에 대한 수학적인 이해와 코드 구현
- 1.2. 양자화된 행렬을 이용한 행렬 곱셈과 덧셈
- 1.3. 동적 양자화와 정적 양자화
- 1.4. BERT 양자화하기
도서 오류 신고
정오표
정오표
[p.68 그림 2.10]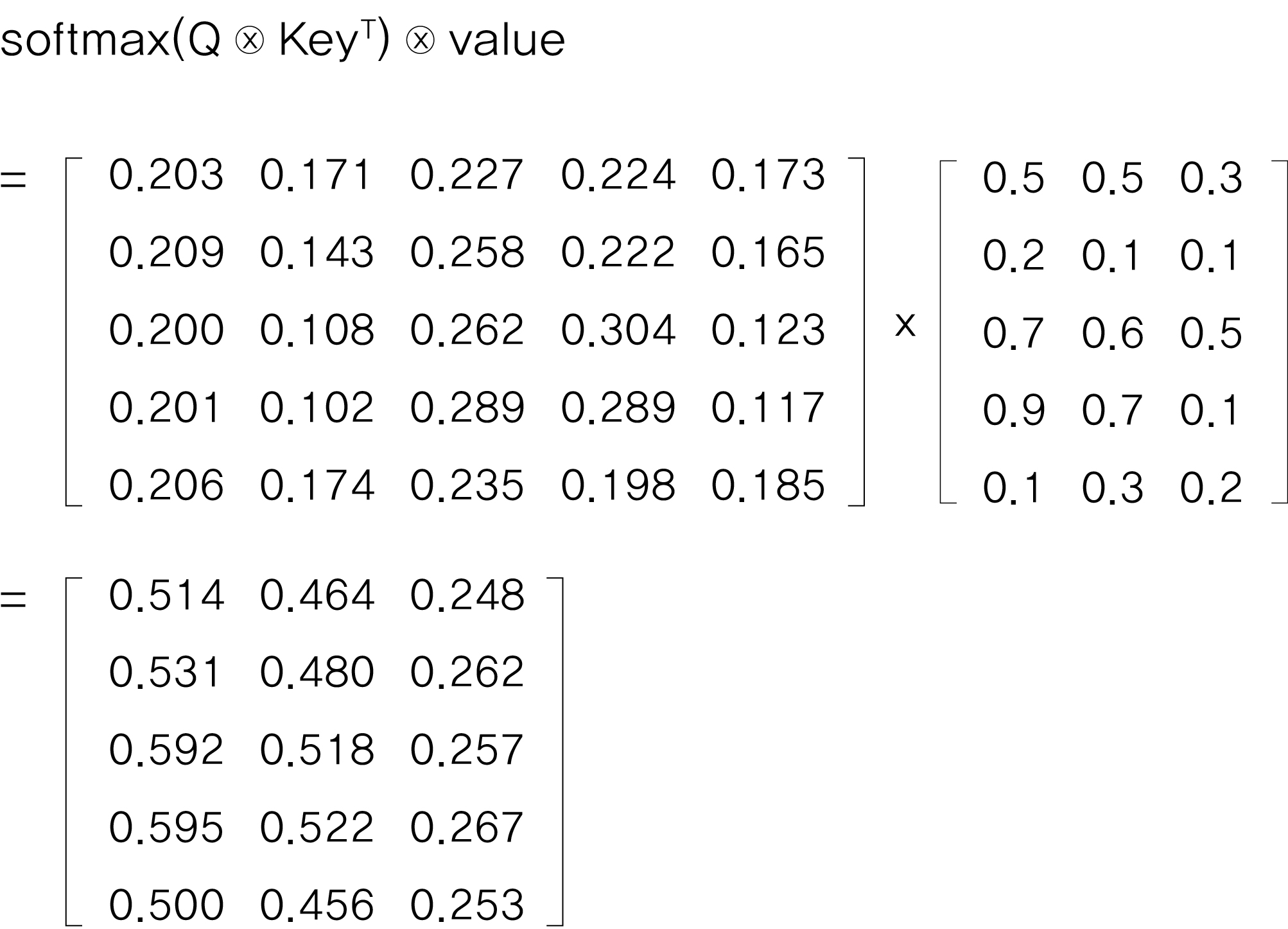
[ p.75 : 코드 2.6 아래에서 4행 ]
- output: (B,1,0)
->
- output: (B,M,H)
[p. 79 : 그림 2.12 ]
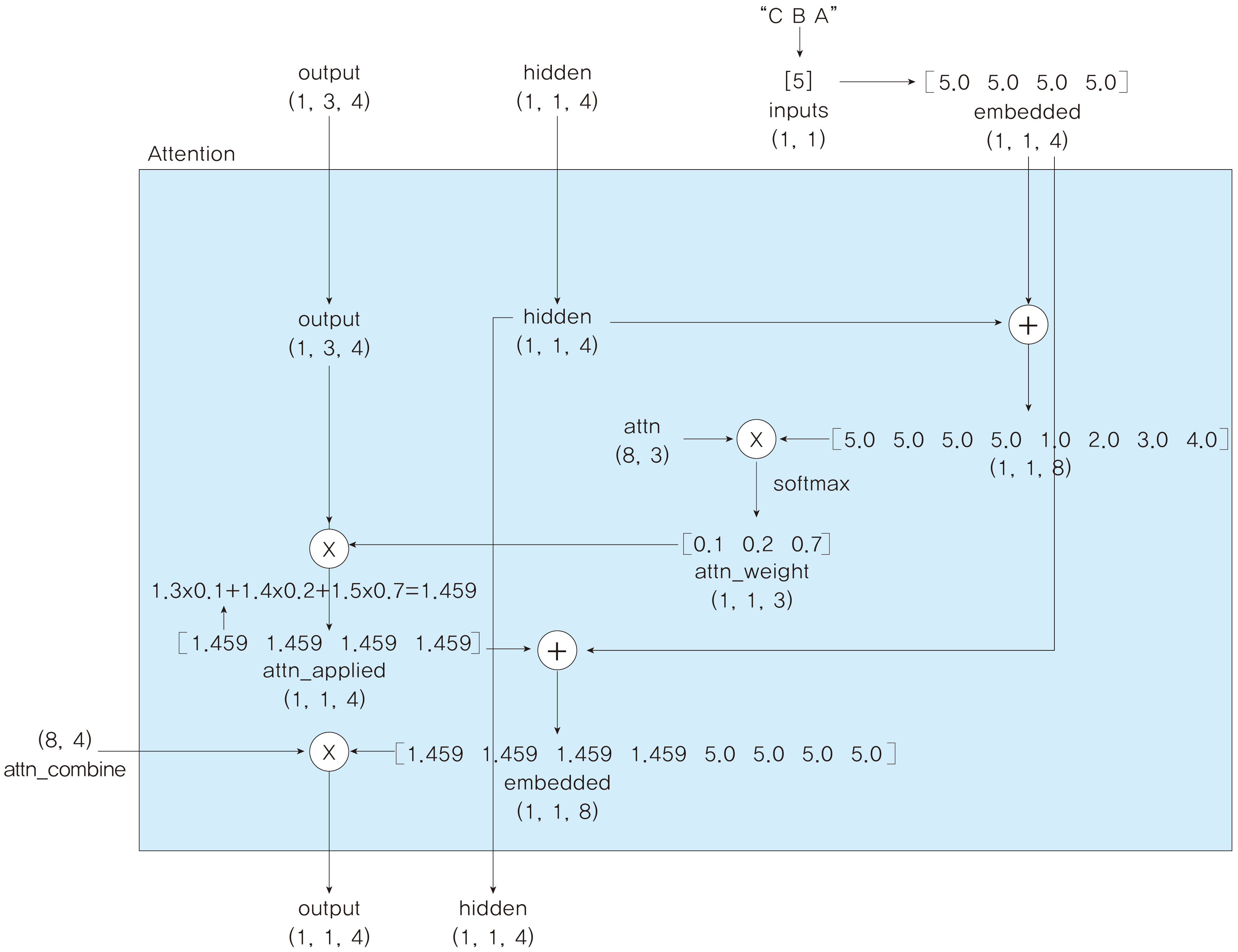
[p. 80 : 1행 ]
attn_applied와 hidden을
->
attn_applied와 embedded를
[p. 80 : 9행 ]
(batch_size, 1, hidden_size)
->
(1, batch_size, hidden_size)
[p. 80 : 그림 2.13 ]
hidden(B, 1, H)
->
hidden(1, B, H)
[p. 81 : 그림 2.14 ]
hidden(B, 1, H)
->
hidden(1, B, H)
[p. 81 : 그림 2.15 ]
hidden(B, 1, H)
->
hidden(1, B, H)
[p.93 : 그림 3.5]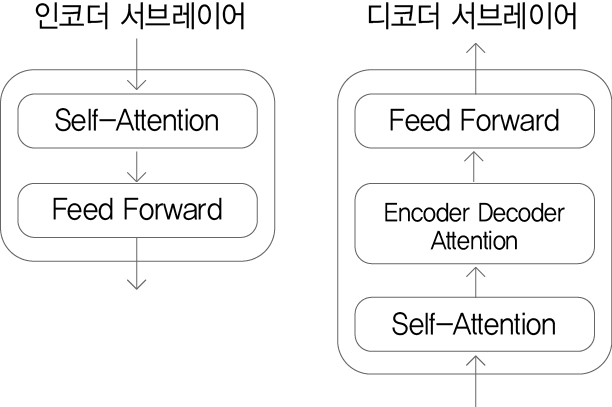
[ p.102 : 코드 3.5 ]
def forward(self, x, memory):
'''
data = np.random.randint(0, V, (B, M))
x = torch.from_numpy(data)
mem = torch.rand((B, M, H))
m = Decoder(L)
v = m(x, mem)
v.shape # torch.Size([64, 10, 512])
'''
x = self.embedding(x)
for layer in self.layers:
x = layer(x, memory)
return x
->
def forward(self, x, memory):
x = self.self_attention(x, x, x)
x = self.encdec_attention(x, memory, memory)
x = self.feedforward(x)
return x
[ p.120 : 아래에서 3행 ]
BERT의 구조는 3장에서 자세하게 설명했으므로
->
트랜스포머의 구조는 3장에서 자세하게 설명했으므로
[ p.121 : 그림 4.2 ]
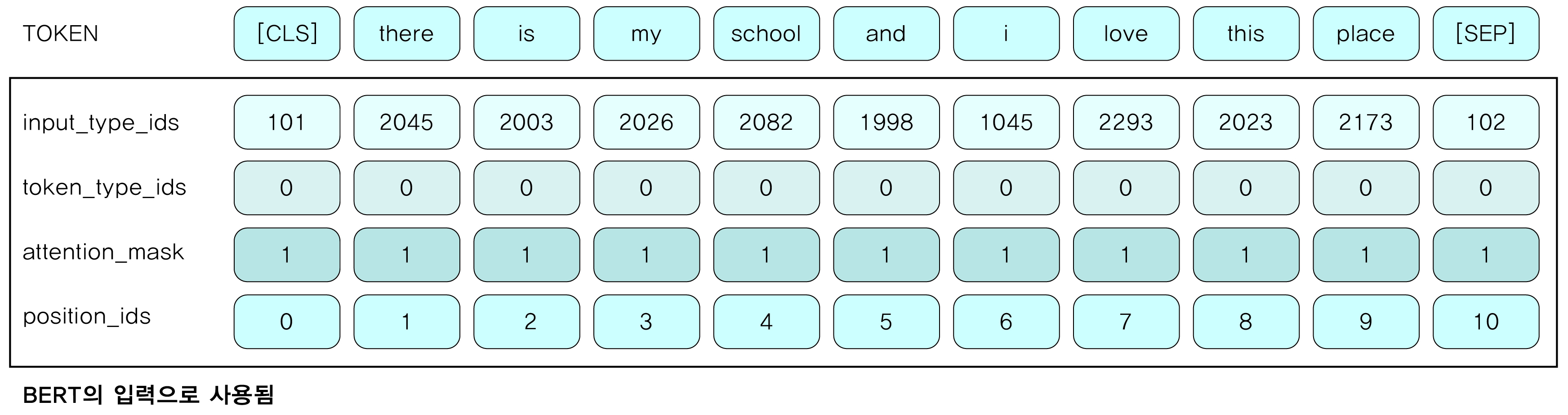
[ p.183 : 그림 4.24 ]
