자연어 처리의 정석 [자연어 처리의 A-Z 과거부터 최근 연구까지]
- 원서명Introduction to Natural Language Processing (ISBN 9780262042840)
- 지은이제이콥 에이젠슈테인(Jacob Eisenstein)
- 옮긴이이동근, 김근호
- ISBN : 9791161756455
- 50,000원
- 2022년 05월 30일 펴냄 (절판)
- 페이퍼백 | 690쪽 | 188*235mm
- 시리즈 : 데이터 과학
판매처
- 현재 이 도서는 구매할 수 없습니다.
책 소개
요약
자연어 처리와 머신러닝/딥러닝을 통합하고 해당 과정들을 자세하게 설명하는 책이다. 전통적인 통계 기반의 자연어 처리 방법에서 시작해 최근의 딥러닝/머신러닝 방법을 사용한 자연어 처리 방법까지 다룬다. 먼저, 지도/비지도학습과 관련한 머신러닝 방법론에 대해 설명한 후, 자연어 처리를 다루는 여러 알고리듬을 알아본다. 전통적인 알고리듬인 시퀀스, 트리, 그래프 등을 사용해서 어떻게 자연어를 다루는지 설명한다.
엔지니어와 연구자들이 자연어 처리를 다루기 위해 필요한 언어학 지식에 대해서도 충분히 알아본다. 형태소, 품사에서 시작해서 구조적 표현으로 컴퓨터가 인식하기 위한 연산으로 적용되는지 설명하며, 언어에 대한 형식적인 논리를 위한 방법부터 단어 임베딩까지 의미를 표현하고 해석하는 방법을 다룬다. 마지막에는 문서에서 정보를 추출하는 방법, 기계 번역, 텍스트를 직접 생성하는 것까지 최근의 응용 사례에 대한 방법까지 빼놓지 않고 이야기한다.
결과적으로 이 책은 머신러닝과 언어학을 자연어 처리라는 하나의 목표 아래 통합하며, 최근의 자연어 처리 연구를 이해하고 적용할 수 있도록 만들어주기에 더할 나위 없는 책이다.
추천의 글
“자연어 처리는 컴퓨터과학에서 매우 중요하며 빠르게 성장하고 있는 분야다. 근래에 자연어 처리 실무를 하려면 머신러닝 알고리듬과 언어학에 대한 이해가 꼭 필요하다. 저자 제이콥은 자연어 처리 분야에서 실제로 다루는 주요 방법과 응용의 핵심을 소개한다. 이 책은 데이터에 기반한 NLP에 대해 관심 있고 트렌드를 선도할 모든 학생과 연구자들의 갈증을 해소할 수 있는 기념비적인 작품이라 생각한다.”
— 알렉산더 러쉬(Alexander Rush)/
코넬대학교 컴퓨터과학과 교수 & Hugging Face 연구자
“자연어 처리를 배우는 모든 사람이 꼭 읽어야 할 책이다. 언어학적 기본 지식부터 최근의 딥러닝 알고리듬까지 많은 분야를 아우르는 통합된 시각을 제공한다. 또한 기술적으로 탄탄하면서 쉽게 이해할 수 있도록 쓴 책이다.”
— 루크 제틀모이어(Luke Zettlemoyer)/
워싱턴대학교 컴퓨터공학부 교수, 페이스북 AI 리서치 연구 책임자
“딥러닝 혁명이 시작된 이후로 자연어 처리에 관한 가장 포괄적이고 최신 자료로 구성된 책이다. 최신 AI와 NLP 알고리듬에 꼭 필요한 것에 대해 기본부터 응용된 내용까지 접할 수 있을 것이다.”
— 리차드 소처(Richard Socher)/
前 세일즈포스 책임 과학자, 現 you.com CEO
“이 책은 자연어 처리의 토대를 만드는 방법과 알고리듬을 위주로 탁월하게 설명한다. 자연어 처리를 연구하는 사람과 학생들에게 이 책을 강력하게 추천한다.”
— 휘 토우 응(Hwee Tou Ng)/
싱가포르국립대학교 컴퓨터과학과 교수
이 책에서 다루는 내용
이 책은 자연어 처리의 다양한 핵심 개념을 다룬다. 자연어 처리 작업을 위한 수많은 문제는 다음의 여러 방법을 사용해 해결할 수 있다.
◆ 탐색: 비터비 탐색, CKY 알고리듬, 스패닝 트리, 이동 감소, 정수 선형 프로그래밍, 빔 탐색
◆ 학습: 최대 우도 추정, 로지스틱 회귀, 퍼셉트론, 기댓값 - 최대화, 행렬 분해, 역전파
이 책에서는 이러한 방법들이 어떻게 동작하는지 설명하고, 광범위한 자연어 처리 작업에 어떻게 적용할 수 있을지 다뤄본다. 또한 문서 분류, 단어 의미 모호성, 품사 태깅, 개체명 인식, 파싱, 상호 참조 해결, 관계 추출, 담화 분석, 언어 모델링, 기계 번역 등과 같은 여러 자연어 처리 작업에 대해서 함께 다룬다.
이 책의 대상 독자
어느 정도 소프트웨어 지식이 있는 엔지니어와 대학원생 수준 이상의 연구자들에게 적합한 책이다. 각 장은 서로 독립돼 있지만 어느 순간 자연스레 통합되도록 구성됐다. 필요한 부분만 찾아서 읽어도 좋고, 전체를 하나씩 훑으며 큰 줄기를 잡는 것도 좋다.
이 책의 구성
기본적인 내용을 익힌 후, 다음의 4개 주요 영역을 다룬다.
◆ 학습: 다른 섹션에서 사용되는 여러 머신러닝 툴을 만들어볼 것이다. 머신러닝에 초점을 맞춰서 설명하기 때문에 텍스트 표현이나 언어학적인 현상들은 대부분 간단하다. “bag-of-words” 텍스트 분류를 예시 모델로 다룰 것이다. 4장에서는 단어 기반의 텍스트 분석에 관해 언어학적으로 흥미로운 응용 방법을 설명한다.
◆ 시퀀스와 트리: 언어를 구조학적인 현상에 비춰 설명하는 섹션이다. 시퀀스 및 트리 표현과 이들이 만들어내는 알고리듬에 대해 다루고 이러한 표현에서 발생되는 한계점에 대해서 설명한다. 9장에서는 유한 상태 오토마타(finite-state automata)에 대해 소개하고, 영어 구문론에서의 문맥 자유 언어를 짧게 소개한다.
◆ 의미: 형식 논리에서부터 뉴럴 단어 임베딩까지 텍스트를 통해 의미를 표현하고, 계산하기 위한 내용을 다룬다. 의미론과 밀접하게 관련 있는 참조 모호성을 해결하기 위한 방법과 담화 구조에서의 다문장 분석에 대한 두 가지 주제 등을 다룬다.
◆ 응용: 자연어 처리에 대한 주요한 응용 문제인 정보 추출, 기계 번역, 텍스트 생성에 대해 설명한다. 각 장에서 뉴럴 어텐션과 같은 방법을 소개하면서 이 책의 앞부분에서 구축한 형식과 방법을 사용해 가장 잘 알려진 시스템 중 일부를 설명한다.
목차
목차
- 1장. 개요
- 1.1 자연어 처리와 그 이웃들
- 1.2 자연어 처리의 세 가지 주제
- 2장. 선형 텍스트 분류
- 2.1 단어 가방
- 2.2 나이브 베이즈
- 2.3 결정 학습
- 2.4 손실함수와 큰 마진 분류
- 2.5 로지스틱 회귀
- 2.6 최적화
- 2.7 분류에서의 또 다른 주제들
- 2.8 학습 알고리듬 요약
- 3장. 비선형 분류
- 3.1 피드포워드 뉴럴 네트워크
- 3.2 뉴럴 네트워크 디자인하기
- 3.3 뉴럴 네트워크 학습하기
- 3.4 컨볼루셔널(합성곱) 뉴럴 네트워크
- 4장. 언어 기반의 분류 응용
- 4.1 감성 및 의견 분석
- 4.2 단어 의미의 모호성
- 4.3 텍스트 분류를 위한 의사 결정 디자인
- 4.4 분류기 평가하기
- 4.5 데이터 세트 만들기
- 5장. 비지도 학습
- 5.1 비지도 학습
- 5.2 기댓값 최대화의 적용
- 5.3 준지도 학습
- 5.4 도메인 적응
- 5.5 잠재변수가 있는 학습에 대한 여러 접근법
- 6장. 언어 모델
- 6.1 그램 언어 모델
- 6.2 평활화와 할인하기
- 6.3 순환 뉴럴 네트워크 언어 모델
- 6.4 언어 모델 평가하기
- 6.5 어휘집에 없는 단어
- 7장. 시퀀스 라벨링
- 7.1 분류에서의 시퀀스 라벨링
- 7.2 구조 예측을 위한 시퀀스 라벨링
- 7.3 비터비 알고리듬
- 7.4 은닉 마르코프 모델
- 7.5 피처를 사용한 결정하는 시퀀스 라벨링
- 7.6 뉴럴 시퀀스 라벨링
- 7.7 비지도 시퀀스 라벨링
- 8장. 시퀀스 라벨링 응용
- 8.1 품사 식별
- 8.2 형태구문론적 속성
- 8.3 개체명 인식
- 8.4 토크나이제이션
- 8.5 코드 스위칭
- 8.6 대화 행위
- 9장. 형식 언어론
- 9.1 정규 언어
- 9.2 문맥 자유 언어
- 9.3 가벼운 문맥 의존 언어
- 10장. 문맥 자유 파싱
- 10.1 결정형 상향식 파싱
- 10.2 모호성
- 10.3 가중치가 있는 문맥 자유 문법
- 10.4 가중치가 있는 문맥 자유 문법 학습하기
- 10.5 문법 보정
- 10.6 문맥 자유 파싱을 너머
- 11장. 의존 파싱
- 11.1 의존 문법
- 11.2 그래프 기반 의존 파싱
- 11.3 전이 기반 의존 파싱
- 11.4 응용
- 12장. 논리적 의미론
- 12.1 의미와 표기
- 12.2 의미의 논리적 표현
- 12.3 의미 파싱과 람다 대수
- 12.4 의미 파서 학습하기
- 13장. 술어 인자 의미론
- 13.1 의미 역할
- 13.2 의미 역할 라벨링
- 13.3 추상 의미 표현
- 14장. 분포 의미와 분산 의미
- 14.1 분포 가설
- 14.2 단어 표현을 위한 디자인 결정
- 14.3 잠재 의미 분석
- 14.4 브라운 군집
- 14.5 뉴럴 단어 임베딩
- 14.6 단어 임베딩 평가하기
- 14.7 분포 통계량 너머의 분포된 표현
- 14.8 다중 단어 단위의 분포된 표현
- 15장. 참조 해결
- 15.1 참조 표현의 형태
- 15.2 상호 참조 해결을 위한 알고리듬
- 15.3 상호 참조 해결 표현하기
- 15.4 상호 참조 해결 평가하기
- 16장. 담화
- 16.1 분절
- 16.2 개체와 언급
- 16.3 관계
- 17장. 정보 추출
- 17.1 개체
- 17.2 관계
- 17.3 사건
- 17.4 헤지, 부정, 가정
- 17.5 질의 응답과 기계 독해
- 18장. 기계 번역
- 18.1 기계 번역 작업
- 18.2 통계적 기계 번역
- 18.3 뉴럴 기계 번역
- 18.4 디코딩
- 18.5 평가 지표 훈련
- 19장. 텍스트 생성
- 19.1 데이터를 통한 텍스트 생성
- 19.2 텍스트를 통한 텍스트 생성
- 19.3 대화
- 부록 A. 확률
- A.1 사건 조합의 확률
- A.2 조건부 확률과 베이즈 규칙
- A.3 독립
- A.4 확률변수
- A.5 기댓값
- A.6 모델링과 추정
- 부록 B. 수치 최적화
- B.1 경사 하강
- B.2 제약 조건이 있는 최적화
- B.3 예시: 수동적 — 능동적 온라인 학습
도서 오류 신고
정오표
정오표
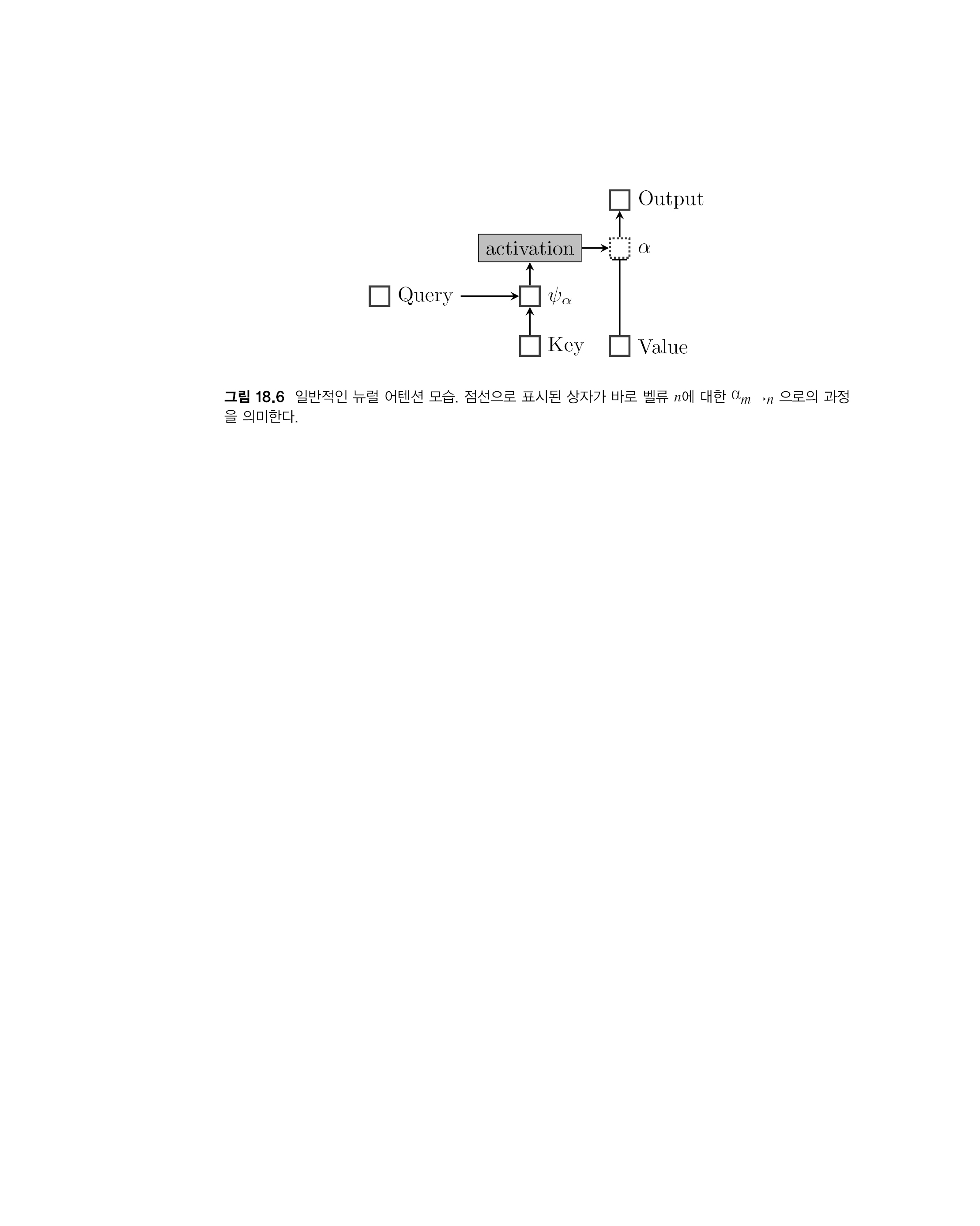
[p.574 : 그림 18.6]