책 소개
[ 소개 ]
이 책은 커널 코드를 개발하고 작성하는 사람뿐 아니라, 운영체제에 대한 이해를 높여 좀 더 효율적이고 생산적인 코드를 작성하고자 하는 개발자에게 도움이 되도록, 리눅스 커널 설계와 구현에 대해 자세히 다룬다.
이 책에서는 리눅스 커널의 설계, 구현, 인터페이스를 비롯한 커널의 주요 하부 시스템 및 기능에 대해 자세히 다룬다. 리눅스 커널에 대한 실용적인 관점과 이론적인 관점을 모두 제공하는 이 책은 다양한 관심과 필요성을 가진 독자들의 흥미를 끌 것이다.
핵심 커널 개발자이기도 한 저자는 2.6 커널에 대한 소중한 지식과 경험을 나누고자 한다. 구체적으로 프로세스 관리, 스케줄링, 시간 관리 및 타이머, 시스템 호출 인터페이스, 메모리 접근, 메모리 관리, 페이지 캐시, VFS, 커널 동기화, 이식성 문제, 디버깅 기법 등을 다룬다. 이 책에서는 2.6 커널의 가장 흥미로운 기능인 CFS 스케줄러, 선점 커널, 블럭 입출력 계층, 입출력 스케줄러 등의 내용도 다룬다.
[ 개정 3판에서 달라진 내용 ]
■ 커널 자료 구조를 별도 장으로 새로 추가
■ 인터럽트 핸들러와 후반부 처리에 대한 자세한 내용
■ 커널 동기화 및 잠금에 대한 깊이 있는 설명
■ 가상 메모리와 메모리 할당에 대한 설명 보강
■ 리눅스 커널 디버깅 시 도움이 되는 기법
■ 커널 패치를 제출할 때 유용한 노하우와 리눅스 커널 공동체와 함께 일하는 방법
[ 이 책의 대상 독자 ]
이 책은 리눅스 커널을 이해하고자 하는 소프트웨어 개발자를 대상으로 쓰여졌다. 이 책은 커널 소스를 줄 단위로 설명하는 해설서가 아니다. 또한 드라이버 개발을 위한 가이드도, 커널 API 참고도서도 아니다. 이 책의 목적은 리눅스 커널의 설계와 구현에 대한 충분한 정보를 제공하여, 프로그래머가 커널 코드 개발을 시작할 수 있게 해주는 것이다. 커널 개발은 재미있고 보람찬 일이므로, 나는 독자를 가능한 한 순조롭게 이 세상으로 이끌고자 한다. 이 책은 학구적인 독자와 실용적인 독자 모두를 만족시키기 위해 이론과 응용 모두를 다룬다. 나는 항상 응용을 이해하려면 이론부터 이해해야 한다고 생각하지만, 이 책에서는 둘 사이의 균형을 맞추려고 노력했다. 여러분이 리눅스 커널을 공부하려는 동기가 무엇이든, 이 책의 커널 설계와 구현에 대한 설명이 여러분의 필요를 충분히 만족시킬 수 있기를 바란다.
이 책은 핵심 커널 시스템의 동작 방법과 그 설계 및 구현을 모두 다룬다. 중요한 부분이므로 잠시 설명하고 넘어가자. 좋은 예가 바로 후반부 처리(bottom half)를 이용하는 장치 드라이버 구성 요소를 다루는 8장 ’후반부 처리와 지연된 작업’이다. 이 장에서는 (핵심 커널 개발자나 학구적인 독자가 관심을 가질 만한) 커널 후반부 처리의 설계와 구현에 대해서 다루고, (장치 드라이버 개발자나 통상적인 해커가 흥미를 느낄 만한) 커널이 제공하는 인터페이스를 이용해 실제 후반부 처리를 구현하는 방법에 대해서도 다룬다. 양측 모두 두 가지 측면의 논의가 필수적이라는 사실을 알 수 있을 것이다. 커널의 내부 작동 방식을 확실히 알고 있어야 하는 핵심 커널 개발자는 인터페이스가 실제 사용되는 방식에 대해서도 잘 알고 있어야 한다. 그와 동시에, 장치 드라이버 개발자 역시 인터페이스 너머의 내부 구현에 대해 이해함으로써 드라이버 개발 작업에 도움을 받을 수 있다.
이는 라이브러리의 API를 배우는 것과 라이브러리의 실제 구현을 공부하는 것의 관계와 비슷하다. 언뜻 보기에 애플리케이션 개발자는 API만 알면 될 것 같다. 사실 인터페이스를 블랙박스처럼 다루어야 한다고 배우는 경우가 많다. 마찬가지로 라이브러리 개발자는 라이브러리 설계와 구현에 대해서만 신경 쓴다. 하지만 나는 양자 모두가 서로 반대편 사정을 이해하기 위해 노력해야 한다고 생각한다. 하부 운영체제를 잘 이해하는 애플리케이션 개발자는 운영체제를 훨씬 더 잘 활용할 수 있다. 마찬가지로 라이브러리 개발자는 라이브러리를 이용하는 애플리케이션이 처한 현실과 실제 상황을 외면해서는 안 된다. 따라서 이 책이 양쪽 사람들에게 유용하기를 바랄 뿐 아니라, 책 내용 전체가 양측에 도움이 되기를 바라는 마음으로 커널 서브시스템의 설계와 구현 모두를 설명할 것이다.
나는 독자들이 C 프로그래밍에 대해 알고 있으며, 리눅스에 익숙하다고 가정했다. 운영체제 설계나 다른 전산 분야의 개념에 대한 경험이 있으면 도움이 되겠지만, 이런 개념들에 대해 최대한 많이 설명하려고 노력했다. 부족하다면, 운영체제 설계에 대한 훌륭한 책이 포함된 참고 문헌 항목을 살펴보라.
이 책은 학부 수준의 운영체제 설계 과목에서 이론을 다루는 입문서와 함께 응용 분야의 보조 교과서로 활용하기에 적합하다. 또한 이 책은 별도의 교재 없이 고급 학부 과목이나 대학원 수준의 과목에서도 사용할 수 있다.
[ 추천의 글 ]
리눅스 커널과 커널 애플리케이션 사용이 늘어남에 따라 리눅스 개발과 유지보수에 참여하려는 시스템 소프트웨어 개발자도 점점 늘어는 추세다. 이들 중에는 순전히 개인적인 관심으로 리눅스 개발에 참여하는 사람도 있고, 리눅스 기업 또는 하드웨어 제조사에서 일하기 때문에 혹은 기업 내에서 개발 프로젝트를 하기 때문에 참여하는 사람도 있다.
하지만 이들은 모두 공통된 문제에 부딪힌다. 커널을 배우는 데 걸리는 시간이 더 길어지고, 어려워지고 있다는 점이다. 시스템은 매우 크고, 더욱 더 복잡해지고 있다. 시간이 지날수록 지금 커널을 개발하는 개발자들은 커널에 대해 더욱 깊고 넓은 지식을 쌓을 수 있겠지만, 새로 참여하는 사람과의 격차는 더 벌어질 수밖에 없다.
나는 이렇게 커널 소스에 대한 접근이 점점 어려워지는 현실이 커널의 품질(quality)에 이미 문제를 일으키고 있으며, 이 문제는 시간이 지남에 따라 더 심해질 것이라고 생각한다. 리눅스의 앞날을 걱정하는 사람이라면 커널 개발에 참여할 수 있는 개발자들의 수를 늘리는 일에도 반드시 관심을 기울여야 한다.
이 문제를 해결하는 방법 중 하나는 깔끔한 코드를 유지하는 것이다. 이해하기 쉬운 인터페이스, 일관성 있는 레이아웃, ‘한 번에 한 가지만, 제대로 한다’ 등과 같은 원칙을 지키는 일이다. 이것이 리누스 토발즈가 선택한 방법이다.
내가 추천하는 또 한 가지 방법은 코드에 많은 주석을 다는 것이다. 주석은 코드를 읽는 사람이 개발자가 개발 당시 무엇을 얻고자 했는지 이해할 수 있을 만큼 충분해야 한다. 의도와 구현의 차이를 파악하는 과정이 바로 디버깅이다. 의도를 알 수 없다면 디버깅은 어려운 일이 된다.
하지만 주석만으로는 주요 서브시스템이 어떤 일을 해야 하는지 전체를 살펴볼 수 있는 시각과 개발자들이 그 목적을 달성하려고 어떤 방법을 사용했는지에 대한 정보를 얻을 수 없다. 따라서 커널을 이해하기 위한 출발점으로는 가장 필요한 것은 잘 작성된 문서다.
로버트 러브(Robert Love)가 쓴 이 책은 숙련된 개발자만이 알 수 있는 커널 서브시스템에 대한 본질적인 이해와, 이를 구현하려고 개발자들이 어떤 일들을 했는지에 대해 알려준다. 따라서 이 책은 호기심에 커널을 공부하려는 사람들뿐 아니라, 애플리케이션 개발자, 커널 설계를 분석하려는 사람 등 많은 사람에게 충분한 지식을 제공해 줄 수 있다.
또한, 이 책은 커널 개발자가 뚜렷한 목적을 가지고 커널을 수정할 수 있는 다음 단계로 나아가는 데도 도움을 준다. 나는 이런 개발자들에게 많은 시도를 해 볼 것을 권한다. 커널의 특정 부분을 이해하는 가장 좋은 방법은 그 부분을 변경해보는 것이다. 커널을 직접 수정해보면 코드를 읽기만 할 때는 볼 수 없었던 많은 것들을 이해할 수 있다. 더 적극적인 커널 개발자라면 개발자 메일링 리스트에 가입해 다른 개발자들과 의견을 나눠 보는 것도 좋다. 이 방식이 바로 그 동안 커널 개발에 기여한 사람들이 커널을 배웠던, 그리고 계속 배우고 있는 방법이기도 하다. 로버트의 책은 커널 개발의 중요한 부분인 이런 체계와 문화에 대해서도 다룬다.
로버트의 책을 즐기고, 또 많은 것을 배울 수 있기를 바란다. 또 여러분 중 많은 사람이 한발 더 나아가 커널 개발 공동체의 일원이 되기를 진심으로 바란다. 우리는 사람을 공헌도에 따라 평가한다. 여러분이 무언가 리눅스에 기여하게 되었을 때 여러분의 작업으로 얻어진 지식도 수억 아니, 수십억의 인류에게 작지만 즉각적인 도움을 주었다고 평가받을 수 있을 것이다. 이것은 우리에게 주어진 아주 유익한 특권이면서 책임이기도 하다.
- 앤드류 모튼(Andrew Morton)
목차
목차
- 1장 리눅스 커널 입문
- 유닉스의 역사
- 리눅스의 개발
- 운영체제와 커널
- 리눅스 커널과 전통적인 유닉스 커널
- 리눅스 커널 버전
- 리눅스 커널 개발 공동체
- 시작하기 전에
- 2장 커널과의 첫 만남
- 커널 소스 구하기
- Git 사용하기
- 커널 소스 설치
- 패치
- 커널 소스 트리
- 커널 빌드
- 커널 설정
- 빌드 메시지 최소화
- 빌드 작업을 동시에 여러 개 실행
- 새 커널 설치
- 다른 성질의 야수
- libc와 표준 헤더 파일을 사용할 수 없음
- GNU C
- 인라인 함수
- 인라인 어셈블리
- 분기 구문표시
- 메모리 보호 없음
- 부동 소수점을 (쉽게) 사용할 수 없음
- 작은 고정 크기의 스택
- 동기화와 동시성
- 이식성의 중요성
- 결론
- 3장 프로세스 관리
- 프로세스
- 프로세스 서술자와 태스크 구조체
- 프로세스 서술자의 할당
- 프로세스 서술자 저장
- 프로세스 상태
- 현재 프로세스 상태 조작
- 프로세스 컨텍스트
- 프로세스 계층 트리
- 프로세스 생성
- Copy-on-Write
- 프로세스 생성(forking)
- vfork()
- 리눅스의 스레드 구현
- 스레드 생성
- 커널 스레드
- 프로세스 종료
- 프로세스 서술자 제거
- 부모 없는 태스크의 딜레마
- 결론
- 4장 프로세스 스케줄링
- 멀티태스킹
- 리눅스의 프로세스 스케줄러
- 정책
- 입출력중심 프로세스와 프로세서중심 프로세스
- 프로세스 우선순위
- 타임슬라이스
- 스케줄러 정책의 동작
- 리눅스 스케줄링 알고리즘
- 스케줄러 클래스
- 유닉스 시스템의 프로세스 스케줄링
- 공정 스케줄링
- 리눅스 스케줄링 구현
- 시간 기록
- 스케줄러 단위 구조체
- 가상 실행시간
- 프로세스 선택
- 다음 작업 선택
- 트리에 프로세스 추가
- 트리에서 프로세스 제거
- 스케줄러 진입 위치
- 휴면과 깨어남
- 대기열
- 깨어남
- 선점과 컨텍스트 전환
- 사용자 선점
- 커널 선점
- 실시간 스케줄링 정책
- 스케줄러 관련 시스템 호출
- 스케줄링 정책과 우선순위 관련 시스템 호출
- 프로세서 지속성(affinity) 관련 시스템 호출
- 프로세서 시간 양보
- 결론
- 5장 시스템 호출
- 커널과 통신
- API, POSIX, C 라이브러리
- 시스콜
- 시스템 호출 번호
- 시스템 호출 성능
- 시스템 호출 핸들러
- 알맞은 시스템 호출 찾기
- 매개변수 전달
- 시스템 호출 구현
- 시스템 호출 구현
- 매개변수 검사
- 시스템 호출 컨텍스트
- 시스템 호출 등록을 위한 마지막 단계
- 사용자 공간에서 시스템 호출 사용
- 시스템 호출을 구현하지 말아야 하는 이유
- 결론
- 6장 커널 자료 구조
- 연결 리스트
- 단일 연결 리스트와 이중 연결 리스트
- 환형 연결 리스트
- 연결 리스트 내에서 이동
- 리눅스 커널의 구현 방식
- 연결 리스트 구조체
- 연결 리스트 정의
- 리스트 헤드
- 연결 리스트 조작
- 연결 리스트에 노드 추가
- 연결 리스트에서 노드 제거
- 연결 리스트의 노드 이동과 병합
- 연결 리스트 탐색
- 기본 방식
- 실제 사용하는 방식
- 역방향으로 리스트 탐색
- 제거하면서 탐색
- 다른 연결 리스트 함수
- 큐
- kfifo
- 큐 생성
- 데이터를 큐에 넣기
- 데이터를 큐에서 빼기
- 큐의 크기 알아내기
- 큐 재설정과 큐 삭제
- 큐 사용 예제
- 맵
- idr 초기화
- 새로운 UID 할당
- UID 찾기
- UID 제거
- idr 제거
- 이진 트리
- 이진 탐색 트리
- 자가 균형 이진 탐색 트리
- 레드블랙 트리
- rbtree
- 어떤 자료 구조를 언제 사용할 것인가?
- 알고리즘 복잡도
- 알고리즘
- O(빅오, 대문자오) 표기법
- 빅 세타 표기법
- 시간 복잡도
- 결론
- 7장 인터럽트와 인터럽트 핸들러
- 인터럽트와 인터럽트 핸들러
- 전반부 처리와 후반부 처리
- 인터럽트 핸들러 등록
- 인터럽트 핸들러 플래그
- 인터럽트 예제
- 인터럽트 핸들러 해제
- 인터럽트 핸들러 작성
- 공유 핸들러
- 인터럽트 핸들러의 실제 예
- 인터럽트 컨텍스트
- 인터럽트 핸들러 구현
- /proc/interrupts
- 인터럽트 제어
- 인터럽트 활성화와 비활성화
- 특정 인터럽트 비활성화
- 인터럽트 시스템 상태
- 결론
- 8장 후반부 처리와 지연된 작업
- 후반부 처리bottom half
- 왜 후반부 처리를 하는가?
- 후반부 처리의 세계
- 원래의 ‘후반부 처리’
- 태스크 큐
- softirq와 태스크릿
- 혼란스러움을 떨쳐내기
- softirq
- softirq 구현
- softirq 핸들러
- softirq 실행
- softirq 사용
- 인덱스 할당
- 핸들러 등록
- softirq 올림
- 태스크릿tasklet
- 태스크릿 구현
- 태스크릿 구조체
- 태스크릿 스케줄링
- 태스크릿 사용
- 태스크릿 선언
- 태스크릿 핸들러 작성
- 태스크릿 스케줄링
- ksoftirqd
- 구식 BH 처리 방식
- 워크 큐
- 워크 큐 구현
- 스레드 표현 자료 구조
- 작업 표현 자료 구조
- 워크 큐 구현 정리
- 워크 큐 사용
- 작업 생성
- 워크 큐 핸들러
- 작업 스케줄링
- 작업 비우기
- 새로운 워크 큐 만들기
- 구식 태스크 큐 방식
- 어떤 후반부 처리 방식을 사용할 것인가?
- 후반부 처리 작업 사이의 락
- 후반부 처리 비활성화
- 결론
- 9장 커널 동기화 개요
- 위험 지역과 경쟁 조건
- 왜 보호 장치가 필요한가?
- 단일 변수
- 락
- 동시성의 원인
- 보호 대상 인식
- 데드락
- 경쟁과 확장성
- 결론
- 10장 커널 동기화 방법
- 원자적 동작
- 원자적 정수 연산
- 64비트 원자적 연산
- 원자적 비트 연산
- 스핀락
- 스핀락 사용 방법
- 그 밖의 스핀락 함수
- 스핀락과 후반부 처리
- 리더−라이터 스핀락
- 세마포어
- 카운팅 세마포어와 바이너리 세마포어
- 세마포어 생성과 초기화
- 세마포어
- 리더-라이터 세마포어
- 뮤텍스(mutex)
- 세마포어와 뮤텍스
- 스핀락과 뮤텍스
- 완료 변수
- 큰 커널 락
- 순차적 락
- 선점 비활성화
- 순차성(ordering)과 배리어(barrier)
- 결론
- 11장 타이머와 시간 관리
- 커널의 시간의 개념
- 진동수: HZ
- 이상적인 HZ 값
- 큰 HZ 값의 장점
- 큰 HZ 값의 단점
- 지피(jiffies)
- 지피의 내부 표현
- 지피 값 되돌아감
- 사용자 공간과 HZ 값
- 하드웨어 시계와 타이머
- 실시간 시계
- 시스템 타이머
- 타이머 인터럽트 핸들러
- 날짜와 시간
- 타이머
- 타이머 사용
- 타이머 경쟁 조건
- 타이머 구현
- 실행 지연
- 루프 반복
- 작은 지연
- schedule_timeout()
- schedule_timeout() 구현
- 만료시간을 가지고 대기열에서 휴면
- 결론
- 12장 메모리 관리
- 페이지
- 구역
- 페이지 얻기
- 0으로 채워진 페이지 얻기
- 페이지 반환
- kmalloc()
- gfp_mask 플래그
- 동작 지정자
- 구역 지정자
- 형식 플래그
- kfree()
- vmalloc()
- 슬랩 계층
- 슬랩 계층 설계
- 슬랩 할당자 인터페이스
- 캐시에서 할당
- 슬랩 할당자 사용 예제
- 스택에 정적으로 할당
- 단일 페이지 커널 스택
- 공정하게 스택 사용
- 상위 메모리 연결
- 고정 연결
- 임시 연결
- CPU별 할당
- 새로운 percpu 인터페이스
- 컴파일 시점의 CPU별 데이터
- 실행 시점의 CPU별 데이터
- CPU별 데이터를 사용하는 이유
- 할당 방법 선택
- 결론
- 13장 가상 파일시스템
- 일반 파일시스템 인터페이스
- 파일시스템 추상화 계층
- 유닉스 파일시스템
- VFS 객체와 자료 구조
- 슈퍼블록 객체
- 슈퍼블록 동작
- 아이노드 객체
- 아이노드 동작
- 덴트리 객체
- 덴트리 상태
- 덴트리 캐시
- 덴트리 동작
- 파일 객체
- 파일 동작
- 파일시스템 관련 자료 구조
- 프로세스 관련 자료구조
- 결론
- 14장 블록 입출력 계층
- 블록 장치 구조
- 버퍼와 버퍼 헤드
- bio 구조체
- 입출력 벡터
- 신구 버전 비교
- 요청 큐
- 입출력 스케줄러
- 입출력 스케줄러가 하는 일
- 리누스 엘리베이터
- 데드라인 입출력 스케줄러
- 예측 입출력 스케줄러
- 완전 공정 큐 입출력 스케줄러
- 무동작 입출력 스케줄러
- 입출력 스케줄러 선택
- 결론
- 15장 프로세스 주소 공간
- 주소 공간
- 메모리 서술자
- 메모리 서술자 할당
- 메모리 서술자 해제
- mm_struct 구조체와 커널 스레드
- 가상 메모리 영역
- VMA 플래그
- VMA 동작
- 메모리 영역 리스트와 트리
- 실제 메모리 영역
- 메모리 영역 다루기
- find_vma()
- findvmaprev()
- findvmaintersection()
- mmap()와 do_mmap(): 주소 범위 생성
- munmap()와 do_munmap(): 주소 범위 해제
- 페이지 테이블
- 결론
- 16장 페이지 캐시와 페이지 지연 기록
- 캐시 사용 방식
- 쓰기 캐시
- 캐시 축출
- 가장 오래 전에 사용한 항목 제거
- 이중 리스트 전략
- 리눅스 페이지 캐시
- address_space 객체
- address_space 동작
- 기수 트리
- 구식 페이지 해시 테이블
- 버퍼 캐시
- 플러시 스레드
- 랩탑 모드
- 역사: bdflush, kupdated, pdflush
- 다중 스레드 환경의 경쟁 상태 회피
- 결론
- 17장 장치와 모듈
- 장치 유형
- 모듈
- Hello, World!
- 모듈 만들기
- 소스 트리에 들어 있는 경우
- 소스 트리 외부에 있는 경우
- 모듈 설치
- 모듈 의존성 생성
- 모듈 적재
- 설정 옵션 관리
- 모듈 인자
- 노출 심볼exported symbols
- 장치 모델
- Kobjects
- Ktypes
- Ksets
- kobject, ktype, kset의 상관 관계
- kobject 관리와 변경
- 참조 횟수
- 참조 횟수 증감
- krefs
- sysfs
- sysfs에 kobject 추가와 제거
- sysfs에 파일 추가
- 기본 속성
- 새로운 속성 만들기
- 속성 제거
- sysfs 관례
- 커널 이벤트 계층
- 결론
- 18장 디버깅
- 시작하기
- 커널 버그
- 출력을 이용한 디버깅
- 견고함
- 로그수준
- 로그 버퍼
- syslogd와 klogd
- printf()와 printk() 사용 혼동
- 웁스
- ksymoops
- kallsyms
- 커널 디버깅 옵션
- 버그 확인과 정보 추출
- 만능 SysRq 키
- 커널 디버거의 전설
- gdb
- kgdb
- 시스템 찔러 보기와 조사
- 조건에 따른 UID 사용
- 조건 변수
- 통계
- 디버깅 작업의 빈도와 발생 제한
- 문제를 일으킨 변경 사항을 찾기 위한 이진 탐색
- Git을 사용한 이진 탐색
- 모든 방법이 실패했을 때: 공동체
- 결론
- 19장 이식성
- 이식성 있는 운영체제
- 리눅스 이식성의 역사
- 워드 크기와 데이터 형
- 불투명 데이터 형
- 특수 데이터 형
- 명시적으로 크기가 정해진 데이터 형
- 문자 데이터 형의 부호유무
- 데이터 정렬
- 정렬 문제 피하기
- 비표준 데이터 형의 정렬
- 구조체 채우기
- 바이트 순서
- 시간
- 페이지 크기
- 프로세서 순서
- SMP, 커널 선점, 상위 메모리
- 결론
- 20장 패치, 해킹, 공동체
- 공동체
- 리눅스 코딩 스타일
- 들여쓰기
- switch 구문
- 공백
- 괄호
- 줄 길이
- 명명 방식
- 함수
- 주석
- 형 지정
- 기존 함수 사용
- 소스에서 ifdef 사용 최소화
- 구조체 초기화
- 과거에 작성한 코드 소급 적용
- 지휘 계통
- 버그 리포트 제출
- 패치
- 패치 만들기
- Git을 사용해 패치 생성
- 패치 제출
도서 오류 신고
정오표
정오표
1쇄 오류/오탈자
[ p38 6행 ]
1944년 → 1994년
[ p105 12행 ]
5번씩 → 두 번
[ p140 4행 ]
시스템 호출 핸들러는 비슷한 이름이 시스템 호출과 systemcall() 함수로 구현된다.
→ 시스템 호출 핸들러는 그 역할에 걸맞은 이름을 가진 systemcall() 함수로 구현되어 있다.
[ p250 첫 번째 박스 아래로 3행 ]
실행자지 않고 일정 시간이 지단 → 실행하지 않고 일정 시간이 지난
[ p250 아래에서 4행 ]
제거되기 전이 → 제거되기 전에
[ p 139 시스템 호출 성능에서 3행 ]
시스템 호출 핸들러 몇 개별 시스템 호출 자체가 → 시스템 호출 핸들러 및 개별 호출 자체가
[ p 280 표 10.1 에서 12행과 13행 ]
int atomic inc return(int i, atomict *v) → int atomicincreturn(atomict *v)
int atomicdecreturn(int i, atomict *v) → int atomicdecreturn(atomict *v)
[ p 283 표 10.2 에서 5행, 6행 ]
inlong atomic64increturn(int i, atomic64t *v) → inlong atomic64increturn(atomic64t *v)
inlong atomic64decreturn(int i, atomic64t *v) → inlong atomic64decreturn(atomic64t *v)
[ p329 첫 번째 박스 아래로 6행 ]
falase를 반환한다. → false를 반환한다.
[ p375 본문 11행 ]
kmempages() → kmemgetpages()
[ p388 두 번째 박스 안 4행 ]
if (!ptr) →if (!percpu_ptr)
1.5쇄 오류/오탈자
[ p102 9~10행 ]
리눅스에서 프로세스에 할당되는 프로세스 시간은 → 리눅스에서 프로세스에 할당되는 프로세서 시간은
[ p102 20행 ]
많은 비율의 프로세스 시간을 → 많은 비율의 프로세서 시간을
[ p161, 162 코드 ]
struct list_headlist → struct list_head
[ p248 2행 ]
프로세스당 → 프로세서당
[ P 359 8행 ]
앞 절에서 gfpt형과 gfpmask인자에 대해 알아 보았다.
→ gfpt형과 gdpmask인자에 대해서는 이후 절에서 알아 보겠다.
2015-08-24
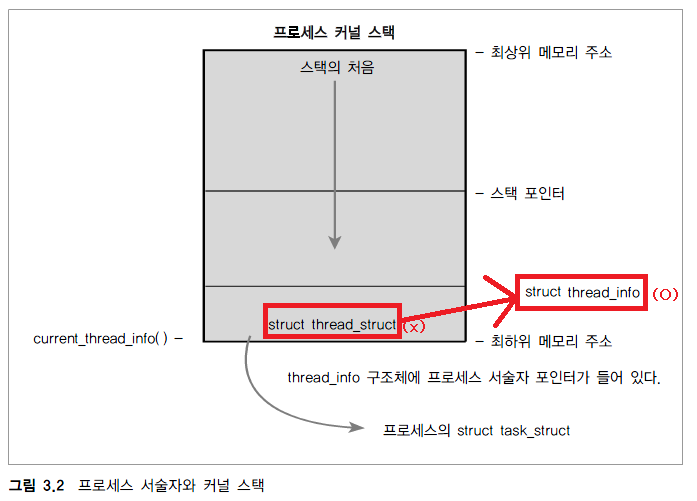
그림3.2 struct threadstruct → struct threadinfo