


Machine Learning 머신 러닝
- 원서명Machine Learning: A Probabilistic Perspective (ISBN 9780262018029)
- 지은이케빈 머피(Kevin P. Murphy)
- 옮긴이노영찬, 김기성
- ISBN : 9788960777491
- 60,000원
- 2015년 08월 31일 펴냄
- 페이퍼백 | 1,288쪽 | 188*255mm
- 시리즈 : 데이터 과학
판매처
개정판책 소개
개발 도구 github.com/probml/pmtk3
지원 파일 pmtksupport.googlecode.com
2016년 대한민국학술원 우수학술도서 선정도서
요약
전사적 형태의 데이터가 증가함에 따라, 데이터 분석을 위한 자동화 방식의 필요성이 증가하고 있다. 머신 러닝(Machine Learning)의 목표는 데이터 패턴을 감지, 향후 데이터 예측을 위해 드러나지 않은 패턴을 사용할 수 있는 방법을 개발한다. 이 책은 수 세기 동안 통계학과 공학의 중심이 된 확률 이론을 사용하는 데이터로부터 습득될 수 있는 머신을 만들기 위한 최적의 방식을 채택한다. 즉 기본적인 원칙에 입각한 모델에 기초해서 머신 러닝에 접근하도록 강조한다. 전반적으로 확률론적 모델링(Probabilistic Modeling)이 먼저 고려될 것이다. 실질적인 접근으로 이 책의 모든 방법은 확률적 모델의 개발 도구인 PMTK(Probabilistic Modeling Toolkit)라고 부르는 매트랩(MATLAB) 소프트웨어 패키지에서 구현된다.
이 책에 쏟아진 찬사
“놀라운 머신 러닝 책이다! 직관적이며 풍부한 예제, 흥미로움, 하지만 여전히 종합적이며 심도있는 책! 이 분야에 관심이 있거나 관련 분야를 전공하는 대학생에게 좋은 시작점이 될 것이다.”
-잔 피터스(Jan Peters) / 다름슈타트 공과대학(Darmstadt University of Technology), 막스플랑크 지능 시스템 연구소(Max-Planck Institute for Intelligent Systems)
“케빈 머피는 실제 사례 연구와 예제를 통해 동기를 부여하며, 복잡한 머신 러닝을 풀어내는 전문가다. 책에서 제공하는 소프트웨어 패키지는 많은 그림에 대한 소스코드를 제공하며, 독자 스스로 이런 방법을 검색하고 연구에 몰두하게 만든다. 머신 러닝에 관심이 있고, 빅 데이터로부터 유용한 지식을 어떻게 도출하는지 궁금하다면 이 책을 꼭 읽어야 한다."
-존 윈(John Winn) / 마이크로소프트(Microsoft) 연구원
“이 책은 통계학 모형에서 기본 개념부터 시작해 가장 진보된 주제를 다루는 훌륭한 책이다. 확률 머신 러닝의 이론적 기초와 매트랩 코드에 의한 실제 도구, 둘 다 제공한다. 이 분야의 전문가와 이 분야에 관심이 있는 학생들은 언제든지 참고할 수 있도록 늘 곁에 둬야 한다.”
-요람 싱어(Yoram Singer) / 구글(Google) 연구원
“이 책은 현대 머신 러닝 전문가들을 위한 기본 참고서가 될 것이다. 전체적인 이해를 위해 필요한 기본 개념을 잘 다루고 있으며, 이런 개념을 기반으로 하는 현재의 강력한 방법을 다룬다. 머신 러닝에서 확률과 통계학의 언어는 외견상으로 분리된 알고리즘과 전략 사이에서 중요한 연결을 드러낸다. 따라서 독자들은 최신 기술을 사용하는 전체론적 관점에서 명확한 표현을 할 수 있게 되며, 다음 세대의 머신 러닝 알고리즘 설계를 위한 준비를 할 수 있다.”
-데이빗 블라이(David Blei) / 컬럼비아 대학교(Columbia University) 교수
이 책에서 다루는 내용
오늘날 웹 기반의 방대한 전사적 데이터는 분석을 위한 자동화 방법을 요구한다. 머신 러닝은 이러한 방법을 제공하며, 데이터 패턴을 자동으로 감지하는 방법을 개발하고 향후 데이터를 예측하기 위해 발견되지 않은 방식을 사용한다. 이 책은 머신 러닝과 통일된 확률적 접근의 분야를 포괄적이고도 독립적으로 소개한다.
적용 범위는 너비와 깊이를 통합하고, 확률과 최적화, 선형 대수학과 최근에 개발된 조건 임의의 필드와 L1 일반화, 딥 러닝(deep learning) 같은 토픽에 필요한 배경 지식을 제공한다. 또한 가장 중요한 알고리즘을 비롯해 일반적인 언어를 사용하며, 접근하기 쉬운 형태로 쓰여졌다. 모든 주제는 이미지와 생물학, 문자 처리, 컴퓨터 비전, 로봇공학 같은 응용 분야에서 유도되는 예를 풍부하게 설명한다. 다른 경험적 방법을 제공하는 책보다는 원칙에 따른 모형 기반 접근을 강조하며, 함축적이며 직관적인 방법으로 모형을 지정하기 위해 그래픽 모형 언어를 사용한다. 매트랩(MATLAB) 소프트웨어 패키지(PMTK)에서 수행되는 거의 모든 모형을 다루며, 이는 온라인으로도 이용할 수 있다. 이 책은 대학 수학 정도의 배경 지식을 가진 대학교 3, 4학년 학생이나 대학원생에게 적합하다.
이 책의 대상 독자
이 책은 컴퓨터 과학, 통계학, 전자공학, 계량경제학, 수학적 배경 지식을 요구하는 대학교 3, 4학년과 대학원 공부를 시작하는 학생들에게 적합하다. 특히 독자가 고등 미적분과 선형 대수학, 컴퓨터 프로그래밍에 대한 기초 지식을 갖고 있다는 전제하에 구성했다. 통계학을 이미 경험했다면 많은 도움이 되겠지만, 사전 지식이 꼭 필요하지는 않다.
이 책의 구성
전사적 형태의 데이터가 증가함에 따라 데이터 분석을 위한 자동화 방식의 필요성이 날로 증가하고 있다. 머신 러닝의 목표는 데이터의 패턴을 자동으로 감지하고, 향후 데이터를 예상하기 위해 아직 드러나지 않은 패턴을 사용하며, 다른 상호 연관된 결과물을 사용하도록 한다. 따라서 머신 러닝은 통계학, 데이터 마이닝(data mining)과 밀접하게 연관돼 있으며, 어디에 역점을 두는지와 용어에 따라 약간의 차이점이 있다. 이 책은 그러한 분야에 대해 상세하게 소개하며, 분자 생물학, 문장 처리(text processing), 컴퓨터 비전(computer vision), 로봇 공학 같은 응용 분야에서 드러나는 예제를 포함한다.
확률론적 접근
이 책은 수 세기 동안 통계학과 공학의 중심이 된 확률 이론의 도구를 사용하는 데이터로부터 습득할 수 있는 머신을 만들기 위해 최적의 방식을 채택한다. 확률 이론은 불확실성과 연관된 문제에 적용될 수 있다. 머신 러닝에서 불확실성은 ‘주어진 데이터로 할 수 있는 최상의 예상(결정)은 무엇인가?’, ‘주어진 데이터로 할 수 있는 최상의 모델은 무엇인가?’, ‘내가 다음에 수행할 수 있는 수치는 무엇인가?’ 등의 형태로 발생할 수 있다. 통계학 모델의 추론적 변수를 포함하는 모든 추론적 문제의 확률 논리에 대한 조직적 응용은 베이지안 방법(Bayesian approach)이라고 부른다. 하지만 이 용어는 매우 강한 반향(요청자에 따라 긍정 또는 부정으로 표현)을 끌어내는 경향이 있기 때문에 좀 더 중립적인 용어인 ‘확률론적 접근(probabilistic approach)’이란 표현을 선호한다. 더욱이 베이지안 방법이 아닌 확률론적 개연성의 패러다임 안에서 확실하게 발생할 수 있는 최대 가능도 추정(Maximum Likelihood Estimation)과 같은 기술을 자주 사용할 것이다.
이 책은 서로 다른 경험적 방법을 설명하기보다는 기본적인 원칙에 입각한 모델에 기초 해서 머신 러닝에 접근하도록 강조한다. 어떤 주어진 모델에 대해 다양한 알고리즘이 적용될 수 있다. 반대로, 주어진 어떤 알고리즘이 다양한 모델에 적용될 수 있다. 알고리즘에서 모델을 구별하는 모듈성(modularity)은 좋은 교수법이며, 공학에도 많은 도움이 된다. 간결하고 직관적인 방식으로 모델을 명시하기 위한 그래픽 모델의 언어도 사용할 것이다. 추가적인 이해를 돕기 위해 그래프 구조는 우리가 관찰하게 될 효과적인 알고리즘을 개발하는 데 도움이 될 것이다. 하지만 이 책은 그래픽 모델에 대한 고려가 우선이 아니며, 전반적으로 확률론적 모델링을 먼저 고려한다.
목차
목차
- 1장 소개
- 1.1 머신 러닝: 무엇을 그리고 왜?
- 1.1.1 머신 러닝의 종류
- 1.2 감독 학습
- 1.2.1 분류
- 1.2.2 회귀
- 1.3 자율 학습
- 1.3.1 군집 발견
- 1.3.2. 잠재 요인의 발견
- 1.3.3 그래프 구조 발견
- 1.3.4 매트릭스 완성
- 1.4 머신 러닝의 기초 개념
- 1.4.1 모수적 모형과 비모수적 모형
- 1.4.2 단순한 비모수적 분류기: K 근접 이웃
- 1.4.3 차원의 저주
- 1.4.4 분류와 회귀에 대한 모수적 모형
- 1.4.5 선형 회귀
- 1.4.6 로지스틱 회귀 분석
- 1.4.7 과대적합
- 1.4.8 모형 선택
- 1.4.9 공짜 점심은 없다는 이론
- 연습문제
- 2장 확률
- 2.1 소개
- 2.2 확률 이론에 대한 간단한 리뷰
- 2.2.1 이산 확률 변수
- 2.2.2 근본적 규칙
- 2.2.3 베이즈 법칙
- 2.2.4 독립과 조건부 독립
- 2.2.5 연속형 확률 변수
- 2.2.6 분위수
- 2.2.7 평균과 분산
- 2.3 보편적 이산형 분포
- 2.3.1 이항 분포와 베르누이 분포
- 2.3.2 다항 분포와 멀티누이 분포
- 2.3.3 푸아송 분포
- 2.3.4 경험적 분포
- 2.4 보편적인 연속 분포
- 2.4.1 가우시안(정규) 분포
- 2.4.2 퇴화 pdf
- 2.4.3 라플라스 분포
- 2.4.4 감마 분포
- 2.4.5 베타 분포
- 2.4.6 파레토 분포
- 2.5 결합 확률 분포
- 2.5.1 공분산과 상관
- 2.5.2 다변수 가우시안
- 2.5.3 다변수 스튜던트 t 분포
- 2.5.4 디리클레/디리슈레 분포
- 2.6 확률 변수의 변환
- 2.6.1 선형 변환
- 2.6.2 일반 변환
- 2.6.3 중심 극한 정리
- 2.7 몬테카를로 예측
- 2.7.1 예: 변수 변환
- 2.7.2 예: 몬테카를로 적분으로 π를 예측
- 2.7.3 몬테카를로 계산의 정확성
- 2.8 정보 이론
- 2.8.1 엔트로피
- 2.8.2 쿨백-라이블러 발산
- 2.8.3 상호 정보량
- 연습문제
- 3장 이산 데이터를 위한 생성 모형
- 3.1 소개
- 3.2 베이지안 개념 학습
- 3.2.1 발생 가능성
- 3.2.2 사전 확률
- 3.2.3 사후 확률
- 3.2.4 사후 예측 분포
- 3.2.5 더 복잡한 사전 확률
- 3.3 베타 이항 모델
- 3.3.1 발생 가능도
- 3.3.2 사전 확률
- 3.3.3 사후 확률
- 3.3.4 사후 예측 분포
- 3.4 디리클레-다항 분포 모형
- 3.4.1 발생 가능도
- 3.4.2 사전 확률
- 3.4.3 사후 확률
- 3.4.4 사후 예측
- 3.5 나이브 베이즈 분류기
- 3.5.1 모형 피팅
- 3.5.2 예측을 위한 모형 사용
- 3.5.3 로그-합-지수 트릭
- 3.5.4 상호 정보를 사용하는 특징 선택
- 3.5.5 백 오브 워드를 사용하는 문서 분류
- 연습문제
- 4장 가우시안 모델
- 4.1 소개
- 4.4.1 표기법
- 4.1.2 기초
- 4.1.3 MVN에 대한 MLE
- 4.1.4 가우시안의 최대 엔트로피 도출
- 4.2 가우시안 판별 분석
- 4.2.1 이차 판별 분석
- 4.2.2 선형 판별 분석
- 4.2.3 두 개 클래스에 대한 LDA
- 4.2.4 판별 분석에 대한 MLE
- 4.2.5 과적합을 막는 전략
- 4.2.6 정칙화 LDA
- 4.2.7 대각 LDA
- 4.2.8 근접 슈렁큰 중심 분류기
- 4.3 결합 가우시안 분포에서 추정
- 4.3.1 결과의 정리
- 4.3.2 예제
- 4.3.3 정보 형태
- 4.3.4 결과의 증명
- 4.4 선형 가우시안 시스템
- 4.4.1 결과의 진술
- 4.4.2 예제
- 4.4.3 결과의 증명
- 4.5 위샤트 분포
- 4.5.1 역위샤트 분포
- 4.5.2 위샤트 분포 시각화
- 4.6 MVN의 파라미터 추정
- 4.6.1 μ의 사후 분산
- 4.6.2 Σ의 사후 분포
- 4.6.3. μ와 Σ의 사후 분포
- 4.6.4 알려지지 않은 정밀도를 가진 센서 융합
- 연습문제
- 5장 베이지안 통계학
- 5.1 소개
- 5.2 사후 확률 분포 요약
- 5.2.1 MAP 예측
- 5.2.2 신뢰 구간
- 5.2.3 안분 비례의 차이에 대한 추정
- 5.3 베이지안 모형 선택
- 5.3.1 베이지안 오캄의 면도날
- 5.3.2 주변 발생 가능도 계산
- 5.3.3 베이즈 요인
- 5.3.4 제프리스-린들리의 역설
- 5.4 사전 확률
- 5.4.1 무정보 사전 확률
- 5.4.2 제프리스 사전 확률
- 5.4.3 견고한 사전 확률
- 5.4.4 결합 사전 확률의 혼합
- 5.5 계층적 베이즈
- 5.5.1 예제: 암 발생 비율과 관련된 모형화
- 5.6 경험적 베이즈
- 5.6.1 예제: 베타 이항 모형
- 5.6.2. 예제: 가우시안-가우시안 모형
- 5.7 베이지안 결정 이론
- 5.7.1 일반적 손실 함수를 위한 베이즈 추정량
- 5.7.2 거짓 양성과 거짓 음성의 교환
- 5.7.3 다른 토픽
- 연습문제
- 6장 빈도주의자 통계학
- 6.1 소개
- 6.2 추정량의 표본 분포
- 6.2.1 부트스트랩
- 6.2.2 MLE에 대한 대표본 이론
- 6.3 빈도주의자 결정 이론
- 6.3.1 베이즈 위험
- 6.3.2 미니맥스 위험
- 6.3.3 허용 가능 추정량
- 6.4 추정량의 요구되는 특성
- 6.4.1 일치 추정량
- 6.4.2 편향되지 않은 추정량
- 6.4.3 최소 분산 추정량
- 6.4.4 편향 분산 상충
- 6.5 경험적 위험 최소화
- 6.5.1 일반화된 위험 최소화
- 6.5.2 구조화 위험 최소화
- 6.5.3 교차 검증을 사용한 위험 추정
- 6.5.4 통계적 학습 이론을 사용한 상한 위험
- 6.5.5 대리 손실 함수
- 6.6 빈도주의자 통계학의 병적 측면
- 6.6.1 신뢰 구간의 반직관적 행동
- 6.6.2 p 값의 해로움
- 6.6.3 발생 가능도 원칙
- 6.6.4 모든 사람이 베이지안주의가 아닌 이유
- 연습문제
- 7장 선형 회귀
- 7.1 소개
- 7.2 모형 특정화
- 7.3 최대 발생 가능도 추정
- 7.3.1 MLE의 도출
- 7.3.2 기하학적 해석
- 7.3.3 볼록성/컨벡서티
- 7.4 견고한 선형 회귀
- 7.5 능선 회귀
- 7.5.1 기본 개념
- 7.5.2 산술적으로 안정된 계산
- 7.5.3 PCA와 연관성
- 7.5.4 빅데이터의 정형화 효과
- 7.6 베이지안 선형 회귀
- 7.6.1 사후 확률 계산
- 7.6.2 사후 예측 계산
- 7.6.3 σ2이 알려지지 않을 때 베이지안 추정
- 7.6.3.2 무정보 사전 확률
- 7.6.4 선형 회귀에 대한 EB
- 연습문제
- 8장 로지스틱 회귀
- 8.1 소개
- 8.2 모형 상세
- 8.3 모형 적합
- 8.3.1 MLE
- 8.3.2 최급강하
- 8.3.3 뉴턴의 방법
- 8.3.4 반복 재가중 최소 제곱
- 8.3.5 준뉴턴 방법
- 8.3.6 ℓ2 일반화
- 8.3.7 다중 클래스 로지스틱 회귀
- 8.4 베이지안 로지스틱 회귀
- 8.4.1 라플라스 근사
- 8.4.2 BIC의 유도
- 8.4.3 로지스틱 회귀에 대한 가우시안 근사
- 8.4.4 사후 확률 예측의 근사
- 8.4.5 잔차 분석
- 8.5 온라인 학습과 확률 최적화
- 8.5.1 온라인 학습과 후회 최소화
- 8.5.2 확률적 최적화와 위험 최소화
- 8.5.3 LMS 알고리즘
- 8.5.4 퍼셉트론 알고리즘
- 8.5.5 베이지안 관점
- 8.6 생성과 판별 분류기
- 8.6.1 각 접근 방법의 장단점
- 8.6.2 누락된 데이터의 취급
- 8.6.3 피셔의 선형 판별 분석(FLDA)
- 연습문제
- 9장 일반화 선형 모델과 지수족
- 9.1 소개
- 9.2 지수족
- 9.2.1 정의
- 9.2.2 예제
- 9.2.2.3 일변량 가우시안
- 9.2.3 로그 분할 함수
- 9.2.4 지수족에 대한 MLE
- 9.2.5 지수족에 대한 베이즈
- 9.2.6 지수족의 최대 엔트로피 유도
- 9.3 일반화 선형 모형(GLM)
- 9.3.1 기본개념
- 9.3.2 ML과 MAP 예측
- 9.3.3 베이지안 추정
- 9.4 프로빗 회귀
- 9.4.1 기울기 기초 최적화를 사용한 ML/MAP 추정
- 9.4.2 잠재 변수 해석
- 9.4.3 순서 프로빗 회귀
- 9.4.4 다항 프로빗 모형
- 9.5 다중 임무 학습
- 9.5.1 다중 임무 학습에 대한 계층적 베이즈
- 9.5.2 이메일 스팸 필터링 애플리케이션
- 9.5.3 영역 적응 애플리케이션
- 9.5.4 사전 확률의 다른 종류
- 9.6 일반화 선형 혼합 모형
- 9.6.1 예제: 의료 데이터에 대한 준모수적 GLMM
- 9.6.2 계산적 이슈
- 9.7 랭킹 학습
- 9.7.1 점별 접근
- 9.7.2 쌍으로 접근
- 9.7.3 일률적 접근
- 9.7.4 랭킹 손실 함수
- 연습문제
- 10장 직접 그래픽 모형(베이즈 네트)
- 10.1 소개
- 10.1.1 연쇄 법칙
- 10.1.2 조건적 독립
- 10.1.3 그래픽 모형
- 10.1.4 그래프 용어
- 10.1.5 유향 그래픽 모형
- 10.2 예제
- 10.2.1 네이브 베이즈 분류기
- 10.2.2 마르코프와 숨겨진 마르코프 모형
- 10.2.3 의학 진단(Medical diagnosis)
- 10.2.4 유전자 연관 분석
- 10.2.5 방향 가우시안 그래픽 모형
- 10.3 추론
- 10.4 학습
- 10.4.1 플레이트 표기법
- 10.4.2 완전 자료의 학습
- 10.4.3 누락 및 잠재 변수를 이용한 학습
- 10.5 DGM의 조건 독립 성질
- 10.5.1 d 분류와 베이즈 볼 알고리즘(전역 Markov 특성)
- 10.5.2 DGM의 다른 마르코프 특성
- 10.5.3 마르코프 블랭킷과 전체 조건
- 10.6 영향(결정) 다이어그램
- 연습문제
- 11장 혼합 모형과 EM 알고리즘
- 11.1 잠재 변수 모형
- 11.2 혼합 모형
- 11.2.1 혼합 가우시안
- 11.2.2 멀티누이 혼합
- 11.2.3 클러스터링을 위한 혼합 모형 사용
- 11.2.4 전문가의 혼합
- 11.3 혼합 모형에 대한 모수 예측
- 11.3.1 비식별 가능성
- 11.3.2 MAP 예측 계산은 비볼록
- 11.4 EM 알고리즘
- 11.4.1 기본 개념
- 11.4.2 GMM에 대한 EM
- 11.4.3 혼합 전문가에 대한 EM
- 11.4.4 숨겨진 변수를 가진 DGM에 대한 EM
- 11.4.5 스튜던트 분포에 대한 EM
- 11.4.6 프로빗 회귀에 대한 EM
- 11.4.7 EM에 대한 이론적 기초
- 11.4.8 온라인 EM
- 11.4.9 다른 EM
- 11.5 잠재 변수 모형에 대한 모형 선택
- 11.5.1 확률 모형에 대한 모형 선택
- 11.5.2 비확률 모형에 대한 모형 선택
- 11.6 누락 데이터를 가진 적합 모형
- 11.6.1 누락 데이터를 가진 MVN의 MLE에 대한 EM
- 연습문제
- 12장 잠재 선형 모형
- 12.1 요인 분석
- 12.1.1 FA는 MVN의 낮은 순위 모수화
- 12.1.2 잠재 요인의 추정
- 12.1.3 비식별 가능성
- 12.1.4 혼합 인자 분석기
- 12.1.5 인자 분석 모형에 대한 EM
- 12.1.6 FA 모형을 누락된 데이터에 적합하게 적용
- 12.2 주요인 분석(PCA)
- 12.2.1 고전적 PCA: 이론의 정리
- 12.2.2 증명
- 12.2.3 특이 값 분해(SVD)
- 12.2.4 확률적 PCA
- 12.2.5 PCA에 대한 EM 알고리즘
- 12.3 잠재된 차원의 개수를 선택
- 12.3.1 FA/PPCA에 대한 모형 선택
- 12.3.2 PCA에 대한 모형 선택
- 12.4 범주형 데이터에 대한 PCA
- 12.5 페어와 멀티뷰 데이터에 대한 PCA
- 12.5.1 감독 PCA(잠재 변수 회귀)
- 12.5.2 부분 최소 제곱
- 12.5.3 정 준상관 분석
- 12.6 독립 성분 기법(ICA)
- 12.6.1 최대 발생 가능도 추정
- 12.6.2 FastICA 알고리즘
- 12.6.3 EM 사용
- 12.6.4 다른 예측 분석
- 연습문제
- 13장 희박 선형 모형
- 13.1 소개
- 13.2 베이지안 변수 선택
- 13.2.1 스파이크와 슬래브 모형
- 13.2.2 베르누이-가우시안 모형에서 정규화
- 13.2.3 알고리즘
- 13.3 일반화: 개념
- 13.3.1 ℓ1 일반화가 희박한 해결 방법을 산출하는 이유
- 13.3.2 라쏘를 위한 최적 조건
- 13.3.3 최소 제곱과 라쏘, 리지, 부분집합 선택의 비교
- 13.3.4 일반화 경로
- 13.3.5 모형 선택
- 13.3.6 라플라스 사전을 가진 선형 모형에 대한 베이지안 추정
- 13.4 ℓ1 일반화: 알고리즘
- 13.4.1 좌표 하강
- 13.4.2 LARS와 다른 호모토피 방법
- 13.4.3 근접 미분 벡터 투영법
- 13.4.4 라쏘에 대한 EM
- 13.5 ℓ1 일반화: 확장
- 13.5.1 그룹 라쏘
- 13.5.2 퓨즈 라소
- 13.5.3 탄성 네트(리지와 라쏘의 합성)
- 13.6 비볼록 정규화
- 13.6.1 브리지 회귀
- 13.6.2 계층적 적응 라쏘
- 13.6.3 다른 계층적 사전
- 13.7 자동 연관 결정(ARD)/희박 베이지안 학습(SBL)
- 13.7.1 선형 회귀에 대한 ARD
- 13.7.2 희박이 어디서부터 발생하는가?
- 13.7.3 MAP 예측으로 연결
- 13.7.4 ARD 알고리즘
- 13.7.5 로지스틱 회귀에 대한 ARD
- 13.8 희박 코딩
- 13.8.1 희박 코딩 사전 학습
- 13.8.2 이미지 패치로부터 사전 학습의 결과
- 13.8.3 압축 센싱(Compressed sensing)
- 13.8.4 이미지 복원과 잡음 제어
- 연습문제
- 14장 커널
- 14.1 소개
- 14.2 커널 함수
- 14.2.1 RBF 커널
- 14.2.2 문서 비교를 위한 커널
- 14.2.3 Mercer(양수 한정) 커널
- 14.2.4 선형 커널
- 14.2.5 매턴 커널
- 14.2.6 문자열 커널
- 14.2.7 피라미드 매치 커널
- 14.2.8 확률 생성 모형으로부터 유도되는 커널
- 14.3 GLM에서 커널 사용
- 14.3.1 커널 머신
- 14.3.2 L1VM과 RVM, 다른 희박 벡터 머신
- 14.4 커널 트릭
- 14.4.1 커널화된 최근접 이웃 분류
- 14.4.2 커널화된 K 객체 클러스터링
- 14.4.3 커널화된 리지 회귀
- 14.4.4 커널 PCA
- 14.5 지원 벡터 머신(SVM)
- 14.5.1 회귀를 위한 SVM
- 14.5.2 분류를 위한 SVM
- 14.5.3 C 선택
- 14.5.4 핵심 사항 정리
- 14.5.5 SVM의 확률론적 해석
- 14.6 분별적 커널 방법의 비교
- 14.7 생성 모형 설계를 위한 커널
- 14.7.1 평활 커널
- 14.7.2 커널 밀도 예측(KDE)
- 14.7.3 KDE부터 KNN까지
- 14.7.4 커널 회귀
- 14.7.5 지역적 가중치 회귀
- 연습문제
- 15장 가우시안 프로세스
- 15.1 소개
- 15.2 회귀에 대한 GP
- 15.2.1 잡음이 없는 관찰을 사용하는 예측
- 15.2.2 잡음 관찰을 사용하는 예측
- 15.2.3 커널 모수의 효과
- 15.2.4 커널 모수 예측하
- 15.2.5 계산과 수학적 이슈
- 15.2.6 준모수적 GP
- 15.3 GP가 GLM을 만족
- 15.3.1 이항 분류
- 15.3.2 다중 클래스 분류
- 15.4 다른 방법과 연결
- 15.4.1 선형 모형과 GP의 비교
- 15.4.2 선형 평활기와 GP의 비교
- 15.4.3 SVM과 GP의 비교
- 15.4.5 자연 네트워크와 GP의 비교
- 15.4.6 평활 스플라인과 CP의 비교
- 15.4.7 RKHS 방법과 GP의 비교
- 15.5 GP 잠재 변수 모형
- 15.6 큰 데이터 집합에 대한 예측 방법
- 연습문제
- 16장 가변 기저 함수 모형
- 16.1 소개
- 16.2 분류와 회귀 트리
- 16.2.1 기본 개념
- 16.2.2 성장 트리
- 16.2.3 트리 절단
- 16.2.4 트리의 장점과 단점
- 16.2.5 임의적 산림
- 16.2.6 CART와 전문과 계층적 혼합과 비교
- 16.3 일반화 가법 모형
- 16.3.1 백피팅
- 16.3.2 계산적 효율성
- 16.3.3 다변량 가변 회귀 스플라인(MARS)
- 16.4 부스팅
- 16.4.1 전진하는 가법적 모형화
- 16.4.2 L2boosting
- 16.4.3 AdaBoost
- 16.4.4 LogitBoost
- 16.4.5 함수적 기울기 하강으로서 부스팅
- 16.4.6 희박 부스팅
- 16.4.7 다변량 가변 회귀 트리(MART)
- 16.4.8 부스팅이 잘 작동하는 이유
- 16.4.9 베이지안 관점
- 16.5 전진 신경망 네트워크(다중 층 퍼셉트론)
- 16.5.1 콘볼루션 신경망
- 16.5.2 다른 종류의 신경망
- 16.5.3 분야에 대한 간단한 역사
- 16.5.4 에러 역전파 알고리즘
- 16.5.5 식별성
- 16.5.6 일반화
- 16.5.7 베이지안 추정
- 16.6 앙상블 학습
- 16.6.1 스택킹
- 16.6.2 에러 수정 출력 코드
- 16.6.3 앙상블 학습은 베이지안 모형 평균과 동일하지 않다
- 16.7 실험적 비교
- 16.7.1 저차원 특징
- 16.7.2 고차원 특징
- 16.8 블랙박스 모형 해석
- 연습문제
- 17장 마르코프와 은닉 마르코프 모형
- 17.1 소개
- 17.2 마르코프 모형
- 17.2.1 전이 행렬
- 17.2.2 응용: 언어 모형
- 17.2.3 마르코프 사슬의 정상 확률 분포
- 17.2.4 응용: 웹페이지 랭킹에 대한 구글의 페이지랭크 알고리즘
- 17.3 은닉 마르코프 모형
- 17.3.1 HMM의 응용
- 17.4 HMM에서 추정
- 17.4.1 임시 모형에 대한 추정 문제의 유형
- 17.4.2 전향 알고리즘
- 17.4.3 후향 알고리즘
- 17.4.4 비터비 알고리즘
- 17.4.5 전방 필터와 후방 표본
- 17.5 HMM 학습
- 17.5.1 전체적으로 관찰된 데이터의 훈련
- 17.5.2 HMM에 대한 EM
- 17.5.3 ‘적합’ HMM에 대한 베이지안 방법
- 17.5.4 차별적 훈련
- 17.5.5 모형 선택
- 17.6 HMM의 일반화
- 17.6.1 변수 존속(준마르크프) HMM
- 17.6.2 계층적 HMM
- 17.6.3 입출력 HMM
- 17.6.4 자동 후퇴 HMM
- 17.6.5 계승 HMM
- 17.6.6 Coupled HMM and the influence model
- 17.6.7 다이내믹 베이지안 네트워크(DBN)
- 연습문제
- 18장 상태 공간 모형
- 18.1 소개
- 18.2 SSM 응용
- 18.2.1 SSM 객체 트래킹
- 18.2.2 로봇 SLAM
- 18.2.3 반복 최소 제곱을 사용하는 온라인 모수 학습
- 18.2.4 연속 시간 예측에 대한 SSM
- 18.3 LG-SSM에서 추정
- 18.3.1 칼만 필터링 알고리즘
- 18.3.2 칼만 평활 알고리즘
- 18.4 LG-SSM의 학습
- 18.4.1 식별성과 산술적 안정성
- 18.4.2 전체 관찰 데이터의 훈련
- 18.4.3 LG-SSM의 EM
- 18.4.4 부분 공간 방법
- 18.4.5 ‘적합’ LG-SSM에 대한 베이지안 방법
- 18.5 비선형, 비가우시안 SSM에 대한 온라인 추정 예측
- 18.5.1 확장된 칼만 필터(EKF)
- 18.5.2 무향 칼만 필터(UKF)
- 18.5.3 가정된 밀도 필터링(ADF)
- 18.6 하이브리드 이산/연속 SSM
- 18.6.1 추정
- 18.6.2 응용: 데이터 협력과 다중 타겟 트래킹
- 18.6.3 응용: 오류 진단
- 18.6.4 응용: 경제 연구
- 연습문제
- 19장 무방향 그래픽 모형
- 19.1 소개
- 19.2 UGM의 조건적 독립 속성
- 19.2.1 핵심 속성
- 19.2.2 d 분해의 무방향 변경
- 19.2.3 방향 그래픽과 무방향 그래픽 모형의 비교
- 19.3 MRF의 모수화
- 19.3.1 헤머즐리-클리포드 이론
- 19.3.2 포텐셜 함수 표현
- 19.4 MRF의 예제
- 19.4.1 아이징 모형
- 19.4.2 홉필드 네트워크
- 19.4.3 포츠 모형
- 19.4.4 가우시안 MRF
- 19.4.5 마르코프 로직 네트워크
- 19.5 학습
- 19.5.1 기울기 방법을 사용하는 maxent 모형 훈련
- 19.5.2 부분적으로 관찰된 maxent 모형의 훈련
- 19.5.3 MRF의 MLE를 계산하기 위한 예측 방법
- 19.5.4 의사 발생 가능도
- 19.5.5 확률 최대 발생 가능도
- 19.5.6 maxent 모형에 대한 특징 유도
- 19.5.7 반복 비례 적합(IPF)
- 19.6 조건적 임의의 필드(CRF)
- 19.6.1 연쇄 구조 CRF, MEMM과 레이블 편향 문제
- 19.6.2 CRF의 응용
- 19.6.3 CRF 훈련
- 19.7 구조적 SVM
- 19.7.1 SSVM: 확률적 관점
- 19.7.2 SSVM: 비확률적 관점
- 19.7.3 적합 SSVM에 대한 절단선 방법
- 19.7.4 적합 SSVM에 대한 온라인 알고리즘
- 19.7.5 잠재 구조 SVM
- 연습문제
- 20장 그래픽 모형에 대한 정확한 추정
- 20.1 소개
- 20.2 트리에 대한 신뢰도 확산
- 20.2.1 시리얼 프로토콜
- 20.2.2 병렬 프로토콜
- 20.2.3 가우시안 BP
- 20.2.4 다른 BP 변이
- 20.3 변수 제거 알고리즘
- 20.3.1 일반화된 분포법
- 20.3.2 VE의 계산적 복잡도
- 20.3.3 VE의 약점
- 20.4 접합 트리 알고리즘
- 20.4.1 접합 트리 생성
- 20.4.2 접합 트리에서 메시지 전달
- 20.4.3 JTA의 계산적 복잡도
- 20.4.4 JTA 일반화
- 20.5 최악의 사례에서 정확한 추정의 계산적 어려움
- 20.5.1 근사 추정
- 연습문제
- 21장 분산 추론
- 21.1 소개
- 21.2 분산 추론
- 21.2.1 분산 객체의 변경적 해석
- 21.2.2 포워드 또는 역KL?
- 21.3 평균 필드 방법
- 21.3.2 예제: 아이징 모형의 평균 필드
- 21.4 구조화된 평균 필드
- 21.4.1 예제: 팩토리얼 HMM
- 21.5 변분 베이즈
- 21.5.1 예제: 다변량 가우시안에 대한 VB
- 21.5.2 예제: 선형 회귀의 VB
- 21.6 변이 베이즈 EM
- 21.6.1 예제: 혼합 가우시안에 대한 VBEM*
- 21.7 변이 메시지 전달과 VIBES
- 21.8 지역 변이 경계
- 21.8.1 Motivating 애플리케이션
- 21.8.2 log-sum-exp 함수에 대한 보닝의 2차 결합
- 21.8.3 시그모이드 함수에 대한 경계
- 21.8.4 log-sum-exp 함수에 다른 경계와 예측
- 21.8.5 상위 경계에 기초한 변이 추정
- 연습문제
- 22장 다양한 분산 추론
- 22.1 소개
- 22.2 루피 신뢰 전파: 알고리즘 이슈
- 22.2.1 신뢰 역사
- 22.2.2 페어와이즈 모형에서 LBP
- 22.2.3 인자 그래프에서 LBP
- 22.2.4 수렴
- 22.2.5 LBP의 정확성
- 22.2.6 LBP에 대한 다른 빠른 트릭
- 22.3 루피 신뢰 전파: 이론적 이슈
- 22.3.2 주변 폴리톱
- 22.3.3 다양한 최적 문제에 정확한 추정
- 22.3.4 다양한 최적 문제의 평균 필드
- 22.3.5 다양한 최적 문제의 LBP
- 22.3.6 루피 BP와 평균 필드
- 22.4 신뢰 전파의 확장*
- 22.4.1 일반화 신뢰 전파
- 22.4.2 볼록 신뢰 전파
- 22.5 기대 전파
- 22.5.1 변이 추론 문제의 EP
- 22.5.2 모멘트 매칭을 사용하는 EP 객체를 최적화
- 22.5.3 클러터 문제에 대한 EP
- 22.5.4 LBP는 EP의 특정 사례
- 22.5.5 TrueSkill을 사용하는 랭킹 플레이어
- 22.5.6 EP의 다른 응용
- 22.6 MAP 상태 예측
- 22.6.1 선형 프로그래밍 완화
- 22.6.2 최대 곱 신뢰 전파
- 22.6.3 그래프컷
- 22.6.4 그래프컷과 BP의 실험적 비교
- 22.6.5 이중 분해
- 연습문제
- 23장 몬테카를로 추정
- 23.1 소개
- 23.2 표준 분포의 표본화
- 23.2.1 cdf 사용
- 23.2.2 가우시안 표본화(박스-뮬러 방법)
- 23.3 기각 샘플링
- 23.3.1 기본 개념
- 23.3.2 예제
- 23.3.3 베이지안 통계 응용
- 23.3.4 가변 기각 샘플링
- 23.3.5 고차원에서 기각 샘플링
- 23.4 중요 샘플링
- 23.4.1 기본 개념
- 23.4.2 비정규화 분포 처리
- 23.4.3 DGM에 대한 중요도 샘플링: 발생 가능도 가중치
- 23.4.4 중요 표본 재샘플링(SIR)
- 23.5 입자 필터링
- 23.5.1 시퀀셜 중요 샘플링
- 23.5.2 퇴보 문제
- 23.5.3 재샘플링 스텝
- 23.5.4 예측 분포
- 23.5.5 응용: 로봇 지역화
- 23.5.6 응용: 시각 객체 트래킹
- 23.5.7 응용: 시계열 예측
- 23.6 라오-블랙웰 입자 필터링(RBPF)
- 23.6.1 스위칭 LG-SSM에 대한 RBPF
- 23.6.2 응용: 움직이는 목표 트래킹
- 23.6.3 응용: Fast SLAM
- 연습문제
- 24장 마르코프 사슬 몬테카를로 추정
- 24.1 소개
- 24.2 깁스 샘플링
- 24.2.1 기본 개념
- 24.2.2 예제: 아이징 모형에 대한 깁스 표본
- 24.2.3 예제: GMM의 모수 추정에 대한 깁스 표본
- 24.2.4 붕괴된 깁스 샘플링
- 24.2.5 계층적 GLM에 대한 깁스 샘플링
- 24.2.6 BUGS와 JAGS
- 24.2.7 대체 사후 확률(IP) 알고리즘
- 24.2.8 블록킹 깁스 샘플링
- 24.3 메트로폴리스 헤스팅 알고리즘
- 24.3.1 기본 개념
- 24.3.2 깁스 샘플링은 MH의 특정 사례
- 24.3.3 예측 분포
- 24.3.4 가변 MCMC
- 24.3.5 초기화와 모드 호핑
- 24.3.6 MH의 동작
- 24.3.7 역점프(초차원) MCMC
- 24.4 MCMC의 속도와 정확성
- 24.4.1 번인 단계
- 24.4.2 마르코프 사슬의 혼합률
- 24.4.3 수렴 진단
- 24.4.4 MCMC의 정확성
- 24.4.5 얼마나 많은 사슬이 있는가?
- 24.5 보조 변수의 MCMC
- 24.5.1 로지스틱 회귀에 대한 보조 변수
- 24.5.2 슬라이스 샘플링
- 24.5.3 스벤센 왕
- 24.5.4 하이브리드/해밀토니안 MCMC
- 24.6 애닐링 방법
- 24.6.1 모의 애닐링
- 24.6.2 애닐링 중요 샘플링
- 24.6.3 병렬 템퍼링
- 24.7 주변 발생 가능도 예측
- 24.7.1 지원자 방법
- 24.7.2 조화 평균 예측
- 24.7.3 애닐링 중요 샘플링
- 연습문제
- 25장 클러스터링
- 25.1 소개
- 25.1.1 (비)유사성 측정
- 25.1.2 클러스터링 방법의 출력을 평가
- 25.2 디리클레 프로세스 혼합 모형
- 25.2.1 한정에서부터 무한 혼합 모형까지
- 25.2.2 디리클레 프로세스
- 25.2.3 혼합 모형에 대한 디리클레 절차 적용
- 25.2.4 DP 혼합 모형 적합
- 25.3 친화도 전파
- 25.4 스펙트럼 클러스터링
- 25.4.1 그래프 라플라시안
- 25.4.2 일반화된 그래프 라플라시안
- 25.4.3 예제
- 25.5 계층적 클러스터링
- 25.5.1 응집 클러스터링
- 25.5.2 분열을 초래하는 클러스터링
- 25.5.3 클러스터의 개수를 선택
- 25.5.4 베이지안 계층적 클러스터링
- 25.6 데이터 포인트와 특징 클러스터링
- 25.6.1 바이클러스터링
- 25.6.2 다중 관점 클러스터링
- 26장 그래픽 모형 구조 학습
- 26.1 소개
- 26.2 지식 발견에 대한 구조 학습
- 26.2.1 연관 네트워크
- 26.2.2 의존도 네트워크
- 26.3 학습 트리 구조
- 26.3.1 방향 또는 무방향 트리?
- 26.3.2 ML 트리 구조에 대한 초-리우 알고리즘
- 26.3.3 MAP 포레스트 찾기
- 26.3.4 트리 혼합
- 26.4 DAG 구조 학습
- 26.4.1 마르코프 등식
- 26.4.2 정확한 구조 추정
- 26.4.3 큰 그래프로 규모 확장
- 26.5 잠재 변수를 가진 DAG 구조 학습
- 26.5.1 누락 데이터를 가질 때 주변 발생 가능도 예측
- 26.5.2 구조적 EM
- 26.5.3 숨겨진 변수 발견
- 26.5.4 사례연구: 구글의 래필
- 26.5.5 구조적 등식 모형
- 26.6 인과 DAG 학습
- 26.6.1 DAG의 인과 해석
- 26.6.2 심슨의 패러독스를 풀기위한 인과 DAG를 사용
- 26.6.3 인과 DAG 구조 학습
- 26.7 무방향 가우시안 그래픽 모형 학습
- 26.7.1 GGM에 대한 MLE
- 26.7.2 그래픽 라쏘
- 26.7.3 GGM 구조에 대한 베이지안 추정
- 26.7.4 코플라를 사용하는 비가우시안 데이터의 처리
- 26.8 무방향 이산 그래픽 모형 학습
- 26.8.1 MRF/CRF에 대한 그래픽 라쏘
- 26.8.2 얇은 접합 트리
- 연습문제
- 27장 이산 데이터에 대한 잠재 변수 모형
- 27.1 소개
- 27.2 이산 데이터에 대한 분산 상태 LVM
- 27.2.1 혼합 모형
- 27.2.2 지수족 PCA
- 27.2.3 LDA와 mPCA
- 27.2.4 GaP 모형과 비음수 행렬 분해
- 27.3 잠재 디리클레 할당(LDA)
- 27.3.1 기본 개념
- 27.3.2 토픽의 무감독 발견
- 27.3.3 언어 모형으로서 양적으로 LDA 평가
- 27.3.4 (붕괴된) 깁스 표본을 사용하는 적합
- 27.3.5 예제
- 27.3.6 배치 변이 추정을 사용하는 적합
- 27.3.7 온라인 변이 추정을 사용하는 적합
- 27.3.8 토픽의 개수를 결정
- 27.4 LDA 확정
- 27.4.1 연관된 토픽 모형
- 27.4.2 동적 토픽 모형
- 27.4.3 LDA-HMM
- 27.4.4 감독 LDA
- 27.5 그래프 구조화 데이터에 대한 LVM
- 27.5.1 확률적 블록 모형
- 27.5.2 혼합 멤버십 확률 블록 모형
- 27.5.3 연관 토픽 모형
- 27.6 연관 데이터에 대한 LVM
- 27.6.1 무한 연관 모형
- 27.6.2 협력 필터링에 대한 확률 행렬 분해
- 27.7 한정 볼츠만 머신(RBM)
- 27.7.1 RBM의 당양성
- 27.7.2 RBM 학습
- 27.7.3 RBM의 응용
- 연습문제
- 28장 딥 러닝
- 28.1 소개
- 28.2 딥 생성 모형
- 28.2.1 딥 방향 네트워크
- 28.2.2 딥 볼츠만 머신
- 28.2.3 딥 신뢰 네트워크
- 28.2.4 DBN의 그리디 레이어-와이즈 학습
- 28.3 딥 신경 네트워크
- 28.3.1 딥 다중 레이어 퍼셉트론
- 28.3.2 딥 자동 인코더
- 28.3.3 스택 잡음제거 자동-인코더
- 28.4 딥 네트워크의 응용
- 28.4.1 DBN을 사용하는 손으로 쓴 숫자 분류
- 28.4.2 딥 자동 인코더를 사용하는 데이터 영상화와 특징 발견
- 28.4.3 딥 자동 인코더를 사용하는 정보 검색(구문 해싱)
- 28.4.4 1d 콘볼루션 DBN을 사용하는 오디오 특징 학습
- 28.4.5 2d 콘볼루션 DBN을 사용하는 이미지 특징 학습
- 28.5 논의
- 표기법
도서 오류 신고
정오표
정오표
[p.112 : 11행]
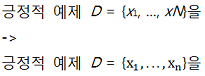
[p.112 : 16행]
단지 하나의 모범을
->
단지 하나의 예시를
[p.122 : 식 3.16]
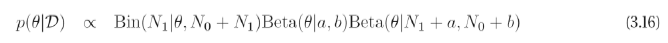
->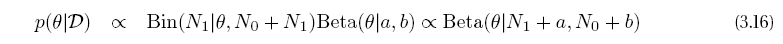
[p.151]
행렬의 트레이스(trace)를 참조하고,
->
행렬의 트레이스(trace)를 가리키고,
[p.153]
가진 분산이다
->
가진 분산임을 살펴본다
처음 두 모멘트는 일반적으로 데이터로부터 신뢰할 수 있는 예측을 할 수 있는 것이다.
->
일반적으로 1차, 2차 모멘트가 데이터로부터 신뢰할 수 있는 예측을 할 수 있는 전부이다.
[p.154]
네이브 베이즈
->
나이브 베이즈