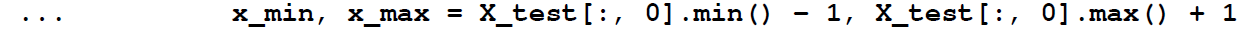OpenCV를 위한 머신 러닝 [머신 러닝 기술 입문]
- 원서명Machine Learning for OpenCV: Expand your OpenCV knowledge and master key concepts of machine learning using this practical, hands-on guide (ISBN 9781783980284)
- 지은이마이클 베이어(Michael Beyeler)
- 옮긴이테크 트랜스 그룹 T4
- ISBN : 9791161750965
- 40,000원
- 2017년 12월 28일 펴냄
- 페이퍼백 | 504쪽 | 188*235mm
- 시리즈 : acorn+PACKT
판매처
개정판책 소개
소스 코드 파일은 여기에서 내려 받으실 수 있습니다.
요약
컴퓨터는 머신 러닝을 통해 과거의 수집된 데이터를 사용하고, 미래 예측을 하면서, 학습을 진행할 수 있다. 이 책에서는 간단한 예제를 활용해 분류 및 회귀와 같은 통계 학습의 핵심 개념을 직관적으로 확인할 수 있다. 모든 기본 개념을 다룬 후, 의사 결정 트리(Decision tree), 서포트 벡터 머신(Support vector) 및 베이지안(Bayesian) 네트워크와 같은 다양한 알고리즘을 탐색하고 다른 OpenCV 기능과 결합하는 방법을 배우게 된다. 그 과정에서 데이터를 이해하고 어떻게 완벽하게 작동하는 머신 러닝 파이프 라인을 구축 하는지를 이해하여 전체 작업을 배우게 된다. 가장 뜨거운 주제인 '딥러닝'을 시작할 준비가 될 때까지, 더 많은 머신 러닝 기술을 학습할 수 있다. 작업에 적합한 도구를 선택하는 방법을 숙지하고 숙련된 기술과 결합해 모든 관련 머신 러닝의 기본 지식을 파악하게 할 수 있게 된다.
추천의 글
비록 시간이 오래 걸리긴 했지만, 지난 몇 년 동안 기계는 스스로 정확하게 학습하는 방법을 배워왔다. 이에 따라 카메라가 사람을 찍을 때 얼굴을 검출하고, 소셜 미디어 앱이 업로드한 사진을 통해 우리를 인식할 수 있다는 것은 더 이상 놀라운 일이 아니다. 앞으로 몇 년 동안, 우리는 더욱 급진적인 변화를 경험하게 될 것이다. 머지않아 자동차가 자율 운행하게 될 것이고, 휴대 전화는 특정 언어로 된 간판을 읽고 번역 가능하게 될 것으로 보인다. 또한 엑스레이 및 기타 의료 영상을 보고 강력한 알고리즘으로 분석함으로써 의학 진단과 효과적인 치료법도 추천하게 될 것이다.
이러한 변화는 컴퓨팅 성능이 향상되고, 대량의 이미지 데이터와 수학, 통계학, 컴퓨터 과학에서 가져온 아이디어가 폭발적으로 결합함으로써 이뤄진다. 빠르게 성장하고 있는 머신 러닝 방법은 일상적인 세상과의 상호작용에 영향을 미친다. 컴퓨터 비전의 패러다임 변화에서 가장 주목할 만한 항목 중 하나는 오픈소스 커뮤니티의 많은 기여자, 애호가, 과학자, 엔지니어가 자유롭게 사용할 수 있으며, 이미 개발된 소프트웨어 활용에 많이 의존할 수 있다는 점이다. 이는 진입 장벽이 그 어느 때보다 낮다는 것을 의미한다. 이미지 처리를 위해 머신 러닝을 활용하고자 하는 마음만 있다면, 누구나 사용 가능하게 됐다.
다양한 도구와 아이디어들이 있다고 하더라도, 여러 갈래의 수많은 길이 있는 복잡한 정원에서는 길을 안내하고 올바른 길로 가도록 도와주는 가이드가 필요하다. 다행히도 이 책을 보는 당신에게는 앞서 이야기한 복잡한 길 찾기와 관련된 좋은 소식을 전할 수 있다. 이 책을 집어 들었다면, 당신은 내 동료이자 이 책의 저자인 마이클 베이어 박사가 담아낸 내용을 좋은 지침서로 활용할 수 있을 것이다. 마이클은 광범위한 전문 지식을 가지고 있는 열정적인 엔지니어, 컴퓨터 과학자, 신경과학자이면서 많은 오픈소스 소프트웨어를 개발하는 개발자다. 그는 로봇이 복잡한 환경을 관측하고 탐색할 방법을 가르칠 뿐 아니라, 뇌 활동을 모델링하는 방법을 만들었고, 프로그래밍을 사용해 다양한 머신 러닝 및 이미지 처리 문제를 해결하는 방법을 개발자들에게 정기적으로 가르친다. 정기적인 학습을 통해 자신의 전문 지식과 경험에 대해 한 번 더 생각하고, 책 내의 아이디어를 학습할 때 여러 번 생각할 수 있게 해준다. 또한 가르치면서 자신의 유머 감각도 잘 살리고 있다.
두 번째 좋은 소식은 이 책과 함께하는 시간이 유쾌한 여행이 될 것이라는 사실이다. 코드와 데이터를 사용해 컴퓨터 비전과 머신 러닝 문제를 해결하면 퍼즐 조각을 모을 때만큼의 큰 스릴을 느낄 수 있다. 리처드 파인만(Richard Feynman)이 말했듯이 "내가 만들 수 없는 것을 이해할 수는 없다."라고 생각하면 좋다. 따라서 이 책에서 제공되는 (오픈소스) 코드와 데이터로 많은 내용을 살펴보고, 창의력을 발휘해보자. 책의 내용은 쉽게 이해할 수 있을 것이다.
/아리엘 로켐(Ariel Rokem), 워싱턴 대학 eScience 연구소 데이터 과학자
이 책에서 다루는 내용
■ OpenCV의 머신 러닝 모듈 탐색과 효과적인 사용
■ 파이썬으로 배우는 컴퓨터 비전용 딥러닝 기술
■ 선형 회귀 및 정규화 기술
■ 꽃의 종, 필기 인식, 보행자 등의 객체 분류
■ 서포트 벡터 머신, 강화된 의사 결정 트리, 랜덤 포레스트의 효과적인 사용 방법 탐색
■ 실제 네트워크 문제를 해결할 수 있는 신경망와 심층적인 학습 방법
■ k-평균 클러스터링을 사용한 데이터의 숨겨진 구조 발견
■ 데이터 전처리 및 특징 엔지니어링 활용
이 책의 대상 독자
이 책은 OpenCV와 파이썬에 대한 기본 지식을 갖췄지만, 이에 대해 더 많이 배우고자 하는 독자를 대상으로 한다.
이 책의 구성
1장. ‘머신 러닝 시작’ 머신 러닝의 여러 하위 내용을 소개하고 파이썬 아나콘다(Python Anaconda)환경에서 OpenCV 및 기타 필수 도구를 설치하는 방법을 설명한다.
2장. ‘OpenCV와 파이썬의 데이터 작업’ 일반적인 머신 러닝 워크플로우의 모습과 데이터를 사용하는 방법을 보여준다. 학습 및 테스트 데이터의 차이점을 설명하고, OpenCV와 파이썬을 사용해 데이터를 불러온 후 저장, 조작, 시각화하는 방법을 보여준다.
3장. ‘지도 학습의 첫 번째 단계’ 분류와 회귀 같은 몇 가지 핵심 개념을 살펴보고 지도 학습 주제를 소개한다. OpenCV에서 간단한 머신 러닝 알고리즘을 구현하는 방법, 데이터에 대한 예측을 수행하는 방법, 모델을 평가하는 방법을 배운다.
4장. ‘데이터와 엔지니어링 특징 표현하기’ 공통적으로 잘 알려진 머신 러닝 데이터 세트를 분석하는 방법과 원시 데이터에서 의미 있는 값을 추출하는 방법을 설명한다.
5장. ‘의사 결정 트리를 사용해 의료 진단하기’ OpenCV에서 결정 트리를 작성하는 방법과 다양한 분류 및 회귀 문제에서 결정 트리를 사용하는 방법을 보여준다.
6장. ‘서포트 벡터 머신으로 보행자 검출하기’ OpenCV에서 서포트 벡터 머신을 구축하는 방법과 이미지에 보행자를 검출하는 데 적용하는 방법을 설명한다.
7장. ‘베이지안 학습을 이용한 스팸 필터 구현’ 확률 이론을 소개하고 베이지안 추론을 사용해 전자 메일에서 스팸을 분류하는 방법을 보여준다.
8장. ‘비지도 학습으로 숨겨진 구조 발견’ k-평균 클러스터링과 기댓값 최대화(expectation maximization) 알고리즘 등의 비지도 학습 알고리즘을 살펴본다. 단순하며 레이블이 없는 데이터 세트에서 숨겨진 구조를 추출하는 방법을 보여준다.
9장. ‘딥러닝을 사용해 숫자 필기 인식 분류하기’ 흥미진진한 딥러닝 분야를 소개한다. 퍼셉트론(perceptron)과 멀티레이어 퍼셉트론으로 시작해 광범위한 MNIST 데이터베이스에서 숫자 필기의 자릿수를 분류하기 위해 심층 신경망(deep neural network)을 구축하는 방법을 배운다.
10장. ‘앙상블 기법으로 여러 알고리즘 결합하기’ 개별 학습자의 약점을 극복하기 위해 여러 알고리즘을 앙상블에서 효과적으로 결합하는 방법을 보여준다. 따라서 좀 더 정확하고 신뢰할 수 있는 예측이 가능하다.
11장. ‘하이퍼 매개변수 튜닝으로 올바른 모델 선택하기’ 모델 선택 개념을 소개한다. 이를 통해 다양한 머신 러닝 알고리즘을 비교하고 현재 작업에 적합한 도구를 선택할 수 있다.
12장. ‘정리하기’ 독자적으로 미래의 머신 러닝 문제에 접근하는 방법에 대한 유용한 팁과 고급 주제 관련 정보를 찾을 수 있는 위치를 알려주는 것으로 결론을 맺는다.
목차
목차
- 1장. 머신 러닝 시작
- 머신 러닝 시작하기
- 머신 러닝으로 해결할 수 있는 문제들
- 파이썬 시작하기
- OpenCV 시작하기
- 설치하기
- 이 책의 최신 코드 얻기
- 파이썬의 아나콘다 배포판에 대해 살펴보기
- conda 환경에서 OpenCV 설치
- 설치 확인하기
- OpenCV의 ML 모듈 엿보기
- 요약
- 2장. OpenCV와 파이썬의 데이터 작업
- 머신 러닝 워크플로우의 이해
- OpenCV와 파이썬을 사용해 데이터 다루기
- 새로운 IPython 또는 주피터 세션 시작하기
- 파이썬 NumPy 패키지를 사용해 데이터 다루기
- 파이썬에서 외부 데이터 세트 적재하기
- Matplotlib을 사용해 데이터 시각화하기
- C++에서 OpenCV의 TrainData 컨테이너를 사용해 데이터 다루기
- 요약
- 3장. 지도 학습의 첫 번째 단계
- 지도 학습 이해하기
- OpenCV에서 지도 학습 살펴보기
- 점수화 기능으로 모델 성능 측정
- 분류 모델을 사용해 클래스 레이블 예측하기
- k-최근접 이웃 알고리즘의 이해
- OpenCV에서 k-최근접 이웃 구현하기
- 회귀 모델을 사용해 지속적인 결과 예측하기
- 선형 회귀 분석
- 선형 회귀 분석 방법을 사용해 보스턴 주택 가격 예측하
- 라소 및 융기 회귀 적용
- 로지스틱 회귀를 이용한 아이리스 종 분류하기
- 로지스틱 회귀 이해하기
- 요약
- 지도 학습 이해하기
- 4장. 데이터와 엔지니어링 특징 표현하기
- 특징 엔지니어링의 이해
- 전처리 데이터
- 특징 표준화
- 특징 정규화
- 특징의 범위 확장
- 특징 이진화
- 누락된 데이터 처리
- 차원 축소 이해하기
- OpenCV에서 PCA 구현하기
- ICA 구현
- NMF 구현
- 범주형 변수 표현하기
- 텍스트 특징 표현하기
- 이미지 표현하기
- 색상 공간 사용
- 이미지의 코너 검출하기
- SIFT 사용하기
- SURF 사용하기
- 요약
- 5장. 의사 결정 트리를 사용해 의료 진단하기
- 의사 결정 트리의 이해
- 첫 번째 결정 트리 만들기
- 훈련된 의사 결정 트리에 대한 시각화
- 의사 결정 트리의 내부 동작 조사
- 특징 중요도 평가
- 의사 결정 규칙 이해하기
- 의사 결정 트리의 복잡성 제어
- 의사 결정 트리를 사용해 유방암 진단하기
- 데이터 세트 불러오기
- 의사 결정 트리 만들기
- 회귀 결정 트리 사용
- 요약
- 의사 결정 트리의 이해
- 6장. 서포트 벡터 머신으로 보행자 검출하기
- 선형 서포트 벡터 시스템의 이해
- 최적의 의사 결정 경계 학습
- 첫 번째 서포트 벡터 머신 구현
- 비선형 의사 결정 경계 다루기
- 커널 트릭 이해하기
- 우리가 사용할 커널 파악하기
- 비선형 서포트 벡터 머신 구현
- 외부에서 보행자 검출하기
- 데이터 세트 가져오기
- HOG 훑어보기
- 네거티브 생성하기
- 서포트 벡터 머신 구현하기
- 모델 부트스트랩하기
- 더 큰 이미지에서 보행자 검출하기
- 모델 개선하기
- 요약
- 선형 서포트 벡터 시스템의 이해
- 7장. 베이지안 학습을 이용한 스팸 필터 구현
- 베이지안 추론 이해하기
- 확률 이론에 대해 간단히 살펴보기
- 베이즈 정리 이해하기
- 나이브 베이즈 분류기의 이해
- 첫 번째 베이지안 분류기 구현하기
- 장난감 데이터 세트 만들기
- 일반 베이즈 분류기로 데이터 분류
- 나이브 베이즈 분류기로 데이터 분류하기
- 조건부 확률의 시각화
- 나이브 베이즈 분류기를 사용해 이메일 분류하기
- 데이터 세트 불러오기
- Pandas를 사용해 데이터 행렬 만들기
- 데이터 전처리하기
- 정상적인 베이즈 분류기 훈련
- 전체 데이터 세트에 대한 교육
- n-gram을 사용해 결과 개선하기
- tf-idf를 사용해 결과 개선하기
- 요약
- 베이지안 추론 이해하기
- 8장. 비지도 학습으로 숨겨진 구조 발견
- 비지도 학습의 이해
- k-평균 클러스터링의 이해
- 첫 번째 k-평균 예제 구현
- 기댓값 최대화 방법 이해하기
- 기대치 극대화 솔루션 구현하기
- 기댓값 최대화의 한계 파악하기
- 첫 번째 경고: 전반적인 최적 결과를 찾기 어려움
- 두 번째 경고: 미리 클러스터 수를 선택해야 한다
- 세 번째 주의 사항: 클러스터 경계는 선형이다
- 네 번째 경고: k-평균은 많은 수의 샘플에서는 느리다
- k-평균을 사용해 색 공간 압축하기
- 트루 컬러 팔레트 시각화
- k-평균을 사용해 색상 표 축소
- k-평균을 사용해 숫자 필기 인식 분류하기
- 데이터 세트 불러오기
- k-평균 실행하기
- 클러스터를 계층적 트리로 구성하기
- 계층적 클러스터링의 이해
- 응집력 있는 계층적 클러스터링 구현
- 요약
- 9장. 딥러닝을 사용해 숫자 필기 인식 분류하기
- 맥컬럭-피츠 뉴런에 대한 이해
- 퍼셉트론 이해하기
- 첫 번째 퍼셉트론 구현하기
- 장난감 데이터 세트 생성하기
- 퍼셉트론을 데이터에 적용하기
- 퍼셉트론 분류기 평가
- 선형으로 분리되지 않는 데이터에 퍼셉트론 적용하기
- 다층 퍼셉트론의 이해
- 경사 하강법 이해하기
- 역전파를 이용해 다층 퍼셉트론 훈련하기
- OpenCV에서 다층 퍼셉트론 구현하기
- 딥러닝에 익숙해지기
- Keras에 익숙해지기
- 숫자 필기 인식 분류하기
- MNIST 데이터 세트 적재하기
- MNIST 데이터 세트 전처리하기
- OpenCV를 사용해 MLP 훈련하기
- Keras를 이용한 심층 신경망 훈련하기
- 요약
- 10장. 앙상블 기법으로 여러 알고리즘 결합하기
- 앙상블 메소드 이해하기
- 평균 앙상블 이해하기
- 부스터 앙상블 이해하기
- 스태킹 앙상블 이해하기
- 의사 결정 트리를 랜덤 포레스트로 결합하기
- 의사 결정 트리의 단점 이해하기
- 첫 랜덤 포레스트 구현하기
- scikit-learn을 사용해 랜덤 포레스트 구현하기
- 과랜덤화된 트리 구현하기
- 얼굴 인식을 위한 랜덤 포레스트 사용
- 데이터 세트 불러오기
- 데이터 세트 전처리하기
- 랜덤 포레스트 훈련 및 테스트
- AdaBoost 구현하기
- OpenCV에서 AdaBoost 구현하기
- scikit-learn에서 AdaBoost 구현하기
- 다른 모델을 투표 분류기로 결합하기
- 다양한 투표 방법 이해하기
- 투표 분류기 구현하기
- 요약
- 앙상블 메소드 이해하기
- 11장. 하이퍼 매개변수 튜닝으로 올바른 모델 선택하기
- 모델 평가하기
- 모델을 잘못된 방식으로 평가하기
- 올바른 방식으로 모델 평가하기
- 최고의 모델 선택하기
- 교차 유효성 검증의 이해
- OpenCV에서 교차 유효성의 수동 검증 구현
- k-겹 교차 검증을 위해 scikit-learn 사용하기
- 단일 관측치 제거법 교차 검증 구현
- 부트스트랩을 사용해 견고성 예측하기
- OpenCV에서 부트스트랩 수동으로 구현하기
- 결과의 중요성 평가하기
- 스튜던트 t-검정 구현하기
- 맥니마의 검정 구현하기
- 격자 검색으로 하이퍼 매개변수 튜닝하기
- 간단한 격자 검색 구현하기
- 유효성 검증 집합의 값 이해하기
- 교차 유효성 검증과 함께 격자 검색 결합하기
- 중첩된 교차 유효성 검증과 함께 격자 검색 결합하기
- 다양한 평가 메트릭을 사용한 점수화 모델
- 올바른 분류 기준 선택하기
- 올바른 회귀 측정 기준 선택하기
- 파이프라인을 형성하기 위한 체이닝 알고리즘
- scikit-learn에서 파이프라인 구현하기
- 격자 검색의 파이프라인 사용하기
- 요약
- 모델 평가하기
- 12장. 정리하기
- 머신 러닝 문제점에 접근하기
- 자신만의 추정기 작성하기
- 자신의 OpenCV 기반 분류기를 C++로 작성하기
- 파이썬으로 자신의 scikit-learn 기반 분류기를 작성하기
- 다음 단계
- 요약
- 찾아보기
- 컬러 이미지
관련 블로그 글
머신 러닝, 이제는 해야 할 때!
이제 기계는 스스로 정확하게 학습할 줄 안다.

▲ 넷플릭스 오리지널 드라마 〈블랙 미러〉 시즌 3, Episode 1 '추락'의 장면
넷플릭스 오리지널 드라마 〈블랙 미러〉 시즌 3의 1화 '추락'은
소셜 미디어의 인기 점수로 사람들의 사회적 위치가 결정되는 가상 세계를 배경으로 한다.
눈에 이식된 기계 장치들은 지나다니는 사람들의 얼굴을 자동으로 인식하고, 그들의 소셜 미디어 평균 점수를 얼굴 옆에 띄워준다.
이처럼 자동으로 얼굴을 인식하고 식별할 수 있게 하는 기술은 무엇일까?

▲ 애플 아이폰 Ⅹ 'Knows You When You Change' 광고 장면
2017년 11월, 애플은 아이폰 X의 발매와 함께 중요 기능 중 하나인 '페이스(Face) ID'를 선보였다.
페이스 ID는 사용자의 얼굴을 인식해서 빠르고 간편한 잠금 해제와 사용자 인증을 가능케 하는 기술이다.
화장을 하거나 수염을 기르는 등 외모에 변화가 생겨도 자동으로 동일한 얼굴을 인식한다는 점을 애플은 강조한다.
이 페이스 ID는 '머신 러닝' 기술을 기반으로 한다.
페이스 ID를 최초 등록할 때 수집한 데이터를 기반으로, 카메라에 비친 사용자의 얼굴이 동일한 사람의 것인지 분석한다.
데이터 포인트가 충분히 일치하면 시스템은 사용자를 인식한다.
이와 같이 기존에 입력한 데이터들을 바탕으로 기계가 스스로 새로운 결과를 도출해내는 것이 바로 '머신 러닝'이다.
드라마 〈블랙 미러〉의 배경이 된 가상 세계에도 마찬가지로 머신 러닝 기술이 적용되어 있다.
소셜 미디어 앱에 업로드한 사진에서 얼굴이 자동으로 인식되는 것 외에도, 기존에 평가했던 영화를 바탕으로 취향을 예측 분석해 주는 등
이미 머신 러닝은 우리의 일상 생활 속에 깊이 녹아들어 있다.
앞으로 몇 년 동안, 우리는 더욱더 급진적인 변화를 경험하게 될 것이다.
빠르게 성장하는 머신 러닝은 일상 세상과의 상호작용에도 영향을 미친다.
머신러닝은 꼭 프로그램 개발을 위해서가 아니더라도 현대 사회의 기술 발전을 따라잡기 위해서 꼭 알아야 할 것이 되었다.

그리고 OpenCV는 이 주제의 교차점에 자리 잡고 있으며, 포괄적인 오픈소스 라이브러리를 제공한다.
무엇보다 OpenCV는 커뮤니티의 많은 기여자, 애호가, 과학자, 엔지니어가 자유롭게 사용할 수 있다.
이미 개발된 소프트웨어 활용에 많이 의존할 수도 있으므로, 진입 장벽이 그 어느 때보다 낮다.
머신 러닝을 활용하고자 하는 마음만 있다면, 누구나 사용 가능할 것이다.
『OpenCV를 위한 머신 러닝』은 기존 소스 코드를 기반으로 머신 러닝 알고리즘을 작성하거나
처음부터 자신만의 알고리즘을 개발하고자 하는 이들에게 도움이 될 것이다.
무엇보다 이 책과 함께하는 시간은 유쾌할 것이다.
저자 마이클 베이어(Michael Beyeler)는 꾸준한 교육 활동을 통해 자신의 지식을 널리 전파하는 법을 알고 있다.
코드와 데이터를 사용해 컴퓨터 비전과 머신 러닝 문제를 해결하면,
퍼즐 조각을 모을 때만큼의 큰 스릴을 느낄 수 있을 것이다.
바로 지금이
우리가 『OpenCV를 위한 머신 러닝』을 지침서 삼아 머신 러닝에 관해 이야기할 때다.

크리에이티브 커먼즈 라이센스 이 저작물은 크리에이티브 커먼즈 코리아 저작자표시 2.0 대한민국 라이센스에 따라 이용하실 수 있습니다.
도서 오류 신고
정오표
정오표
[p.69]

[p.72 : 아래에서 4행 ~ p.73: 1행]
image
->
images
[p.86 : 표]
거짓인지 알지 못함
->
참인지 알지 못함
[p.86 : 7행]
데이터 포인트가 참이지만 실제로는 거짓이라고 생각하면
->
데이터 포인트가 실제로는 거짓이지만 참이라고 생각하면
[p.86 : 10행]
거짓을 예측했지만
->
거짓을 에측했는데
[p.90 : 코드]
p lt.plot
->
plt.plot
[p.95 : 4행]
가장 가까운 이웃 훈련 데이터 세트에서
->
이웃 훈련 데이터 세트에서
[p.106 : 아래에서 6행]
M이 아닌 두 개의
->
2가 아닌 M개의
[p.106 : 아래에서 3행]
1초 동안
->
잠시
[p.319 : 아래에서 7행]