


R로 마스터하는 머신 러닝 2/e [업무에 활용할 수 있는 선형모델에서 딥러닝까지]
- 원서명Mastering Machine Learning with R - Second Edition: Advanced prediction, algorithms, and learning methods with R 3.X (ISBN 9781787287471)
- 지은이코리 레즈마이스터(Cory Lesmeister)
- 옮긴이김종원, 김태영, 류성희, 이호
- ISBN : 9791161751283
- 36,000원
- 2018년 03월 09일 펴냄
- 페이퍼백 | 552쪽 | 188*235mm
- 시리즈 : acorn+PACKT
책 소개
소스 코드 파일은 여기에서 내려 받으실 수 있습니다.
요약
통계 계산과 그래픽에 특화된 언어인 R을 사용해 머신 러닝을 배우는데 필요한 여러 통계적 기법을 실제 사례에 적용하며 설명한다. 복잡한 수식이나 전문 프로그래밍 기법을 사용하지 않으면서, 선형 회귀에서부터 분류 문제나 딥러닝, 추천 시스템, 군집화, 시계열 분석, 텍스트 마이닝까지 머신 러닝의 거의 전 영역에 대해 실제 데이터를 이용해 간결한 R 코드로 명확하게 설명한다. 기초 통계와 프로그래밍을 조금 할 줄 안다면 더욱 더 이해하기 쉬울 것이다.
이 책에서 다루는 내용
■ 실제 업계에서 머신 러닝 도구를 적용하는 방법
■ R을 사용해 데이터를 분석하기 전에 효과적으로 준비하는 작업
■ 데이터를 효과적으로 시각화하는 방법
■ 분석을 위해 학습용 데이터 세트와 테스트용 데이터 세트를 만드는 이유와 방법에 대한 이해
■ 가장 기본적인 머신 러닝 방법인 선형 회귀와 로지스틱 회귀
■ 서포트 벡터 머신 같은 심화 머신 러닝 방법 이해
■ 아마존 클라우드 서비스에서 R 사용하기
이 책의 대상 독자
데이터 과학자, 데이터 분석가, R을 이용해 머신 러닝을 하는, 실무 지식이 있는 사람들 대상으로 한다. 갖고 있는 기술을 한 단계 더 끌어올려 이 분야에서 전문가가 되고 싶은 사람을 위한 책이다.
2판에 추가된 내용
1장, ‘성공을 위한 과정’에서는 순서도상의 오타를 정정하고 새로운 방법론을 추가했다.
2장, ‘선형 회귀 - 머신 러닝의 기본 기술’에서는 코드를 개선하고 좀 더 나은 도표를 넣었다. 이를 제외하면 초판과 가까운 편이다.
3장, ‘로지스틱 회귀와 판별 분석’에서는 코드를 개선하고 정리했다. 좋아하는 기법인 다변량 적응 회귀 스프라인(multivariate adaptive regression spline)을 추가했는데, 잘 동작하고 비선형 데이터를 다룰 수 있으며 사용하기도 쉽다. 이를 기준 모형으로 사용해 다른 "도전자" 모형들이 이보다 더 성능이 좋은지 살펴본다.
4장, ‘선형 모형에서 고급 피처 선택’에서는 회귀뿐만 아니라 분류 문제도 다룬다.
5장, ‘다른 분류 기법들 - K-최근접 이웃법과 서포트 벡터 머신’에서는 코드를 정리했다.
6장, ‘분류 트리와 회귀 트리’에서는XG부스트(XGBoost) 패키지가 제공하는 매우 좋은 기법을 사용하는 것과 피처를 선택할 때 랜덤 포레스트(random forest) 기법을 사용을 추가했다.
7장, ‘신경망과 딥러닝’에서는 딥러닝 방법에 관한 최신 정보를 넣었고, 하이퍼파라미터(hyperparameter) 검색을 포함해 H2O 패키지에 관련된 코드를 개선했다.
8장, ‘군집화 분석’에서는 랜덤 포레스트를 이용해 비지도학습(unsupervised learning) 방법을 넣었다.
9장, ‘주성분 분석’에서는 다른 데이터 세트를 사용하고, 표본 외 예측(out-of-sample prediction)을 추가했다.
10장, ‘장바구니 분석, 추천 엔진과 순차적 분석’에서는 영업 분야에서 점점 더 중요해지고 있는 순차적 분석(sequential analysis)을 추가했다.
11장, ‘앙상블 생성과 다중 클래스 분류’에서는 여러 패키지를 사용해 완전히 새롭게 썼다.
12장, ‘시계열 자료와 인과관계’에서는 몇 년간의 기후 자료를 더 추가했고, 인과관계를 검사하는 여러 방법을 보여준다.
13장, ‘텍스트 마이닝’에서는 데이터를 추가하고 코드를 개선했다.
14장, ‘클라우드에서 R 사용하기’에서는 클라우드에서 R을 사용하는 법을 쉽고 빠르게 배울 수 있다.
부록 A. ‘R의 기본’에서는 데이터를 다루는 방법을 추가했다.
부록 B. ‘자료 출처’에서는 자료 출처와 참고 자료의 목록을 작성했다.
목차
목차
- 1장. 성공을 위한 과정
- CRISP-DM 모형화 기법
- 비즈니스 이해
- 비즈니스의 목적을 확인하는 것
- 현재의 상황 판단
- 분석적 목표의 결정
- 프로젝트의 진행 계획을 만드는 것
- 데이터 이해
- 데이터 준비
- 모형화
- 평가적용알고리즘 순서도
- 요약
- 2장. 선형 회귀-머신 러닝의 기본 기술
- 단변량 선형 회귀
- 비즈니스 이해하기
- 다변량 선형 회귀
- 비즈니스 이해하기
- 데이터의 이해와 준비 과정
- 모형화와 평가
- 선형 모형에서 다른 고려사항
- 질적 피처
- 상호작용 항
- 요약
- 단변량 선형 회귀
- 3장. 로지스틱 회귀와 판별 분석
- 분류 방법 및 선형 회귀
- 로지스틱 회귀
- 비즈니스 이해하기
- 데이터의 이해와 준비 과정
- 모형화와 평가
- 로지스틱 회귀 모형
- 교차 검증을 포함한 로지스틱 회귀
- 판별 분석의 개요
- 판별 분석의 적용
- 다변량 적응 회귀 스플라인(MARS)
- 모 형 선택
- 요약
- 요약
- 4장. 선형 모형에서 고급 피처 선택
- 규제화(regularization)란?
- 능형 회귀 분석
- LASSO
- 일래스틱넷
- 비즈니스 사례
- 비즈니스 이해하기
- 데이터의 이해와 준비 과정
- 모형화와 평가..
- 최량 부분 집합
- 능형 회귀 분석
- LASSO
- 일래스틱넷
- glmnet을 사용한 교차 검증
- 모형 선택
- 규제화와 분류
- 로지스틱 회귀의 예
- 요약
- 규제화(regularization)란?
- 5장. 다른 분류 기법들 - K-최근접 이웃법과 서포트 벡터 머신
- K-최근접 이웃법
- 서포트 벡터 머신
- 비즈니스 사례
- 비즈니스 이해하기
- 데이터의 이해와 준비 과정
- 모형화와 평가
- 최근접 이웃(KNN) 모형화
- 서포트 벡터 머신 모형화.
- 모형 선택
- 서포트 벡터 머신에서의 피처 선택
- 요약
- 6장. 분류 트리와 회귀 트리
- 개괄적인 방법
- 회귀 트리
- 분류 트리
- 랜덤 포레스트(무작위의 숲)
- 그레이디언트 부스트(경사 부양 기법)
- 비즈니스 사례
- 모형화 및 평가
- 회귀 트리
- 분류 트리
- 랜덤 포레스트 회귀 분석(random forest regression)
- 랜덤 포레스트 분류
- 익스트림 그레디언트 부스트 기법 - 분류
- 모형 선정.
- 랜덤 포레스트를 사용한 피처 선택
- 모형화 및 평가
- 요약
- 개괄적인 방법
- 7장. 신경망과 딥러닝
- 신경망 소개
- 딥러닝, 간단히 살펴보기
- 딥러닝을 위한 자료와 심화 기법
- 비즈니스의 이해
- 데이터의 이해와 준비 과정
- 모형화와 평가
- 딥러닝 예제
- H2O의 배경
- 데이터를 H2O에 업로드하기
- 훈련 및 테스트 데이터 세트 생성
- 모형화
- 요약
- 8장. 군집화 분석
- 계층적 군집화
- 거리 계산
- K-평균 군집화
- 가워와 중간점 구역 분할
- 가워 비유사성 계수
- 중간점 구역 분할 군집화(PAM)
- 랜덤 포레스트
- 비즈니스 이해하기
- 데이터 이해와 준비 과정
- 모형화와 평가
- 계층적 군집화
- K-평균 군집화
- 가워와 중간점 구역 분할
- 랜덤 포레스트와 중간점 구역 분할
- 요약
- 계층적 군집화
- 9장. 주성분 분석
- 주성분의 개요
- 회전
- 비즈니스 이해하기
- 데이터의 이해와 준비 과정
- 모형화와 평가
- 성분 추출
- 직각 회전과 해석
- 성분으로부터 요인 점수 생성
- 회귀 분석
- 요약
- 주성분의 개요
- 10장. 장바구니 분석, 추천 엔진과 순차적 분석
- 장바구니 분석의 개요
- 비즈니스 이해하기
- 데이터의 이해와 준비 과정
- 모형화와 평가
- 추천 엔진의 개요
- 사용자 기반 협업 필터링
- 아이템 기반 협업 필터링
- 특이값 분해와 주성분 분석
- 비즈니스 이해와 추천
- 데이터의 이해와 준비 과정과 추천
- 모형화와 평가 그리고 추천하기
- 순차적 데이터 분석
- 순차적 데이터 분석의 적용
- 요약
- 11장. 앙상블 생성과 다중 클래스 분류
- 앙상블
- 비즈니스와 데이터 이해하기
- 모형화와 평가 그리고 선택
- 비즈니스와 데이터 이해하기
- 모형 평가와 선택
- 랜덤 포레스트
- 능형 회귀 분석
- MLR에서의 앙상블
- 요약
- 12장. 시계열 자료와 인과관계
- 단변량 시계열 분석
- 그랜저 인과관계 이해하기
- 비지니스 이해하기
- 데이터의 이해와 준비 과정
- 모형화와 평가
- 단변량 시계열 예측
- 인과관계의 검사
- 선형 회귀
- 벡터 자기회귀 모형(Vector autoregression)
- 요약
- 단변량 시계열 분석
- 13장. 텍스트 마이닝
- 텍스트 마이닝 프레임워크와 기법
- 주제(topic) 모형
- 그 밖의 정량 분석 기법
- 비즈니스 이해
- 데이터의 이해와 준비
- 모형화와 평가
- 단어 빈도와 주제 모형
- 또 다른 양적 분석 기법
- 요약
- 14장. 클라우드에서 R 사용하기
- 아마존 웹 서비스 계정 생성하기
- 가상 머신 실행
- RStudio 시작하기
- 요약
- 아마존 웹 서비스 계정 생성하기
- 부록. A R의 기본
- R을 실행하기
- R 사용하기
- 데이터 프레임과 행렬
- 요약 통계 내기
- 패키지를 설치하고 로드하기
- dplyr 패키지를 이용해 데이터 다루기
- 요약
도서 오류 신고
정오표
정오표
[p.67 : 아래서 2행]
which.mean()
->
which.min()
[p.68 : 두 번째 문단 1행]
멜로(Mallow)의 Cp,
->
맬로우즈(Mallows)의 Cp,
[p.69 : 두 번째 식]
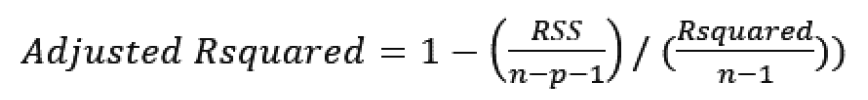
->
Adjusted R squared = 1 - (1 - R-squared) * (n - 1) / (n - p -1)
또는
Adjusted R squared = 1 - (RSS / (n - p - 1)) / (TSS / (n - 1))
TSS : total sum of squares