책 소개
소스 코드 파일은 여기에서 내려 받으실 수 있습니다.
2022년 대한민국학술원 우수학술도서 선정도서
요약
머신러닝 방법을 금융에 도입하는 혁신적인 방법을 보여준다. 총 3부로 구성되며 각각 이론과 실전 응용을 다룬다. 1부는 베이지안과 빈도주의 각각의 관점에서 횡단면 데이터 분석을 위한 지도학습 방법론을 설명하고, 고급 기법인 가우시안 프로세스 및 딥러닝을 투자 관리와 파생상품 모델링에 적용하는 예제를 보여준다. 2부는 금융 시계열 데이터에 대한 다양한 지도학습 방법을 트레이딩과 확률적 변동성 및 고정소득 분석에 적용하는 것을 알려준다. 마지막으로 3부에서는 최첨단의 강화학습 및 역강화학습의 트레이딩, 투자 및 자산관리에의 응용을 제시한다. 결정적으로 마지막 장에서 미래 연구를 위해 금융에서의 머신러닝의 최첨단 분야를 제시하며 물리학과의 대통합을 시도한다. 이해를 돕기 위해 파이썬 코드 예제들을 제공한다.
이 책의 대상 독자
계량 금융, 데이터 과학, 분석, 핀테크 분야의 경력을 쌓으려는 데이터 과학, 수학 금융, 금융 공학, 경영 과학 연구 분야의 대학원생을 대상으로 한다. 선형 대수학, 다변량 미적분학, 고급 확률 이론, 확률 과정, 시계열 통계학(계량경제학)의 고학년 학부 과정을 이수하고 수치 최적화와 계산 수학에 대해 기본적으로 이해하고 있어야 한다. 이 책의 후반부에 있는 강화학습은 투자 과학에 대한 약간의 배경지식만 있다면 더 쉽게 접근할 수 있다. 또한 파이썬 프로그래밍에 대한 사전 경험이 있어야 하며, 이상적으로는 컴퓨터 금융 및 입문 머신러닝에 대한 강의를 듣는 것이 좋다. 이 책의 자료는 머신러닝에 대한 대부분의 과정보다 수학적이고 공학에 덜 집중돼 있으며, 이러한 이유로 길버트 스트랭(Gilbert Strang)의 최신 서적인 『딥러닝을 위한 선형대수학(Linear Algebra and Learning from Data)』을 기본으로 읽을 것을 추천한다.
이 책의 구성
1장
금융 산업의 머신러닝 필요성과 채택에 대한 고유한 장벽을 형성한 중요한 사건을 논의하며 금융 머신러닝의 산업 맥락을 짚는다. 머신러닝의 특성과 머신러닝이 실제로 어떻게 사용되는지를 보여주는 몇 가지 수학적 핵심 예를 살펴본다.2장
확률적 모델링을 소개하고 베이지안 추론, 모델 선택, 온라인 학습, 베이지안 모델 평균화와 같은 베이지안 계량학의 기본 개념을 검토한다.3장
베이지안 회귀분석을 소개하고 이전 장의 많은 개념을 어떻게 확장하는지 보여준다. 커널 기반 머신러닝 방법(특히 베이지안 머신러닝 방법의 중요한 클래스인 가우시안 프로세스 회귀)을 개발하고 파생상품 가격의 모델을 ‘대리’하기 위한 이들의 적용을 입증한다.4장
지도학습, 딥러닝, 신경망에 대해 좀 더 심층적으로 설명하며, 기초적인 수학과 통계 학습 개념을 제시하고 이들이 트레이딩, 위험 관리, 투자 관리에서 실제 사례와 어떻게 관련돼 있는지 설명한다.5장
신경망 설계에 최소한의 제한을 가하는 신경망 해석 방법을 제시한다. 특성 중요도에 순위를 매기는 방법을 포함해 순전파 신경망을 해석하는 기법을 시연한다.6장
금융 계량경제학에서 가장 중요한 모델링 개념에 대한 개요를 제공한다.7장
재무 데이터에 대한 강력한 종류의 확률적 모델을 제시한다. 다양한 알고리듬으로 금융에서의 은닉 마르코프 모델과 입자 필터의 간단한 예를 제시한다.8장
금융 시계열 분석을 위한 다양한 신경망 모델을 제시하며, 이러한 모델이 금융 계량경제학에서 잘 알려진 기술과 어떻게 관련되는지 보여주는 예를 제공한다. 또한 시계열 데이터를 필터링하고 데이터의 다른 척도를 활용하기 위한 합성곱 신경망(CNN)도 제시한다. 마지막으로 오토인코더가 정보를 압축하고 주성분 분석을 일반화하는 데 어떻게 사용되는지 보여준다.9장
마르코프 의사결정 프로세스와 동적 프로그래밍의 고전적인 방법을 소개하고 강화학습의 아이디어와 MDP를 해결하기 위한 다른 근사 방법을 제공한다. Q 러닝으로 이동하기 전에 벨만 최적성, 반복 가치와 정책 업데이트를 설명한 후 탐욕, 배치 학습, Q 러닝과 같은 주요 계산 개념을 다루면서 주제에 대한 좀 더 엔지니어링 스타일의 설명으로 빠르게 진행한다.10장
앞서 제시한 이론을 발전시키고 더불어 금융에 대한 강화학습을 실제로 적용해본다. 기존의 블랙-숄즈 모델을 Q 러닝을 이용한 데이터 중심 접근법으로 일반화하는 옵션 가격 결정 강화학습 접근법을 소개한다. 그런 다음 G-러닝이라는 Q 러닝의 확률론적 확장을 제시하고 동적 포트폴리오 최적화에 어떻게 사용할 수 있는지를 보여준다.11장
역강화학습(IRL)과 모방학습(IL)의 가장 인기 있는 방법에 대한 개요를 살펴본다. 그런 다음 트레이딩 전략 식별, 감성 기반 트레이딩, 옵션 가격 결정, 포트폴리오 투자자의 추론, 시장 모델링에 대한 애플리케이션을 포함하는 계량 금융에서 IRL의 사용 사례를 살펴본다.12장
계량 금융과 머신러닝에서 새롭게 부상하는 연구 주제를 설명한다. 에이전트의 인지-행동 주기의 두 가지 작업으로 지도학습과 강화학습의 통합을 다루며, 시장 역학 모델을 구성하고자 강화학습 방법을 사용하는 것도 다룬다. 또한 이러한 RL에서 영감을 받은 시장 모델에 대한 계산을 위한 몇 가지 고급 물리학 기반 접근법을 소개한다.상세 이미지

목차
목차
- 1부. 횡단면 데이터를 사용한 머신러닝
- 1장. 정보 이론 입문
- 1. 배경
- 1.1 빅데이터: 금융 분야의 빅 컴퓨팅
- 1.2 핀테크
- 2. 머신러닝과 예측
- 2.1 엔트로피
- 2.2 신경망
- 3. 통계 모델링과 머신러닝
- 3.1 모델링 패러다임
- 3.2 금융 계량경제학과 머신러닝
- 3.3 과적합
- 4. 강화학습
- 5. 지도 머신러닝 실제 사례
- 5.1 알고리듬 트레이딩
- 5.2 고빈도 트레이드 실행
- 5.3 모기지 모델링
- 6. 요약
- 7. 연습문제
- 부록
- 참고 문헌
- 2장. 확률 모델링
- 1. 서론
- 2. 베이지안 대 빈도주의 추정
- 3. 데이터로부터 빈도주의 추정
- 4. 추정량의 품질 평가: 편향과 분산
- 5. 추정량에 대한 편향-분산 트레이드오프(딜레마)
- 6. 데이터로부터 베이지안 추론
- 6.1 더 정보성이 큰 사전분포: 베타 분포
- 6.2 순차적 베이지안 업데이트
- 6.3 고전적 또는 베이지안 추정 프레임워크 선택의 실무적 의미
- 7. 모델 선택
- 7.1 베이지안 추론
- 7.2 모델 선택
- 7.3 많은 모델이 있을 때 모델 선택
- 7.4 오캠의 면도날
- 7.5 모델 평균화
- 8. 확률적 그래프 모델
- 8.1 혼합 모델
- 9. 요약
- 10. 연습문제
- 부록
- 참고 문헌
- 3장. 베이지안 회귀와 가우시안 프로세스
- 1. 서론
- 2. 선형회귀를 활용한 베이지안 추론
- 2.1 최대 우도 추정
- 2.2 베이지안 예측
- 2.3 슈어 항등식
- 3. 가우시안 프로세스 회귀
- 3.1 금융에서 가우시안 프로세스
- 3.2 가우시안 프로세스 회귀와 예측
- 3.3 하이퍼파라미터 튜닝
- 3.4 계산 특성
- 4. 대규모 확장 가능 가우시안 프로세스
- 4.1 구조 커널 보간(SKI)
- 4.2 커널 근사
- 5. 예제: 단일 GP를 활용한 가격 결정과 그릭 계산
- 5.1 그릭 계산
- 5.2 메시 프리 GP
- 5.3 대규모 확장 가능 GP
- 6. 다중 반응 가우시안 프로세스
- 6.1 다중 출력 가우시안 프로세스 회귀와 예측
- 7. 요약
- 8. 연습문제
- 8.1 프로그래밍 연관 문제
- 부록
- 참고 문헌
- 4장. 순전파 신경망
- 1. 서론
- 2. 순전파 구조
- 2.1 예비지식
- 2.2 순전파 네트워크의 기하학적 해석
- 2.3 확률적 추론
- 2.4 딥러닝을 활용한 함수 근사*
- 2.5 VC 차원
- 2.6 신경망이 스플라인인 경우
- 2.7 왜 심층 네트워크를 사용하는가?
- 3. 볼록성과 부등식 제약식
- 3.1 MLP와 다른 지도학습기와의 유사성
- 4. 훈련, 검증, 테스트
- 5. 확률적 그래디언트 하강법(SGD)
- 5.1 역전파
- 5.2 모멘텀
- 6. 베이지안 신경망*
- 7. 요약
- 8. 연습문제
- 8.1 프로그래밍 연관 문제*
- 부록
- 참고 문헌
- 5장. 해석 가능성
- 1. 서론
- 2. 해석 가능성에 대한 배경
- 2.1 민감도
- 3. 신경망의 설명력
- 3.1 다중 은닉층
- 3.2 예제: 스텝 테스트
- 4. 상호작용 효과
- 4.1 예제: 프리드만 데이터
- 5. 자코비안 분산에 대한 상한
- 5.1 체르노프 상한
- 5.2 시뮬레이션 예제
- 6. 팩터 모델링
- 6.1 비선형 팩터 모델
- 6.2 펀더멘털 팩터 모델링
- 7. 요약
- 8. 연습문제
- 8.1 프로그래밍 연관 문제
- 부록
- 참고 문헌
- 2부. 순차적 학습
- 6장. 시퀀스 모델링
- 1. 서론
- 2. 자기회귀 모델링
- 2.1 예비지식
- 2.2 자기회귀 프로세스
- 2.3 안정성
- 2.4 정상성
- 2.5 편자기상관관계
- 2.6 최대 우도 추정
- 2.7 이분산성
- 2.8 이동 평균 프로세스
- 2.9 GARCH
- 2.10 지수 평활화
- 3. 시계열 모델 적합화: 박스-젠킨스 접근법
- 3.1 정상성
- 3.2 정상성을 보장하는 변환
- 3.3 식별
- 3.4 모델 진단
- 4. 예측
- 4.1 예측 이벤트
- 4.2 시계열 교차 검증
- 5. 주성분 분석
- 5.1 주성분 투영
- 5.2 차원 축소
- 6. 요약
- 7. 연습문제
- 부록
- 참고 문헌
- 7장. 확률적 시퀀스 모델
- 1. 서론
- 2. 은닉 마르코프 모델링
- 2.1 비터비 알고리듬
- 2.2 상태-공간 모델
- 3. 입자 필터링
- 3.1 순차적 중요도 리샘플링(SIR)
- 3.2 다항 리샘플링
- 3.3 응용: 확률적 변동성 모델
- 4. 확률적 필터의 점 보정
- 5. 확률적 필터의 베이지안 보정
- 6. 요약
- 7. 연습문제
- 부록
- 참고 문헌
- 8장. 고급 신경망
- 1. 서론
- 2. 순환 신경망
- 2.1 RNN 메모리: 편자기공분산
- 2.2 안정성
- 2.3 정상성
- 2.4 일반화된 신경망(GRNN)
- 3. GRU
- 3.1 α-RNNs
- 3.2 신경망 지수 평활화
- 3.3 LSTM
- 4. 파이썬 노트북 예제
- 4.1 비트코인 예측
- 4.2 지정가 주문 호가창으로부터 예측
- 5. 합성곱 신경망
- 5.1 가중 이동 평균 평활기
- 5.2 2D 합성곱
- 5.3 풀링
- 5.4 팽창 합성곱
- 5.5 파이썬 노트북
- 6. 오토인토더
- 6.1 선형 오토인코더
- 6.2 선형 오토인코더와 PCA의 동등성
- 6.3 딥 오토인코더
- 7. 요약
- 8. 연습문제
- 8.1 프로그래밍 관련 질문*
- 부록
- 참고 문헌
- 3부. 순차적 데이터와 의사결정
- 9장 강화학습 소개
- 1. 서론
- 2. 강화학습의 요소
- 2.1 보상
- 2.2 가치와 정책 함수
- 2.3 관측 가능 대 부분 관측 가능 환경
- 3. 마르코프 의사결정 프로세스
- 3.1 의사결정 정책
- 3.2 가치 함수와 벨만 방정식
- 3.3 최적 정책과 벨만 최적성
- 4. 동적 프로그래밍 방법
- 4.1 정책 평가
- 4.2 정책 반복
- 4.3 가치 반복
- 5. 강화학습법
- 5.1 몬테카를로 방법
- 5.2 정책 기반 학습
- 5.3 시간 차이 학습
- 5.4 SARSA와 Q 러닝
- 5.5 확률 근사와 배치 모드 Q 러닝
- 5.6 연속 공간에서의 Q 러닝: 함수근사
- 5.7 배치 모드 Q 러닝
- 5.8 최소 자승 정책 반복
- 5.9 심층 강화학습
- 6. 요약
- 7. 연습문제
- 부록
- 참고 문헌
- 10장. 강화학습 응용
- 1. 서론
- 2. 옵션 가격 결정을 위한 QLBS
- 3. 이산 시간 블랙-숄즈-머튼 모델
- 3.1 헷징 포트폴리오 평가
- 3.2 최적 헷징 전략
- 3.3 이산 시간에서의 옵션 가격 결정
- 3.4 BS 극한에서의 헷징과 가격 결정
- 4. QLBS 모델
- 4.1 상태 변수
- 4.2 벨만 방정식
- 4.3 최적 정책
- 4.4 DP 해: 몬테카를로 구현
- 4.5 QLBS에 대한 RL 해: 적합화된 Q 반복(FQI)
- 4.6 예제
- 4.7 옵션 포트폴리오
- 4.8 가능한 확장
- 5. 주식 포트폴리오를 위한 G-러닝
- 5.1 서론
- 5.2 투자 포트폴리오
- 5.3 최종 조건
- 5.4 자산 수익률 모델
- 5.5 시그널 동학과 상태 공간
- 5.6 1기간 보상
- 5.7 다기간 포트폴리오 최적화
- 5.8 확률적 정책
- 5.9 준거 정책
- 5.10 벨만 최적 방정식
- 5.11 엔트로피 규제화 벨만 최적성 방정식
- 5.12 G-함수: 엔트로피 규제화 Q 함수
- 5.13 G-러닝과 F-러닝
- 5.14 시장 충격을 가진 포트폴리오 동학
- 5.15 제로 함수 극한: 엔트로피 규제화를 가진 LQR
- 5.16 영이 아닌 시장 충격: 비선형 동학
- 6. 자산 관리를 위한 RL
- 6.1 머튼 소비 문제
- 6.2 확정 기여형 퇴직 플랜을 위한 포트폴리오 최적화
- 6.3 은퇴 플랜 최적화를 위한 G-러닝
- 6.4 논의
- 7. 요약
- 8. 연습문제
- 부록
- 참고 문헌
- 11장. 역강화학습과 모방학습
- 1. 서론
- 2. 역강화학습
- 2.1 RL 대 IRL
- 2.2 IRL의 성공 기준은 무엇인가?
- 2.3 진정으로 전이 가능한 보상 함수가 IRL로 학습될 수 있을까?
- 3. 최대 엔트로피 역강화학습
- 3.1 최대 엔트로피 원리
- 3.2 최대 인과 엔트로피
- 3.3 G-러닝과 소프트 Q 러닝
- 3.4 최대 엔트로피 IRL
- 3.5 분배 함수 추정
- 4. 예제: 소비자 선호 추론을 위한 MaxEnt IRL
- 4.1 IRL과 소비자 선택 문제
- 4.2 소비자 효용 함수
- 4.3 소비자 효용을 위한 최대 엔트로피 IRL
- 4.4 데이터가 얼마나 필요한가? IRL과 관측 잡음
- 4.5 반사실적 시뮬레이션
- 4.6 MLE 추정량의 유한-샘플 속성
- 4.7 논의
- 5. 적대적 모방학습과 IRL
- 5.1 모방학습
- 5.2 GAIL: 적대적 생성 모방학습
- 5.3 IRL에서 RL을 우회하는 기술로서의 GAIL
- 5.4 GAIL에서의 실제적 규제화
- 5.5 GAIL에서의 적대적 학습
- 5.6 다른 적대적 접근법*
- 5.7 f-발산 훈련*
- 5.8 와서스타인 GAN*
- 5.9 최소 제곱 GAN*
- 6. GAIL을 넘어: AIRL, f-MAX, FAIRL, RS-GAIL 등*
- 6.1 AIRL: 적대적 역강화학습
- 6.2 전방 KL 또는 후방 KL?
- 6.3 f-MAX
- 6.4 순방향 KL: FAIRL
- 6.5 리스크 민감 GAIL(RS-GAIL)
- 6.6 요약
- 7. 가우시안 프로세스 역강화학습
- 7.1 베이지안 IRL
- 7.2 가우시안 프로세스 IRL
- 8. IRL은 교사를 능가할 수 있을까?
- 8.1 실패로부터의 IRL
- 8.2 학습 선호
- 8.3 T-REX: 경로-순위 보상 외삽
- 8.4 D-REX: 교란-기반 보상 외삽
- 9. 금융 절벽 걷기를 위한 IRL의 시도
- 9.1 최대 인과 엔트로피 IRL
- 9.2 실패로부터 IRL
- 9.3 T-REX
- 9.4 요약
- 10. IRL의 금융 응용
- 10.1 알고리듬 트레이딩 전략 식별
- 10.2 옵션 가격 결정을 위한 역강화학습
- 10.3 G-러닝과 포트폴리오 투자가의 IRL
- 10.4 감성 기반 트레이딩 전략을 위한 IRL과 보상학습
- 10.5 IRL과 ‘보이지 않는 손’ 추론
- 11. 요약
- 12. 연습문제
- 부록
- 참고 문헌
- 12장. 머신러닝과 금융의 최전선
- 1. 서론
- 2. 시장 동학, 역강화학습과 물리학
- 2.1 ‘퀀텀 균형-불균형’(QED) 모델
- 2.2 랑주뱅 방정식
- 2.3 랑주뱅 방정식으로서 GBM 모델
- 2.4 랑주뱅 방정식으로서 QED 모델
- 2.5 금융 모델링에 대한 통찰력
- 2.6 머신러닝에 대한 통찰력
- 3. 물리학과 머신러닝
- 3.1 딥러닝과 물리학에서의 계층적 표현
- 3.2 텐서 네트워크
- 3.3 불균형 환경에서의 제한된 합리적 에이전트
- 4. 머신러닝의 ‘대통합’
- 4.1 인지-행동 주기
- 4.2 정보 이론과 강화학습의 접점
- 4.3 강화학습과 지도학습: 예측, MuZero와 다른 새로운 아이디어
- 참고 문헌
도서 오류 신고
정오표
정오표
[p. 420: 6행]
이 설정에서 출력 레이블을 특정 입력 데이터에 할당하는 것은 에이전트의 ‘해동’으로 볼 수 있다.
->
이 설정에서 출력 레이블을 특정 입력 데이터에 할당하는 것은 에이전트의 ‘행동’으로 볼 수 있다.
[p. 154 : 식 (3.14), (3.15)]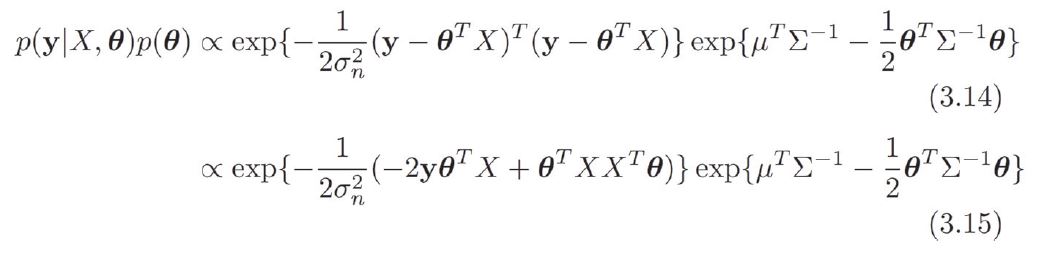 ->
->