


자연어 처리 쿡북 with 파이썬 [파이썬으로 NLP를 구현하는 60여 가지 레시피]
- 원서명Natural Language Processing with Python Cookbook: Over 60 recipes to implement text analytics solutions using deep learning principles (ISBN 9781787289321)
- 지은이크리슈나 바브사(Krishna Bhavsar), 나레쉬 쿠마르(Naresh Kumar), 프라탑 단게티(Pratap Dangeti)
- 옮긴이지은
- ISBN : 9791161752655
- 30,000원
- 2019년 01월 31일 펴냄
- 페이퍼백 | 344쪽 | 188*235mm
- 시리즈 : 데이터 과학
책 소개
소스 코드 파일은 여기에서 내려 받으실 수 있습니다.
요약
최고의 플랫폼인 파이썬과 자연어 툴킷(NLTK)을 이용해 자연어 처리(NLP)를 수행하는 다양한 방법을 알려주는 독창적인 레시피가 담긴 책이다. 자연어 이해(NLU), 자연어 처리, 구문 분석 등 다양한 주제를 포함해 자연어를 다루는 데 사용할 수 있는 60여 개의 레시피를 접할 수 있다. 자연어 처리에 입문하면서 궁금한 부분이 생기면 레시피를 찾아보듯이 필요한 부분을 꺼내볼 수 있게 구성했다. 실용적인 감정 분석부터 최신 딥러닝 기술의 적용 방법까지 배울 수 있다. 이 책을 마치면 파이썬으로 NLP를 구현하는 데 필요한 모든 지식을 얻게 될 것이다.
이 책에서 다루는 내용
■ NLTK에서 사용할 수 있는 다양한 말뭉치 탐색과 워드넷 말뭉치 사용법
■ HTML, RSS, PDF, 워드 문서 등과 같은 원시 텍스트 관리와 처리
■ 토큰화, 형태소 분석, 철자 검사기 등과 같은 기술을 사용해 원시 텍스트를 전처리하는 방법과 정규표현식을 사용한 구현
■ 정규표현식을 사용한 텍스트 분석의 패턴 일치 기본 사항
■ 품사 태거와 문법을 사용해 직접 만드는 방법
■ 개체명(NE) 추출 방법과 RD, 시프트 감소, 차트 파서 등의 파서
■ LSTM을 사용한 셰익스피어 소설에서의 텍스트 생성
■ BABI 데이터셋과 LSTM을 사용한 에피소드 모델링
■ 딥러닝을 통해 생성(generative) 방식으로 개발하는 챗봇
이 책의 대상 독자
NLP를 사용해 고급 텍스트 분석을 구현하고자 기존 기술을 업그레이드하려는 데이터 과학자, 데이터 분석가를 대상으로 한다. 자연어 처리에 대한 몇 가지 기본 지식이 있으면 좋다.
이 책의 구성
1장, ‘말뭉치와 워드넷’에서는 NLTK에서 기본 제공하는 말뭉치와 빈도 분포에 접근하는 방법을 알아본다. 워드넷이 무엇인지 알아보고 그 기능과 사용법을 탐구할 것이다.
2장, ‘원시 텍스트, 소싱, 정규화’에서는 다양한 형식의 데이터 소스에서 텍스트를 추출하는 방법을 보여준다. 웹상에서 원시 텍스트를 추출하는 방법도 배우게 된다. 이러한 이질적인 소스로부터 원시 텍스트를 정규화하고, 텍스트를 말뭉치로 조직화할 것이다.
3장, ‘전처리’에서는 토큰화, 스테밍, 원형 복원, 편집 거리와 같이 몇 가지 중요한 사전 처리 단계를 소개한다.
4장, ‘정규표현식’에서는 가장 기본적이고 간단하지만 가장 중요하면서 강력한 도구 중 하나를 다룬다. 텍스트 분석을 수행하는 방법으로 패턴 매칭의 개념을 배우게 되며, 이를 위해 정규표현식보다 더 좋은 도구는 없다.
5장, ‘품사 태깅과 문법’에서는 품사 태깅은 구문 분석의 기초를 형성하며 문법은 품사 태그 및 청크를 사용해 형성되고 변형될 수 있다. 자체 품사 태거 및 문법을 사용하고 또 작성하는 법을 배운다.
6장, ‘청킹, 문장 구문 분석, 의존성’에서는 기본 제공 청커를 사용하는 방법을 배우고 자체 청커(의존성 파서)를 학습/작성하는 데 도움을 준다. 6장에서는 훈련된 모델을 평가하는 방법을 배우게 된다.
7장, ‘정보 추출과 텍스트 분류’에서는 개체명 인식에 대해 자세히 알려준다. 내장된 개체명을 사용하거나 딕셔너리를 사용해 개체명을 생성할 것이다. 기본 제공되는 텍스트 분류 알고리즘과 애플리케이션 주변의 간단한 레시피를 사용하는 방법을 배워보자.
8장, ‘고급 NLP 레시피’에서는 지금까지 모든 수업을 결합하고 실제 응용문제에 쉽게 적용할 수 있는 응용 가능한 레시피를 만드는 방법에 관한 것이다. 텍스트 유사도, 요약, 감정 분석, 표현 합성, 대용어 처리 등과 같은 레시피를 작성한다.
9장, ‘NLP에서의 딥러닝 적용’에서는 이메일 분류, CNN 및 LSTM의 감정 분류, 마지막으로 저차원 공간에서의 고차원 단어 시각화와 같은 NLP 문제의 애플리케이션을 사용하는 딥러닝에 필요한 다양한 기본적인 사항을 전달한다.
10장, ‘NLP 분야에서 딥러닝의 고급 응용’에서는 딥러닝을 이용한 최첨단 문제 해결 방법을 설명한다. 단편적인 사건들로 이뤄진 데이터에 대한 답변, 다음 최상의 단어를 예측하기 위한 언어 모델링 그리고 생성 기법을 사용하는 챗봇(chatbot) 개발을 포함한다.
목차
목차
- 1장. 말뭉치와 워드넷
- 도입
- 내장 말뭉치에 액세스하기
- 외부 말뭉치의 다운로드, 로드하고 액세스하기
- 브라운 코퍼스에서 세 가지 장르의 의문사 단어를 모두 세기
- 웹 및 채팅 텍스트 말뭉치 파일의 빈도 분포 작업 탐색하기
- 모호한 단어에서 워드넷을 사용해 모든 뜻을 탐색하기
- 워드넷을 이용한 별개의 두 synsets을 선택하고 하위어와 상위어의 개념 탐구하기
- 워드넷에 따라 명사, 동사, 형용사, 부사의 평균 다차원을 계산하기
- 2장. 원시 텍스트, 소싱, 정규화
- 소개
- 문자열 작업의 중요성
- 더 깊이 있는 문자열 연산
- 파이썬에서 PDF 파일 읽기
- 파이썬으로 워드(Word) 문서 읽기
- PDF, DOCX, 일반 텍스트 파일을 가져와 사용자 정의 말뭉치 만들기
- RSS 피드의 내용 읽기
- BeautifulSoup을 이용한 HTML 파싱하기
- 3장. 전처리
- 개요
- 토큰화-NLTK의 내장 토크나이저 사용법 배우기
- 스테밍-NLTK의 내장 스테머 사용법 배우기
- 원형 복원-NLTK의 WordnetLemmatizer 사용법 배우기
- 불용어-불용어 말뭉치 사용법 및 불용어가 만들어내는 차이점 확인하기
- 편집 거리-두 문자열 간의 편집 거리를 찾기 위한 알고리즘 작성
- 두 단문 처리 및 둘 사이의 공통 어휘 추출하기
- 4장. 정규표현식
- 개요
- 정규표현식–*, +, ? 배우기
- 정규표현식–$와 ^ 그리고 단어의 시작과 끝이 아닌 것을 사용하는 방법 학습하기
- 여러 개의 리터럴 문자열 및 하위 문자열 발생 찾기
- 날짜 정규식과 문자 집합 또는 문자 범위 생성 방법 배우기
- 모든 다섯 글자 단어를 찾고 일부 문장에서 약어를 작성
- 독자적인 정규식 토크나이저 작성 방법
- 자체 정규식 스테머 작성법 배우기
- 5장. 품사 태깅과 문법
- 소개
- 기본 제공 태거 탐색하기
- 자체 태거 작성하기
- 자체 태거 학습시키기
- 자체 문법 작성법 배우기
- 확률적 CFG 작성하기
- 재귀적 CFG 작성하기
- 6장. 청킹, 문장 구문 분석, 의존성
- 소개
- 내장 청커 사용하기
- 간단한 자체 청커 작성하기
- 청커 학습시키기
- 재귀적 파생 구문 분석
- shift-reduce 구문 분석
- 의존성 문법과 투영 종속성 분석
- 차트 파싱하기
- 7장. 정보 추출과 텍스트 분류
- 소개
- 내장 NER 사용
- 딕셔너리 생성, 반전, 사용하기
- 피처셋 선택하기
- 분류기를 사용해 문장 분할하기
- 문서 분류하기
- 문맥 기반 품사 태거 만들기
- 8장. 고급 NLP 레시피
- 소개
- NLP 파이프라인 생성하기
- 텍스트 유사도 문제 해결하기
- 주제 식별하기
- 텍스트 요약하기
- 대용어 처리하기
- 단어의 중의성 해소
- 감정 분석 수행
- 고급 감정 분석 탐구
- 대화형 비서 혹은 챗봇 만들기
- 9장. NLP에서의 딥러닝 적용
- 소개
- TF-IDF 생성 후 DNN을 사용해 이메일 분류하기
- 합성곱망 CNN 1D를 이용한 IMDB 감정 분류하기
- 양방향 LSTM을 사용하는 IMDB 감정 분류하기
- 신경 워드 벡터 시각화를 사용해 고차원 단어를 2D에 시각화하기
- 10장. NLP분야에서 딥러닝의 고급 응용
- 소개
- LSTM을 사용해 셰익스피어의 문장에서 고급 자동 텍스트 생성하기
- 메모리 네트워크를 사용해 에피소드 데이터에 대한 질의 응답하기
- 순환 신경망 LSTM을 사용해 다음 단어를 예측하는 언어 모델링
- 순환 신경망(LSTM)을 사용하는 생성형 챗봇
관련 블로그 글
컴퓨터와 인간의 소통 방법, 자연어 처리

최근 핸드폰, 스피커, 리모콘
등 다양한 기계를 음성 인식으로 조작하는 모습을 쉽게 볼 수 있다.
단순한 기계 조작은 물론이고 실제 사람과 대화하듯이 궁금한 것을 묻고 답하는 것도 가능하다.
이외에도 기계 번역, 챗봇, 검색 엔진 등 다양한 분야에서 자연어 처리 기술을 쉽게 찾아볼 수 있다.

자연어: 일반 사회에서 자연히 발생하여 쓰이는 언어로, 인공적으로 만들어진 언어인 인공어와 구분하여 부르는 개념
인공어: 자연적으로 생성된 자연어와 달리 한 사람이나 여러 사람의 의도와 목적에 따라 만들어진 언어
자연어 처리란 사용자가 입력하는 자연어를 분석하고 처리해 컴퓨터가 이해할 수 있는 형태로 만드는 기술이다.
자연어 처리에는 사람들이 사용하는 다양한 단어와 각 단어가 사용되는 상황, 상호작용하는 방식 등 방대한 양의 언어 데이터가 필요하며, 사용자가 입력한 데이터의 형태, 구문, 의미 등의 분석을 통해 텍스트를 이해하고 적합한 결과를 출력한다.
지난해 10월 구글은 AI 언어 모델인 버트(BERT)를 발표했다.
버트는 구글의 딥러닝 아키텍처인 '트랜스포머'로 구성된 자연어 처리 모델로 대표적인 자연어 처리 평가 지표인 GLUE(General Language Understanding Evaluation)와 SQuAD(Stanford Question Answering Dataset) 중 일부 항목에서 인간보다 뛰어난 성적을 보이면서 많은 주목을 받기도 했다.

활용 사례 1.
태블로 소프트웨어(Tableau Software)는 자연어 질의를 지원하는 애스크 데이터(Ask Data)를 발표했다.
애스크 데이터를 사용해 확인하고 싶은 내용을 입력하면 그에 대한 답변을 시각화 자료로 보여준다.
활용 사례 2.
아시아나항공의 챗봇 서비스 아론(Aron)에서는 간단한 문의는 물론 항공권 예약과 구매까지 가능해졌다.
아론은 애저(Azure)와 루이스(LUIS)를 활용해 개발됐으며, 다양한 메신저와 애플리케이션을 통해 서비스를 제공하고 있다.
활용 사례 3.
퀄컴 테크놀로지는 아마존의 '알렉사 보이스 서비스' 개발 키트를 기반으로 개발한 퀄컴 스마트 오디오 플랫폼을 시연했다.
차량에 설치된 스마트 오디오 플랫폼을 통해 음성으로 길을 검색하거나 음악, 영상을 재상할 수도 있다.

자연어 처리 with 파이썬은 파이썬과 자연어 툴킷(NLTK)을 이용해 자연어 처리(NLP)를 수행하는 다양한 방법을 알려주는 독창적인 레시피가 담긴 책이다.
자연어 이해, 자연어 처리, 구문 분석 등 다양한 주제를 포함해 실용적인 감정 분석부터 최신 딥러닝 기술의 적용 방법까지 자연어를 다루는 데 사용할 수 있는 60여 개의 레시피를 접할 수 있다.
자연어 처리에 관심이 있는 독자라면 이 책을 통해 다양한 상황에서 자연어 처리를 어떻게 구현하는지 확인해보자.

크리에이티브 커먼즈 라이센스 이 저작물은 크리에이티브 커먼즈 코리아 저작자표시 2.0 대한민국 라이센스에 따라 이용하실 수 있습니다.
도서 오류 신고
정오표
정오표
[p.14 : 아래서 3행]
원시 텍스트, 소싱, 정규화
->
처리 전 텍스트, 소싱, 정규화
[p.30 : 3행]
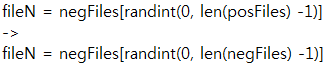
[p.41: 코드 2행]

[p.42: 3번 코드]

->
[p.44 : 9행]
Types of beds(Hyponyms)
->
bed의 형태(하위어)
[p.56 : 끝에서 1행]
https://www.dropbox.com/sh/bk18dizhsu1p534/AABEuJw4TArUbzJf4Aa8gp5Wa?dl=0
->
http://bit.ly/nlp-python-cookbook
[p.58 : 3행]
for i in range(0,readpdf.getNumPages()-1):
->
for i in range(0, readpdf.getNumPages() ):
또는
for i in range(read_pdf.getNumPages()):
[p.63 : 3행]

[p.75 : 1행]

[p.75 : 3행]

[p.79 : 16행]
출력 :"
->
출력 : "
[p.115 : 7행]
('2017',
->
('2018',
[p.115 : 12행]
('2017',
->
('2018',
[p.181 : 8행]
'Bangalore' | 'Karnataka'
->
'Seoul' | 'Korea'
[p.213 : 이미지 안 3행]
Bangalore?",
->
Seoul?",
[p.249 : 5행]

[p.251 : 아래서 5-6행]

[p.267 : 이미지 안 15행]
unknown built-in chat engine {}
->
알 수 없는 내장 채팅 엔진 {}
[p.271 : 아래서 2행]
모두 종료되면 engines are excited-> exited my Engine()을
->
모두 종료되면 myEngine()을