


파이썬과 수치 해석 2/e [파이썬 수치 해석 레시피]
- 원서명Numerical Python, 2nd Edition: Scientific Computing and Data Science Applications with Numpy, SciPy and Matplotlib (ISBN 9781484242452)
- 지은이로버트 요한슨(Robert Johansson)
- 옮긴이(주)크라스랩
- ISBN : 9791161753324
- 50,000원
- 2019년 08월 30일 펴냄
- 페이퍼백 | 772쪽 | 188*235mm
- 시리즈 : 데이터 과학
책 소개
요약
Python을 사용해 과학과 공학 분야에 빈번히 등장하는 연산 문제를 해결하는 방법을 설명한다. Python 과학 연산 모듈인 Scipy, 배열처리 기본 모듈인 NumPy, 데이터 처리를 위한 기본 모듈인 Pandas, 머신 러닝을 위한 Scikit-learn을 중심으로 과학 연산을 처리할 수 있는 두 가지 중요한 기법인 기호적, 수치적 처리 기법을 사용하는 데 Python을 어떻게 활용할 수 있는지 자세히 설명한다.
행렬 및 희소 행렬, 벡터, 상미분과 편미분, 적분, 인수분해, 시계열, 선형 대수, 통계 모델링, 머신 러닝, 신호처리 등 이공계의 대표적 문제들을 해결하는 데 Python을 어떻게 활용할 수 있는지 풍부한 예제를 통해 상세히 설명한다.
책 후반부는 HDF5를 포함해 데이터 처리를 위한 다양한 파일 입출력 형식을 알아보고, 코드의 실행 성능 향상을 위한 코드 최적화와 함께 모듈 설치법도 상세히 설명한다.
이 책에서 다루는 내용
■ Numpy를 사용한 벡터와 행렬 작업
■ Matplotlib를 사용한 도식화와 시각화
■ Pandas and SciPy를 사용한 데이터 분석 과제
■ statsmodels과 scikit-learn를 사용한 통계 모델링과 머신 러닝 리뷰
■ Numba와 Cython을 사용한 파이썬 코드 최적화
이 책의 구성
1장, ‘Python을 이용한 컴퓨팅 소개’에서는 과학 컴퓨팅에 대한 일반적인 원칙과 Python 계산 작업에 사용할 수 있는 주요 개발 환경을 소개한다. 즉 IPython과 대화형 Python 프롬프트, 뛰어난 Jupyter Notebook 응용과 Spyder 통합 개발 환경(Spyder IDE, Spyder Integrated Development Environment)에 초점을 맞추고 있다.
2장, ‘벡터, 행렬, 다차원 배열’에서는 NumPy 라이브러리를 소개하고 좀 더 일반적인 배열 기반 연산과 장점을 알아본다.
3장, ‘기호 연산’에서는 SymPy 라이브러리를 사용한 기호 연산에 대해 알아본다. 이 방법은 배열 기반 연산을 보완해준다.
4장, ‘도식화와 시각화’에서는 Matplotlib 라이브러리를 이용한 도식화와 시각화를 다룬다. 2장에서 4장까지는 전반적으로 책 나머지 부분의 영역별 문제에 사용될 기본 계산 도구인 수치 연산, 기호 연산, 시각화에 대해 알아본다.
5장, ‘방정식 풀이’에서는 방정식 해결로 Scipy와 SymPy 라이브러리를 사용해 수치적•기호적 방법을 모두 살펴본다.
6장, ‘최적화’에서는 방정식 해결 과제의 자연스러운 연장인 최적화를 탐구한다. 주로 Scipy 라이브러리와 cvxopt 라이브러리를 사용해 작업한다.
7장, ‘보간법’에서는 그 자체로 많은 응용을 가진 또 다른 기본적인 수학적 방법인 보간법, 고급 알고리즘과 기법에서의 주요 역할을 다룬다.
8장, ‘적분’에서는 수치적, 기호적 적분을 살펴본다. 5장부터 8장까지는 모든 종류의 컴퓨터 작업에 만연한 핵심 컴퓨터 기술을 다룬다. 8장에서 다루는 방법은 대부분 Scipy 라이브러리에서 제공된다.
9장, ‘ODE’에서는 상미분 방정식을 다룬다.
10장, ‘희소 행렬과 그래프’에서는 11장을 설명하기 위해 희소 행렬과 그래프 기법을 살펴본다.
11장, ‘PDE’에서는 개념적으로 상미분 방정식과 밀접한 관계가 있지만 10장의 주제인 희소 행렬의 도입이 필요한 PDE를 살펴본다.
12장, ‘데이터 처리 및 분석’에서는 데이터 분석과 통계 조사를 살펴본다. Pandas 라이브러리와 데이터 분석 프레임워크를 소개한다.
13장, ‘통계학’에서는 SciPy stats 패키지의 기본적인 통계 분석과 기법을 다룬다.
14장, ‘통계 모델링’에서는 statsmodels 라이브러리를 사용해 통계 모델링을 알아본다.
15장, ‘머신 러닝’에서는 scikit-learn 라이브러리를 이용한 머신 러닝을 알아보고 통계와 데이터 분석의 주제를 살펴본다.
16장, ‘베이즈 통계’는 베이즈 통계와 PyMC 라이브러리를 알아보면서 이와 관련된 장을 정리한다. 12장부터 16장까지는 통계와 데이터 분석의 광범위한 분야를 소개한다. 이는 최근 몇 년 동안 과학 Python 커뮤니티 안팎에서 급속히 발전해온 분야이기도 하다.
17장, ‘신호 처리’에서는 잠시 과학 컴퓨팅의 핵심 주제인 신호 처리로 돌아간다.
18장, ‘데이터 입출력’에서는 데이터 입출력 그리고 파일에 수치 데이터를 읽고 쓰는 몇 가지 방법을 살펴본다. 이는 대부분의 컴퓨터 작업에 필요한 기본적인 주제다.
19장, ‘코드 최적화’는 Numba와 Cython 라이브러리를 이용해 Python 코드의 속도를 높이는 두 가지 방법을 소개한다.
부록에는 이 책에서 사용한 소프트웨어 설치 방법이 수록돼 있다. 필요한 소프트웨어(대부분의 Python 라이브러리)를 설치하기 위해 Conda 패키지 매니저를 이용한다. Conda는 안정적이고 재현 가능한 컴퓨터 환경을 만들기 위한 중요한 주제로, 가상적이며 격리된 Python 환경을 만드는 데도 사용될 수 있다. 또한 Conda 패키지 매니저를 사용해 이런 환경을 설정하는 방법도 살펴본다.
상세 이미지
목차
목차
- 1장. Python을 이용한 컴퓨팅 소개
- Python을 이용한 컴퓨팅 환경
- Python
- 인터프리터
- IPython 콘솔
- 입출력 캐싱
- 자동 완성 및 객체 인트로스펙션
- 문서
- 시스템 셸과의 상호 작용
- IPython 확장
- Jupyter
- Jupyter QtConsole
- Jupyter Notebook
- Jupyter 랩
- 셀 유형
- 셀 편집하기
- 마크다운 셀
- 리치 출력 디스플레이
- nbconvert
- Spyder 통합 개발 환경
- 소스 코드 편집기
- Spyder에 있는 콘솔
- 객체 검사기
- 요약
- 추가 참고 도서 목록
- 참고 문헌
- 2장. 벡터, 행렬, 다차원 배열
- 모듈 임포트하기
- NumPy 배열 객체
- 데이터 유형
- 메모리 내 배열 데이터 순서
- 배열 만들기
- 리스트나 다른 유사-배열 객체에서 생성된 배열
- 일정한 값으로 채운 배열
- 증분 시퀀스로 채운 배열
- 로그 시퀀스로 채워진 배열
- Meshgrid 배열
- 초기화되지 않은 배열 만들기
- 다른 배열의 특성으로 배열 만들기
- 행렬 만들기
- 인덱싱 및 슬라이싱
- 1차원 배열
- 다차원 배열
- 뷰
- 팬시 인덱싱과 부울 값 인덱싱
- 재형상과 크기 변경
- 벡터화 식
- 산술 연산
- 원소별 함수
- 집계 함수
- 부울 배열과 조건부 식
- 집합 연산
- 배열 연산
- 행렬과 벡터 연산
- 요약
- 추가 참고 도서 목록
- 참고 문헌
- 3장. 기호 연산
- SymPy 임포트하기
- 기호들
- 숫자들
- 식
- 식 다루기
- 단순화
- 확장
- 인수분해 모음 및 병합
- 분리, 묶기, 제거
- 치환
- 수치 계산
- 미적분
- 도함수
- 적분
- 계열
- 극한
- 합과 곱
- 방정식
- 선형 대수학
- 요약
- 추가 참고 도서 목록
- 참고 문헌
- 4장. 도식화와 시각화
- 모듈 임포트하기
- 시작하기
- 대화형 및 비대화형 모드
- Figure
- Axes
- 도식 유형
- 선 속성
- 범례
- 텍스트 서식 및 주석
- 축 특성
- 고급 Axes 레이아웃
- 인셋
- 부도면
- Subplot2grid
- GridSpec
- 컬러 맵 도식화
- 3D 도면
- 요약
- 추가 참고 도서 목록
- 참고 문헌
- 5장. 방정식 풀이
- 모듈 임포트하기
- 선형 연립 방정식
- 정방 시스템
- 비정방 방정식
- 고윳값 문제
- 비선형 방정식
- 단변량 방정식
- 비선형 연립 방정식
- 요약
- 추가 참고 도서 목록
- 참고 문헌
- 6장. 최적화
- 모듈 임포트하기
- 최적화 문제 분류
- 일변량 최적화
- 제약 없는 다변량 최적화
- 비선형 최소 자승 문제
- 제약 조건 최적화
- 선형 프로그래밍
- 요약
- 추가 참고 도서 목록
- 참고 문헌
- 7장. 보간법
- 모듈 임포트하기
- 보간법
- 다항식
- 다항식 보간
- 스플라인 보간
- 다변량 보간법
- 요약
- 추가 참고 도서 목록
- 참고 문헌
- 8장. 적분
- 모듈 임포트하기
- 수치적 적분법
- Scipy와의 수치적 적분
- 표로 된 피적분 함수
- 다중 적분
- 기호와 임의-정밀도 적분
- 선 적분
- 적분 변환
- 요약
- 추가 참고 도서 목록
- 참고 문헌
- 9장. ODE
- 모듈 임포트하기
- ODE
- ODE의 기호적 해법
- 방향장
- 라플라스 변환을 이용한 ODE 해결
- ODE 해결을 위한 수치적인 방법
- Scipy를 이용한 ODE의 수치적 적분
- 요약
- 추가 참고 도서 목록
- 참고 문헌
- 10장. 희소 행렬과 그래프
- 모듈 임포트하기
- Scipy의 희소 행렬
- 희소 행렬 생성 함수
- 희소 선형 대수 함수
- 선형 연립 방정식
- 그래프와 네트워크
- 요약
- 추가 참고 도서 목록
- 참고 문헌
- 11장. PDE
- 모듈 임포트하기
- PDE
- FDMs
- FEM
- FEM 라이브러리 조사
- FENiCS를 이용해 PDE 해결하기
- 요약
- 추가 참고 도서 목록
- 참고 문헌
- 12장. 데이터 처리 및 분석
- 모듈 임포트하기
- Pandas 소개
- Series
- DataFrame
- 시계열
- Seaborn 그래픽 라이브러리
- 요약
- 추가 참고 도서 목록
- 참고 문헌
- 13장. 통계학
- 모듈 임포트하기
- 통계 및 확률 리뷰
- 랜덤 수
- 확률 변수 및 분포
- 가설 검정
- 비매개변수 기법
- 요약
- 추가 참고 도서 목록
- 참고 문헌
- 14장. 통계 모델링
- 모듈 임포트하기
- 통계 모델링 소개
- Patsy를 이용한 통계 모델 정의
- 선형 회귀
- 예제 데이터셋
- 이산 회귀 분석
- 로지스틱 회귀
- 푸아송 모델
- 시계열
- 요약
- 추가 참고 도서 목록
- 참고 문헌
- 15장. 머신 러닝
- 모듈 임포트하기
- 머신 러닝에 대한 간략한 리뷰
- 회귀
- 분류
- 클러스터링
- 요약
- 추가 참고 도서 목록
- 참고 문헌
- 16장. 베이즈 통계
- 모듈 임포트하기
- 베이즈 통계 소개
- 모델 정의
- 사후 분포 표본 추출
- 선형 회귀
- 요약
- 추가 참고 도서 목록
- 참고 문헌
- 17장. 신호 처리
- 모듈 임포트하기
- 스펙트럼 분석
- 푸리에 변환
- 윈도우
- 스펙트로그램
- 신호 필터
- 컨벌루션 필터
- FIR 및 IIR 필터
- 요약
- 추가 참고 도서 목록
- 참고 문헌
- 18장. 데이터 입출력
- 모듈 임포트하기
- 쉼표-구분 값
- HDF5
- h5py
- PyTables
- Pandas HDFStore
- JSON
- 직렬화
- 요약
- 추가 참고 도서 목록
- 참고 문헌
- 19장. 코드 최적화
- 모듈 임포트하기
- Numba
- Cython
- 요약
- 추가 참고 도서 목록
- 참고 문헌
- 부록. 코드 최적화
- 설치
- Miniconda와 Conda
- 완벽한 환경
- 요약
도서 오류 신고
정오표
정오표
[p. 189 # 마커 유형 아래로 4행]
ls='*',
->
ls = 'None'
또는
ls = ''
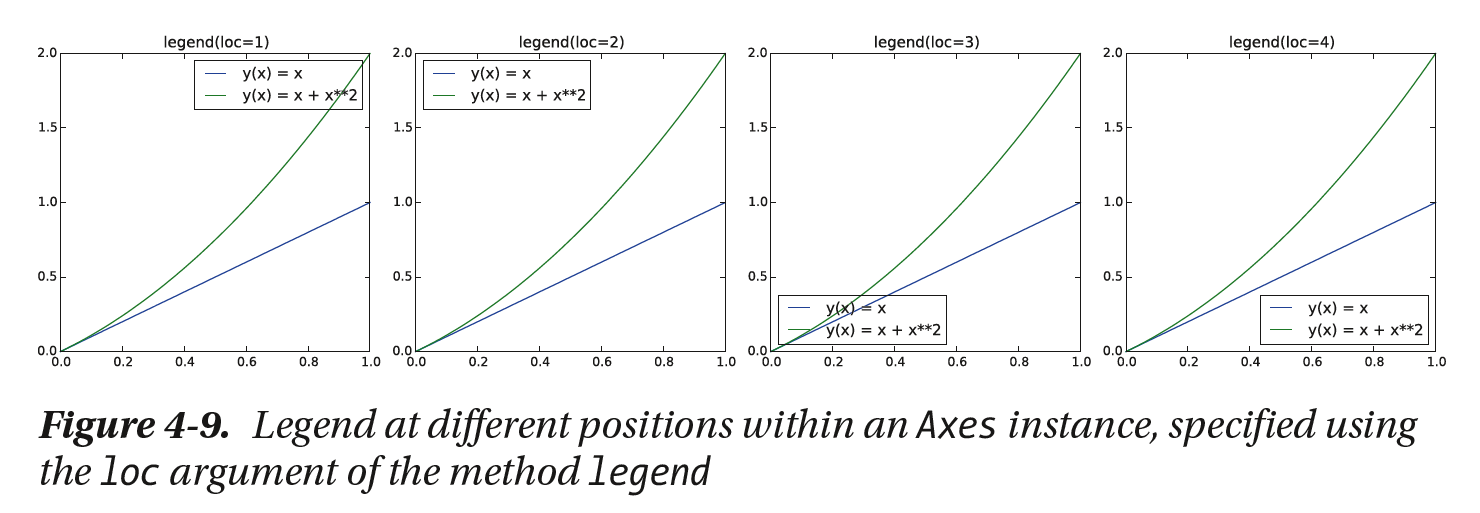
[p. 192 그림 4-9 legend 메서드의 loc 인수를 사용해 지정한 Axes 인스턴스 내의 서로 다른 위치의 범례]
[p. 421]
