


책 소개
[ 소개 ]
데이터를 길들여라!
R은 통계 소프트웨어 개발용으로 쓰이는 세계에서 가장 유명한 언어다. 고대 문명의 확산 경향을 추적하는 고고학자, 어떤 약이 안전하고 효과적인지 찾아내는 제약사 등 모두 R을 사용한다. 자산 리스크를 평가하고 시장에서의 변동률을 안정성 있게 유지하려는 보험 설계사 또한 R을 사용한다.
『빅데이터 분석 도구 R 프로그래밍』에서는 R을 사용한 소프트웨어 개발에 대해 기본적인 유형 및 데이터 구조부터 클로저, 재귀, 무기명 함수 같은 어려운 주제까지 모두 다룬다. 통계적 지식은 전혀 필요하지 않으며, 프로그래밍에 대해서도 초보자든 프로든 상관없다.
이 책에서 설명하는 내용을 그대로 따라가다 보면, 함수형 프로그래밍과 객체지향 프로그래밍, 수학적 시뮬레이션, 복잡한 데이터를 보다 단순하고 유용한 형태로 재배치하는 법까지 모두 배울 수 있을 것이다.
비행기를 설계하거나 날씨를 예측하거나, 혹은 간단히 데이터를 길들이는 등 수많은 분야에서 『빅데이터 분석 도구 R 프로그래밍』은 통계 컴퓨팅의 능력을 활용할 수 있는 진정한 가이드가 되어줄 것이다.
[ 이 책에서 다루는 내용 ]
■ 복잡한 데이터 세트와 함수를 시각화하는 예술적인 그래프 만들기
■ 병렬 R과 벡터화를 통한 좀더 효율적인 코드 작성
■ 코드 속도 및 기능 향상을 위한 R과 C/C++, 파이썬과의 인터페이스
■ 텍스트 분석, 이미지 수정 등을 위한 패키지 찾기
■ 개선된 디버깅 기술을 활용해 귀찮은 버그 찾아 고치기
[ 이 책의 대상 독자 ]
많은 사람이 R을 주로 임시변통으로 사용한다. 히스토그램을 그리거나 회귀분석을 한다든가, 통계 기능 등 다양한 용도로 사용하는 식이다. 그러나 이 책은 R로 소프트웨어를 개발하는 사람들을 위해 기획됐다. 이 책은 전문적인 소프트웨어 개발자부터 대학에서 프로그래밍 수업을 한 번쯤 들어 본 사람까지 모두를 대상으로 한다. 그 중에서도 ‘특정한 목적을 갖고 R 코드를 작성하려는 사람’이라면 꼭 읽어야 할 책이다. 하지만 어려운 통계학 지식은 그다지 필요하지 않다.
이 책은 다음과 같은 사람들에게 도움이 될 것이다.
■ 병원이나 정부 기관에서 일하면서 정기적으로 통계 보고서를 작성해야 하고 이를 자동화한 프로그램을 개발하려는 분석가
■ 새로이 혹은 기존 방식의 절차를 통합해 통계 방법론을 개발, 이를 코드화해 일반 연구 커뮤니티에서 쓰려는 학계 연구원
■ 마케팅, 소송 지원, 언론, 출판, 그 외 복잡한 데이터를 표현하는 그래픽 코드를 개발해야 하는 관련 전문가
■ 통계 분석이 포함된 프로젝트를 진행하는 소프트웨어 개발 경험이 있는 전문 프로그래머
■ 통계 컴퓨팅 수업을 듣는 학생
[ 이 책의 구성 ]
이 책은 훌륭한 R 패키지들로 가능한 수많은 유형의 통계 방법으로 가득 채운 개론서가 아니다. 프로그래밍에 대한 책으로서 기존의 R 책에서 놓친 프로그래밍 관련 주제를 담았다. 또한 기본적 R 사용에 대한 주제에 대해서도 프로그래밍적 관점으로 접근했다.
이 책에서 다루는 내용은 크게 다음과 같다.
■ 이 책 전반에 ‘확장 예제’ 부분이 등장할 것이다. 이 부분에서는 보통 특정 데이터 기반의 단일 코드 조각이 아닌 완결된, 일반 목적의 함수들을 다룬다. 실제 이런 함수들 중 일부는 매일 하는 R 업무에서 매우 유용하게 사용할 수 있다. 이런 예제들을 익히면서 R이 어떻게 구성돼 동작하는지, 이를 프로그램에 어떻게 추가해 유용하게 사용할 수 있는지도 알아본다. 많은 경우에 ‘왜 이런 방식으로 사용했을까?’ 하는 질문에 대답함으로써 여러 대안도 함께 알아본다.
■ 사용된 예제들은 프로그래머들의 감성에 와 닿는다. 예를 들어 데이터 프레임에 대한 토론에서는 R의 리스트 형식의 데이터 프레임뿐 아니라 이에 대한 프로그래밍 구현 방식에 대해서도 다룬다. R을 다른 언어와 비교하는 부분은 이미 다른 언어를 알고 있는 사람에게는 매우 유용하다.
■ 디버깅은 어떤 언어로 프로그래밍하는 경우라도 매우 중요하다. 대다수 R 책에서는 이를 강조하지 않는다. 이 책에서는 ‘확장 예제’를 통해 실제 프로그램이 어떻게 디버깅되는지 전반적인 수행 과정을 모두 보여주는 형태로 모두 디버깅 기술에 1개 장을 할애했다.
■ 오늘날은 가정에서도 멀티코어 컴퓨터를 보편적으로 사용하며, GUI 프로그래밍이 과학 응용 컴퓨팅 분야에서 조용한 혁명을 일으키고 있다. R 애플리케이션이 증가함에 따라 계산량도 매우 많아졌고, 병렬 프로세싱은 R 프로그래머 사이에서 화두로 떠올랐다. 이에 따라 기술만이 아닌 확장을 주제로 장 하나를 할애했다.
■ R의 내부 구조에 대한 지식이 어떤 도움이 되는지와 R 코드의 수행 속도 향상 기능에 대해서도 각각 한 단원씩을 할애했다.
■ R에서 C나 파이썬 등의 언어로 인터페이스하는 방법에 대해서도 다룬다. 이 장 역시 디버깅 팁을 제공하는 확장 예제를 함께 수록했다.
목차
목차
- 1장 시작하기
- 1.1 R 실행하기
- 1.1.1 인터랙티브 모드
- 1.1.2 배치 모드
- 1.2 첫 번째 R 세션
- 1.3 함수 소개
- 1.3.1 변수의 범위
- 1.3.2 기본 인수
- 1.4 중요한 R 데이터 구조 예습하기
- 1.4.1 R의 일꾼, 벡터
- 1.4.2 문자열
- 1.4.3 행렬
- 1.4.4 리스트
- 1.4.5 데이터 프레임
- 1.4.6 클래스
- 1.5 확장 예제: 시험 성적을 회귀 분석하기(1)
- 1.6 시작과 종료
- 1.7 도움말 사용하기
- 1.7.1 help() 함수
- 1.7.2 example() 함수
- 1.7.3 무엇을 찾는지 정확하게 모르는 경우
- 1.7.4 다른 주제들에 대한 도움말
- 1.7.5 배치 모드에서의 도움말
- 1.7.6 인터넷 도움말
- 1.1 R 실행하기
- 2장 벡터
- 2.1 스칼라, 벡터, 배열, 행렬
- 2.1.1 벡터에 원소 추가 또는 삭제하기
- 2.1.2 벡터의 길이 파악하기
- 2.1.3 행렬과 배열을 벡터처럼 사용하기
- 2.2 선언
- 2.3 재사용
- 2.4 일반 벡터 연산
- 2.4.1 벡터의 산술 및 논리 연산
- 2.4.2 벡터 인덱싱
- 2.4.3 연산자로 유용한 벡터 생성하기
- 2.4.4 seq()를 이용해 벡터 순서 생성하기
- 2.4.5 rep()을 이용해 숫자 반복 벡터 만들기
- 2.5 all()과 any() 사용하기
- 2.5.1 확장 예제: 1이 연달아 나오는 부분 찾기
- 2.5.2 확장 예제: 이산적 시계열값 예측하기
- 2.6 벡터화 연산
- 2.6.1 벡터 입력과 출력
- 2.6.2 벡터 입력, 행렬 출력
- 2.7 NA와 NULL값
- 2.7.1 NA 사용하기
- 2.7.2 NULL 사용하기
- 2.8 필터링
- 2.8.1 필터링된 인덱스 생성하기
- 2.8.2 subset() 함수로 필터링하기
- 2.8.3 선택 함수 which()
- 2.9 벡터화 된 조건문: ifelse() 함수
- 2.9.1 확장 예제: 연관성 측정
- 2.9.2 확장 예제: Abalone 데이터 세트 기록하기
- 2.10 벡터 동일성 테스트
- 2.11 벡터 원소의 이름
- 2.12 c() 이상의 것
- 2.1 스칼라, 벡터, 배열, 행렬
- 3장 행렬과 배열
- 3.1 행렬 만들기
- 3.2 일반 행렬 연산
- 3.2.1 행렬에서 선형대수 연산 처리
- 3.2.2 행렬 인덱싱
- 3.2.3 확장 예제: 이미지 다루기
- 3.2.4 행렬 필터링
- 3.2.5 확장 예제: 공분산 행렬 생성하기
- 3.3 행렬의 행과 열에 함수 적용하기
- 3.3.1 apply() 함수 사용하기
- 3.3.2 확장 예제: 아웃라이어 탐색
- 3.4 행렬에 행과 열 추가 및 제거하기
- 3.4.1 행렬 크기 바꾸기
- 3.4.2 확장 예제: 그래프에서 서로 거리가 가장 가까운 두 점 찾기
- 3.5 벡터/행렬을 더 정확히 구분하기
- 3.6 의도하지 않은 차원 축소 피하기
- 3.7 행렬의 행과 열에 이름 붙이기
- 3.8 고차원 배열
- 4장 리스트
- 4.1 리스트 생성하기
- 4.2 일반 리스트 연산
- 4.2.1 리스트 인덱싱
- 4.2.2 리스트에 원소를 추가하고 삭제하기
- 4.2.3 리스트의 크기 확인하기
- 4.2.4 확장 예제: 텍스트 일치 확인하기(1)
- 4.3 리스트 구성요소와 값에 접근하기
- 4.4 리스트에 함수 적용하기
- 4.4.1 lapply()와 sapply() 함수 사용하기
- 4.4.2 확장 예제: 텍스트 일치 확인하기(2)
- 4.4.3 확장 예제: 다시 Abalone 데이터 사용하기
- 4.5 재귀 리스트
- 5장 데이터 프레임
- 5.1 데이터 프레임 생성하기
- 5.1.1 데이터 프레임에 접근하기
- 5.1.2 확장 예제: 시험 성적을 회귀 분석하기(2)
- 5.2 기타 행렬 방식 연산
- 5.2.1 부분 데이터 프레임 추출하기
- 5.2.2 NA 값을 다루는 추가적 방법들
- 5.2.3 rbind()와 cbind() 및 관련 함수 사용하기
- 5.2.4 apply() 적용하기
- 5.2.5 확장 예제: 월급 연구
- 5.3 데이터 프레임 결합하기
- 5.3.1 확장 예제: 직원 데이터베이스
- 5.4 데이터 프레임에 함수 적용하기
- 5.4.1 데이터 프레임에 lapply()와 sapply() 사용하기
- 5.4.2 확장 예제: 로지스틱 회귀 모델 적용하기
- 5.4.3 확장 예제: 중국어 사투리 공부 도와주기
- 5.1 데이터 프레임 생성하기
- 6장 팩터와 테이블
- 6.1 팩터와 레벨
- 6.2 팩터에 사용되는 일반적인 함수
- 6.2.1 tapply() 함수
- 6.2.2 split() 함수
- 6.2.3 by() 함수
- 6.3 테이블 사용하기
- 6.3.1 테이블로 행렬/배열 연산하기
- 6.3.2 확장 예제: 부분 테이블 추출하기
- 6.3.3 확장 예제: 테이블에서 가장 큰 셀 찾기
- 6.4 그 밖의 팩터 및 테이블 관련 함수
- 6.4.1 aggregate() 함수
- 6.4.2 cut() 함수
- 7장 R 프로그래밍 구조
- 7.1 조건문
- 7.1.1 반복문
- 7.1.2 벡터 이외의 유형을 사용하는 반복문
- 7.1.3 if-else
- 7.2 산술 및 불리언 연산 및 값
- 7.3 인수의 기본값
- 7.4 반환값
- 7.4.1 명시적으로 return()을 호출할지 판단하기
- 7.4.2 복잡한 객체 반환하기
- 7.5 함수는 객체다
- 7.6 환경 설정 및 범위 문제
- 7.6.1 최상위 레벨 환경변수
- 7.6.2 범위 계층 구조
- 7.6.3 ls() 좀 더 살펴보기
- 7.6.4 함수는 거의 부작용이 없다
- 7.6.5 확장 예제: 호출 프레임의 내용을 보여주는 함수
- 7.7 R에는 포인터가 없다
- 7.8 위층에 쓰기
- 7.8.1 고급 할당 연산자를 이용한 지역 외 변수 사용하기
- 7.8.2 assign()을 이용해 지역 외 변수 사용하기
- 7.8.3 확장 예제: R에서의 이산 사건 시뮬레이션
- 7.8.4 광역 변수는 언제 사용해야 하나?
- 7.8.5 클로저(Closure)
- 7.9 재귀
- 7.9.1 퀵소트 구현
- 7.9.2 확장 예제: 바이너리 서치 트리
- 7.10 교체 함수
- 7.10.1 교체 함수를 사용할 때 고려해야 하는 사항
- 7.10.2 확장 예제: 자동 부기 벡터 클래스
- 7.11 함수 코드 작성용 도구
- 7.11.1 텍스트 에디터와 통합 개발 툴
- 7.11.2 edit() 함수
- 7.12 자신만의 바이너리 연산자 사용하기
- 7.13 무기명 함수
- 7.1 조건문
- 8장 R에서 수학과 시뮬레이션 하기
- 8.1 수학 함수
- 8.1.1 확장 예제: 확률 계산
- 8.1.2 누적 합과 곱
- 8.1.3 최소값과 최대값(복수 가능)
- 8.1.4 미적분
- 8.2 통계 분포를 위한 함수
- 8.3 정렬
- 8.4 벡터와 행렬의 선형 대수 연산
- 8.4.1 확장 예제: 벡터 외적
- 8.4.2 확장 예제: 마코브 체인(Markov Chain)의 고정 분포 찾기
- 8.5 집합 연산
- 8.6 R에서 시뮬레이션 프로그래밍 하기
- 8.6.1 내장 랜덤 변수 생성기
- 8.6.2 반복 수행 시에 동일한 랜덤 연속값 얻기
- 8.6.3 확장 예제: 조합 시뮬레이션
- 8.1 수학 함수
- 9장 객체 지향 프로그래밍
- 9.1 S3 클래스
- 9.1.1 S3 제네릭 함수
- 9.1.2 예제: 선형 모델 함수 lm()에서 OOP
- 9.1.3 제네릭 메소드 실행 내역 찾기
- 9.1.4 S3 클래스 작성하기
- 9.1.5 상속 사용하기
- 9.1.6 확장 예제: 위 삼각 행렬 저장 클래스
- 9.1.7 확장 예제: 다항 회귀 분석 과정
- 9.2 S4 클래스
- 9.2.1 S4 클래스 작성하기
- 9.2.2 S4 클래스에서 제네릭 함수 구현하기
- 9.3 S3 대 S4
- 9.4 객체 관리하기
- 9.4.1 ls() 함수를 사용해 객체 나열하기
- 9.4.2 rm() 함수를 사용해 특정 객체 제거하기
- 9.4.3 save() 함수를 사용해 객체들을 저장하기
- 9.4.4 “이건 뭐지?”
- 9.4.5 exists() 함수
- 9.1 S3 클래스
- 10장 입력과 출력
- 10.1 키보드와 모니터에 접근하기
- 10.1.1 scan() 함수 사용하기
- 10.1.2 readline() 함수 사용하기
- 10.1.3 화면에 출력하기
- 10.2 파일 읽고 쓰기
- 10.2.1 파일에서 데이터 프레임이나 행렬 읽어오기
- 10.2.2 텍스트 파일 읽기
- 10.2.3 커넥션 입문
- 10.2.4 확장 예제: PUMS 통계 파일
- 10.2.5 URL을 통해 원격으로 파일에 접속하기
- 10.2.6 파일에 쓰기
- 10.2.7 파일과 디렉터리 정보 얻기
- 10.2.8 확장 예제: 많은 파일의 내용의 합
- 10.3 인터넷에 접근하기
- 10.3.1 TCP/IP 개요
- 10.3.2 R의 소켓
- 10.3.3 확장 예제: 병렬처리 R 구현하기
- 10.1 키보드와 모니터에 접근하기
- 11장 문자열 처리
- 11.1 문자열 처리 함수 개요
- 11.1.1 grep()
- 11.1.2 nchar()
- 11.1.3 paste()
- 11.1.4 sprint()
- 11.1.5 substr()
- 11.1.6 strsplit()
- 11.1.7 regexpr()
- 11.1.8 gregexpr()
- 11.2 정규 표현식
- 11.2.1 확장 예제: 주어진 확장자의 파일명 테스트
- 11.2.2 확장 예제: 파일명 구성하기
- 11.3 디버깅 도구 edtdbg에서 문자열 관련 기능 사용하기
- 11.1 문자열 처리 함수 개요
- 12장 그래픽
- 12.1 그래프 만들기
- 12.1.1 R 기본 그래픽의 주요 담당자: plot() 함수
- 12.1.2 선 추가하기: abline() 함수
- 12.1.3 기존 것을 유지한 상태로 새 그래프 그리기
- 12.1.4 확장 예제: 한 화면에 두 개의 밀도 추정 그래프 나타내기
- 12.1.5 확장 예제: 다항 회귀 예제
- 12.1.6 점 추가: points() 함수
- 12.1.7 범례 추가: legend() 함수
- 12.1.8 텍스트 추가: text() 함수
- 12.1.9 위치 찾기: locator() 함수
- 12.1.10 그래프 복구
- 12.2 그래프 꾸미기
- 12.2.1 문자 크게 조절: cex 옵션
- 12.2.2 축의 범위 바꾸기: xlim과 ylim 옵션
- 12.2.3 다각형 추가. polygon() 함수
- 12.2.4 선의 곡선화: lowess()와 loess() 함수
- 12.2.5 명시적 함수 그래프화
- 12.2.6 확장 예제: 곡선의 일부를 확대하기
- 12.3 그래프를 파일에 저장하기
- 12.3.1 R 그래픽 장치
- 12.3.2 출력된 그래프 저장하기
- 12.3.3 R 그래픽 장치 닫기
- 12.4 3차원 그래프 생성하기
- 12.1 그래프 만들기
- 13장 디버깅
- 13.1 디버깅의 기본 원칙
- 13.1.1 디버깅의 기본: 확인 원칙
- 13.1.2 작은 것부터 시작하기
- 13.1.3 모듈식, 하향식 디버깅
- 13.1.4 버그 예방
- 13.2 왜 디버깅 도구를 사용할까?
- 13.3 R 디버깅 기능 사용하기
- 13.3.1 debug()와 browser() 함수를 사용한 개별 단계 살펴보기
- 13.3.2 브라우저 명령어 사용하기
- 13.3.3 중단점 설정하기
- 13.3.4 trace() 함수로 추적하기
- 13.3.5 충돌 발생 후 traceback()과 debugger() 함수를 사용해 확인하기
- 13.3.6 확장 예제: 두 가지의 전체 디버깅 과정
- 13.4 국제적인 움직임: 보다 편리한 디버깅 도구
- 13.5 시뮬레이션 코드 디버깅에서의 일관성 보장하기
- 13.6 구문 및 런타임 오류
- 13.7 R 자체에서 GDB 실행하기
- 13.1 디버깅의 기본 원칙
- 14장 성능 향상: 속도와 메모리
- 14.1 빠른 R 코드 작성하기
- 14.2 반복문에 대한 두려움
- 14.2.1 속도 향상을 위한 벡터화
- 14.2.2 확장 예제: 몬테카를로 시뮬레이션의 속도를 향상시키기
- 14.2.3 확장 예제: 멱행렬 생성하기
- 14.3 함수형 프로그래밍과 메모리 문제
- 14.3.1 벡터 할당 문제
- 14.3.2 복사 후 변경 문제
- 14.3.3 확장 예제: 메모리 복사 피하기
- 14.4 코드에서 느린 부분을 찾을 때 사용하는 Rprof()
- 14.4.1 Rprof()를 사용한 모니터링
- 14.4.2 Rprof()의 작동 원리
- 14.5 바이트 코드 컴파일
- 14.6 데이터가 메모리에 들어가지 않아요!
- 14.6.1 청킹
- 14.6.2 메모리 관리를 위한 R 패키지 사용하기
- 15장 타 언어와 R을 인터페이스하기
- 15.1 R에서 호출하는 C/C++ 함수 작성하기
- 15.1.1 R을 C/C++과 연동할 때의 선행지식
- 15.1.2 예제: 정사각 행렬에서 부분 대각행렬 추출
- 15.1.3 컴파일하고 코드 실행하기
- 15.1.4 R/C 코드 디버깅하기
- 15.1.5 확장 예제: 이산 시계열값 예측
- 15.2 파이썬에서 R 사용하기
- 15.2.1 RPy 설치하기
- 15.2.2 RPy 문법
- 15.1 R에서 호출하는 C/C++ 함수 작성하기
- 16장 병렬 R
- 16.1 상호 아웃링크 문제
- 16.2 snow 패키지 소개
- 16.2.1 snow 코드 실행하기
- 16.2.2 snow 코드 분석하기
- 16.2.3 어느 정도의 속도 향상이 가능할까
- 16.2.4 확장 예제: K-평균 클러스터링
- 16.3 C 사용하기
- 16.3.1 멀티코어 사용하기
- 16.3.2 확장 예제: OpenMP에서의 상호 아웃링크 문제
- 16.3.3 OpemMP 코드 실행하기
- 16.3.4 OpenMP 코드 분석
- 16.3.5 다른 OpenMP 프라그마
- 16.3.6 GPU 프로그래밍
- 16.4 성능에 대해 일반적으로 고려할 사항
- 16.4.1 과부하의 원인
- 16.4.2 당황스러운 병렬 어플리케이션과 그렇지 않은 어플리케이션의 차이
- 16.4.3 정적 할당 대 동적 할당
- 16.4.4 소프트웨어 연금술: 일반적인 문제를 당황스러운 병렬 문제로 바꾸기
- 16.5 병렬 R 코드 디버깅하기
- 부록 AR 설치하기
- A.1 CRAN에서 R 내려 받기
- A.2 리눅스 패키지 매니저를 사용해 설치하기
- A.3 소스 파일로 설치하기
- 부록 B 패키지 설치 및 사용
- B.1 기본 패키지
- B.2 하드 디스크에서 패키지 불러오기
- B.3 웹에서 패키지 다운로드하기
- B.3.1 자동으로 패키지 설치하기
- B.3.2 수동으로 패키지 설치하기
도서 오류 신고
정오표
정오표
1쇄
[ p39 4행 ]
개수를 새는 → 개수를 세는
[ p46 상단 코드 ]
1열 → 1행
2행 → 2열
[ p46 1.4.4절 2행, p255 그림 아래로 8행, p414 아래에서 6행 ]
C 구조 → C 구조체
[ p95 아래에서 8행 ]
1felse() → ifelse()
[ p113 첫 번째 코드 9-10행 ]
randomnoise <- - matrix(nrow="lrows," ncol="<span" style=""background-color:">ncols,runif(lrowslcols))
newimg@grey <- - matrix(nrow="lrows," ncol="<span" style=""background-color:">lcols, runif(lrowslcons))
newimg@grey[rows, cols]
<- - style=""background-color:">[rows, cols]
+ q * randomnois
[ p134 첫 번째 예제 마지막 행 ]
[3,]
50 50 → [3,]
50 48
[ p134 두 번째 예제 마지막 행 ]
[3,]
50 50 → [3,]
50 49
[ p225 두 번째 코드 아래로 3행 ]
게다가 관련 없는 변수인 최상위 레벨의 d가 사용됐을 경우 → 관련없는 최상위 레벨의 변수 d가 사용됐을 경우
[ p273 상단 예제 시작 부분 1행 누락 ]
> nlm(function(x) return(x^2-sin(x)),8)
[ p274 표 8-1 '정규 분포' 행 ]
rnomr() → rnorm()
[ p351, p357, p497 ]
sprint() → sprintf()
[ p434 14.6절 2행 ]
231-1 → 231-1
2쇄
[ p125 첫 번째 코드 아래로 1행 ]
새 행렬은 x에 재할당된다. → 새 행렬은 z에 재할당된다.
[ p127 마지막 문단 1행 ]
있자. → 있다.
[ p135 첫 번째 코드 아래로 1행 ]
dim=c(3,2,2,) → dim=c(3,2,2)
[ p135 두 번째 코드 아래로 1행 ]
test → tests
[ p163 5.2.3절 4행 ]
rbind()를 사용해 열을 추가할 때, 추가되는 열을 → rbind()를 사용해 행을 추가할 때, 추가되는 행은
[ p125 3행 ]
새 행렬은 x에 → 새 행렬은 z에
[ p127 아래에서 6행 ]
20번째 줄에 주목할 필요가 있자. → 20번째 줄에 주목할 필요가 있다.
[ p135 5행 ]
인수 dim=c(3,2,2,)에서 → 인수 dim=c(3,2,2)에서
[ p135 10행 ]
test의 → tests의
[ p163 10행 ]
rbind()를 사용해 열을 추가할 때, 추가되는 열은 → rbind()를 사용해 행을 추가할 때, 추가되는 행은
[ p122 7~8행]
이 함수는 판매량 행렬의 각 열에 적용될 것이므로 주어질 열에서 가장 특이한 값의 → 이 함수는 판매량 행렬의 각 행에 적용될 것이므로 주어질 행에서 가장 특이한 값의
[ p122 17행]
x의 각 열에 적용하게 해, → x의 각 행에 적용하게 해,
[ p41 7행(두 번째 코드)]
K -> k
[ p153 두 번째 코드 4행, 5행]

3쇄
[p.79 : 첫 행]
이 코드의 핵심은 7번째 줄이다. 여기서 우리는 1, ..., i+k-1일의 k개의 데이터로 k+1일의 데이터를 예측한다. 이때 예측 결과는 pred[1]
에 저장된다.
->
이 코드의 핵심은 7번째 줄이다. 여기서 우리는 1, ..., i+k-1일의 k개의 데이터로 k+i일의 데이터를 예측한다. 이때 예측 결과는 pred[i]
에 저장된다.
[p.95 : 코드 마지막 행]
0.3 -> 0.4
[p.95 : 3행]
이를 통해 연관치가 3/10 = 0.3임을 알 수 있다.
->
이를 통해 연관치가 4/10 = 0.4임을 알 수 있다.
[p.232 : 가운데 oddsevens 함수 정의 코드]
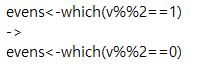
[p.157 : 마지막 행]
기반을 닦고자 한자.
->
기반을 닦고자 한다.
5쇄
[p.349 : 마지막 행]
함수를 갖이고 있고
->
함수를 가지고 있고