


테스트 주도 머신 러닝 [TDD 기법을 활용한 머신 러닝 알고리즘 구현]
- 원서명Test-Driven Machine Learning (ISBN 9781784399085)
- 지은이저스틴 보조니어(Justin Bozonier)
- 옮긴이남궁영환
- ISBN : 9788960778917
- 20,000원
- 2016년 07월 27일 펴냄 (절판)
- 페이퍼백 | 220쪽 | 188*235mm
- 시리즈 : 데이터 과학, acorn+PACKT
판매처
- 현재 이 도서는 구매할 수 없습니다.
책 소개
소스 파일은 아래 깃허브 페이지에서 내려 받으실 수 있습니다.
(https://github.com/AcornPublishing/test-driven-machine-learning)
요약
머신 러닝은 데이터에 숨겨진 공통된 특징, 즉 패턴을 찾아내고 지속적으로 개선할 수 있도록 컴퓨팅 머신을 학습시키는 과정이라고 할 수 있다. 이 책에서는 이러한 머신 러닝 알고리즘에 테스트 주도형 개발 기법을 어떻게 적용할 수 있는지 단계별로 상세하게 설명한다. 우선 테스트 주도형 개발(TDD) 기법의 기본 개념을 이해하고, 이를 다양한 머신 러닝 기술에 적용한다. 예를 들면, 분석 모델 성능의 정량적 분석, 신경망 기법, 회귀분석을 이용한 예측 분석, 로지스틱 회귀분석을 이용한 회귀분석 기법 구현 등을 다룬다. 후반부에서는 나이브 베이즈 분류분석에 대한 다양한 접근 방법에 대해서도 학습한다. 끝으로, 이 책에서 다룬 다중 회귀분석 예제와 분류분석기를 통합해 마케팅 분야에 활용 가능한 알고리즘을 어떻게 개발하는지도 알아본다.
이 책에서 다루는 내용
■ 테스트 주도형 개발(TDD) 방법 소개와 머신 러닝 개념에 TDD 적용 방법
■ 계획대로 동작하는 형태의 신경망 알고리즘 구현과 테스트
■ 분석 모델의 특이한 실행 동작 관련 테스트 케이스
■ 불확실성 속에서 최적의 결정을 이끌어내는 multi-armed bandit 알고리즘
■ 테스트 내에 구현되어 다양한 테스트 케이스 제작이 가능한 데이터 생성 방법
■ 외부 라이브러리 사용 시에도 가능한 분석 모델의 단계적 개발 방법
■ 신속한 반복 시도와 협업을 위한 분석 모델 성능의 정량적 분석
■ 일반적인 머신 러닝 알고리즘에 대한 좀 더 쉬운 접근법
■ 테스트 의도를 명확히 하기 위한 프로그램 실행동작 주도형 개발(BDD)의 원칙과 적용
이 책의 대상 독자
이 책은 자신이 구현한 알고리즘을 어떻게 개선할 것인지를 독자적으로, 또 자동화된 방식으로 테스트하고 싶어하는 머신 러닝 전문가에게 적합하다. 테스트 주도형 개발을 시작하려는 데이터 사이언티스트에게도 유용할 것이다. 다만 테스트 주도형 개발 기법의 최신 내용을 배우고자 하는 독자에게는 추천하지 않는다. 이 책은 대부분 테스트 주도형 개발에서 매우 간단하게 배울 수 있는 내용들로 구성되었기 때문이다. 폭넓은 독자층에 맞게 상대적으로 쉬운 접근법을 다룬다.
이 책의 구성
1장, ‘테스트 주도형 머신 러닝의 소개’에서는 테스트 주도형 개발(TDD)이 무엇인지, 실제로 어떻게 생겼는지, 어떻게 수행되는지에 대해 설명한다.
2장, ‘퍼셉트론(Perceptron)의 개념 기반 테스트’에서는 간단한 버전에서 시작해 퍼셉트론을 개발한다. 퍼셉트론이 비결정적(non-deterministic) 형태로 동작하는 특성을 지녔지만, 테스트가 가능하도록 알고리즘 실행동작(behavior)에 대한 정의도 작성한다.
3장, ‘Multi-armed bandit 알고리즘을 이용한 문제 해결’에서는 multi-armed bandit 문제와 여러 가지 알고리즘의 테스트, 반복 수행에 따른 성능의 변화 등을 알아본다.
4장, ‘회귀분석을 이용한 예측’에서는 statsmodels를 사용해 회귀분석을 구현하고, 주요 성능 지표에 대해 알아본다. 분석 모델 튜닝에 대해서도 학습한다.
5장, ‘로지스틱 회귀분석을 이용한 ‘흑과 백’의 판단 결정’에서는 앞 장에 이어 회귀분석에 대해 살펴보고, 여러 가지 타입으로 성능 측정을 정량화하는 방법에 대해 알아본다. 이 장에서도 회귀분석 모델을 개발하기 위해 statmodels를 사용한다.
6장, ‘나이브 베이즈’에서는 테스트 주도형 개발 기법을 이용해 간단한 개념으로부터 가우시안 나이브 베이즈(Gaussian Naive Bayes) 알고리즘을 어떻게 개발하는지 알아본다.
7장, ‘알고리즘 선택을 통한 최적화’에서는 6장에 이어 추가 사항을 계속 알아본다. 그리고 새로운 알고리즘인 랜덤 포레스트(Random Forests)를 적용해 이 결과를 향상시킬 수 있는지 살펴본다.
8장, ‘테스트 주도형 기반 scikit-learn 학습’에서는 스스로 학습하는 방법에 대해 알아본다. 여러분은 이미 이와 관련한 많은 경험이 있을 거라고 본다. 이 장에서는 scikit-learn 문서에 대해 테스트 프레임워크를 사용하는 법을 학습하고 이를 기반으로 구현해본다.
9장, ‘전체 통합 작업’에서는 여러 가지 다양한 알고리즘이 필요한 비즈니스 문제를 다룬다. 간단한 개념에서 출발해 우리가 필요한 모든 것을 개발하고, 외부 라이브러리와 우리가 구현한 코드를 통합한다. 이 모든 작업을 테스트 주도형으로 진행한다.
본문에 쓰인 컬러 이미지는 여기에서 내려 받으세요.
목차
목차
- 1장. 테스트 주도형 머신 러닝의 소개
- 테스트 주도형 개발
- TDD 사이클
- 빨간색
- 초록색
- 리팩토링
- 실행동작 주도형 개발
- 첫 번째 테스트
- 테스트 상세 분석
- 주어진 조건
- 언제
- 그러고 나면
- 테스트 상세 분석
- 머신 러닝에 TDD 적용
- 확률적 속성 문제 해결
- 개선된 분석 모델의 검증 방법
- 분류분석 개요
- 회귀분석
- 클러스터링
- 분류분석 모델의 정량적 분석
- 요약
- 2장. 퍼셉트론의 개념 기반 테스트
- 시작
- 요약
- 3장. Multi-armed bandit 알고리즘을 이용한 문제 해결
- Bandit의 소개
- 시뮬레이션 기반 테스팅
- 간단한 수준에서 시작
- 실제 환경에서 시뮬레이션
- Randomized probability matching 알고리즘
- 부스트래핑 bandit
- 현재 부스트래핑 기법의 문제점
- Multi-armed bandit 알고리즘 활용
- 요약
- 4장. 회귀분석을 이용한 예측
- 고급 회귀분석 기법 복습
- 회귀분석 관련 개념 사전 정리
- 정량화 기반 분석 모델 성능 측정
- 데이터 생성 작업 소개
- 분석 모델 관련 기본 사항 구현
- 분석 모델에 대한 교차 검증
- 데이터 생성
- 요약
- 고급 회귀분석 기법 복습
- 5장. 로지스틱 회귀분석을 이용한 ‘흑과 백’의 판단 결정
- 로지스틱 회귀분석용 데이터 생성
- 분석 모델의 정확도 측정
- 조금 더 복잡한 예제 작성
- 분석 모델에 대한 테스트 주도형 작업
- 요약
- 6장. 나이브 베이즈
- 실습을 통한 가우시안 분류분석의 이해
- 분석 모델 개발
- 요약
- 7장. 알고리즘 선택을 통한 최적화
- 분류분석기의 성능 개선
- 우리의 분류분석기 적용
- 랜덤 포레스트 알고리즘 성능 개선
- 요약
- 8장. 테스트 주도형 기반 scikit-learn 학습
- 테스트 주도형 설계
- 전체 개발 계획 수립
- 분류분석기 선택 기능 개발(분류분석기 성능 평가용 테스트 실행이 수반된)
- 알고리즘의 신중한 선택을 위한 선택 기능 개선
- 테스트가 가능한 도큐멘테이션 개발
- 의사결정 트리 알고리즘
- 요약
- 9장. 전체 통합 작업
- 상위 개념 수준에서 시작
- 실제 환경에 적용
- 이 책을 통해 얻은 것
- 요약
도서 오류 신고
정오표
정오표
[p.48]
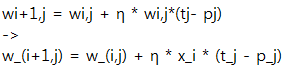
[p.49]

[p.54 : class Perceptron]

[p.56, 58]

[p.62 : 세번째 문단]
홈페지
->
홈페이지
[p.120 : 프로그램 예시]
