


빅데이터 마이닝 [하둡을 이용한 대용량 데이터 마이닝 기법]
- 원서명Mining of Massive Datasets 2nd Edition (ISBN 9781107077232)
- 지은이쥬어 레스코벡(Jure Leskovec), 아난드 라자라만(Anand Rajaraman), 제프리 데이비드 울만(Jeffrey David Ullman)
- 옮긴이박효균, 이미정
- ISBN : 9788960779532
- 40,000원
- 2017년 02월 10일 펴냄
- 페이퍼백 | 592쪽 | 188*250mm
- 시리즈 : 데이터 과학
판매처
개정판책 소개
2017년 대한민국학술원 우수학술도서 선정도서
요약
데이터 마이닝, 통계, 빅데이터 그리고 머신 러닝이라는 주제는 서로 떼어놓고 생각할 수 없는 관계다. 이 책은 데이터 마이닝 분야에서 다뤄지는 핵심 문제들을 빅데이터에 적용 가능한 알고리즘으로 구현할 수 있는 방법에 초점을 맞추고 있다. 스탠퍼드 대학의 교재답게(http://www.mmds.org/), 데이터 마이닝의 기본 원리부터 머신 러닝까지 상세히 다루며, 흥미로운 사례로 넷플릭스와 전자상거래의 추천 시스템, 검색 엔진의 기본 원리 등을 이해하기 쉽게 설명한다. 데이터 과학자가 되고 싶다면 이 책을 중심으로 다른 부교재들을 참고하며 공부하는 것을 추천한다.
이 책에서 다루는 내용
■ 대규모 데이터를 처리할 수 있는 병렬 알고리즘을 만드는 툴인 분산 파일 시스템과 맵리듀스(map-reduce)
■ 민해시(minhash)와 지역성 기반 해시(locality-sensitive hash) 알고리즘의 핵심 기술 및 유사도 검색(similarity search)
■ 매우 빨리 입력돼 즉각 처리하지 않으면 유실되는 데이터를 다루는 데 특화된 알고리즘과 데이터 스트림 처리
■ 구글의 페이지랭크(PageRank), 링크 스팸 탐지, 허브와 권위자(hubs-and-authorities) 기법을 포함하는 검색 엔진 기술
■ 연관 규칙(association rule), 시장바구니 모델(market-baskets), 선험적 알고리즘(A-Priori Algorithm)과 이를 개선한 기법들 및 빈발 항목집합(frequent-itemset) 마이닝
■ 대규모 고차원 데이터 집합을 클러스터링하는 알고리즘
■ 웹 애플리케이션과 관련된 두 가지 문제인 광고와 추천 시스템
■ 소셜 네트워크 그래프처럼 매우 큰 구조의 분석과 마이닝을 위한 알고리즘들
■ 특이 값 분해(singular value decomposition)와 잠재 의미 색인(latent semantic indexing) 및 차원 축소(dimensionality reduction)를 통해 대규모 데이터에서 중요한 속성을 도출해내는 기법들
■ 퍼셉트론(perceptron), 서포트 벡터 머신(support vector machine), 경사 하강(gradient descent) 같은 대규모 데이터에 적용 가능한 머신 러닝 알고리즘
이 책의 대상 독자
데이터베이스와 웹 기술을 선도하는 학자들이 쓴 이 책은 학생과 실무자 모두를 위한 필독서다. 다음의 과정을 익힌 독자들에게 적합한 책이다.
■ SQL 및 관련 프로그래밍 시스템을 주제로 하는 데이터베이스 시스템 입문
■ 2학년 수준의 자료구조, 알고리즘, 이산수학
■ 2학년 수준의 소프트웨어 시스템, 소프트웨어 엔지니어링, 프로그래밍 언어
목차
목차
- 1장. 데이터 마이닝
- 1.1 데이터 마이닝이란?
- 1.2 데이터 마이닝의 통계적 한계점
- 1.3 알아두면 유용한 사실들
- 1.4 이 책의 개요
- 1.5 요약
- 1.6 참고문헌
- 2장. 맵리듀스와 새로운 소프트웨어 스택
- 2.1 분산 파일 시스템
- 2.2 맵리듀스
- 2.3 맵리듀스를 사용하는 알고리즘
- 2.4 맵리듀스의 확장
- 2.5 통신 비용 모델
- 2.6 맵리듀스에 대한 복잡도 이론
- 2.7 요약
- 2.8 참고문헌
- 3장. 유사 항목 찾기
- 3.1 근접 이웃 탐색의 응용
- 3.2 문서의 슁글링
- 3.3 집합의 유사도 보존 요약
- 3.4 문서의 지역성 기반 해싱
- 3.5 거리 측정
- 3.6 지역성 기반 함수의 이론
- 3.7 기타 거리 측정법들을 위한 LSH 함수군
- 3.8 지역성 기반 해시 응용 분야
- 3.9 높은 유사도 처리 방법
- 3.10 요약
- 3.11 참고문헌
- 4장. 스트림 데이터 마이닝
- 4.1 스트림 데이터 모델
- 4.2 스트림 데이터의 표본추출
- 4.3 스트림 필터링
- 4.4 스트림에서 중복을 제거한 원소 개수 세기
- 4.5 모멘트 근사치
- 4.6 윈도 내에서의 카운트
- 4.7 감쇠 윈도
- 4.8 요약
- 4.9 참고문헌
- 5장. 링크 분석
- 5.1 페이지랭크
- 5.2 페이지랭크의 효율적인 연산
- 5.3 주제 기반 페이지랭크
- 5.4 링크 스팸
- 5.5 허브와 권위자
- 5.6 요약
- 5.7 참고문헌
- 6장. 빈발 항목집합
- 6.1 시장바구니 모델
- 6.2 시장바구니와 선험적 알고리즘
- 6.3 메인 메모리에서 더 큰 데이터 집합 처리하기
- 6.4 단계 한정 알고리즘
- 6.5 스트림에서 빈발 항목 개수 세기
- 6.6 요약
- 6.7 참고문헌
- 7장. 클러스터링
- 7.1 클러스터링 기법의 개요
- 7.2 계층적 클러스터링
- 7.3 k평균 알고리즘
- 7.4 CURE 알고리즘
- 7.5 비유클리드 공간에서의 클러스터링
- 7.6 스트림을 위한 클러스터링과 병렬 처리
- 7.7 요약
- 7.8 참고문헌
- 8장. 웹을 통한 광고
- 8.1 온라인 광고와 관련된 주제들
- 8.2 온라인 알고리즘
- 8.3 조합 문제
- 8.4 애드워즈 문제
- 8.5 애드워즈 구현
- 8.6 요약
- 8.7 참고문헌
- 9장. 추천 시스템
- 9.1 추천 시스템 모델
- 9.2 내용 기반 추천
- 9.3 협업 필터링
- 9.4 차원 축소
- 9.5 넷플릭스 챌린지
- 9.6 요약
- 9.7 참고문헌
- 10장. 소셜 네트워크 그래프 마이닝
- 10.1 소셜 네트워크 그래프
- 10.2 소셜 네트워크 그래프 클러스터링
- 10.3 커뮤니티의 직접적 발견
- 10.4 그래프 분할
- 10.5 겹치는 커뮤니티 찾기
- 10.6 유사순위
- 10.7 삼각형의 개수 세기
- 10.8 그래프의 이웃 특징
- 10.9 요약
- 10.10 참고문헌
- 11장. 차원 축소
- 11.1 고윳값과 고유벡터
- 11.2 주성분 분석
- 11.3 특이 값 분해
- 11.4 CUR 분해
- 11.5 요약
- 11.6 참고문헌
- 12장. 대규모 머신 러닝
- 12.1 머신 러닝 모델
- 12.2 퍼셉트론
- 12.3 서포트 벡터 머신
- 12.4 최근접 이웃 학습
- 12.5 학습 방식의 비교
- 12.6 요약
- 12.7 참고문헌
도서 오류 신고
정오표
정오표
[p.128 : 아래서 6행]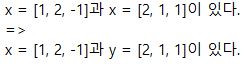
[p.302 : 아래서 5행]
단위 정육면체
->
단위 공간
; d-차원의 "cube"는 정확하게 한국어로 번역할 단어가 없기 때문에 독자의 이해를 돕기 위해 상상하기 쉬운 “정육면체” 또는 “공간”으로 번역했다. - 엮은이