


책 소개
소스 코드 파일은 여기에서 내려 받으실 수 있습니다.
https://github.com/AcornPublishing/practical-deep-learning
소개 이미지

요약
딥러닝과 머신러닝의 초보 실무자나 실무 관리자를 위한 책이다. 딥러닝과 머신러닝은 데이터가 가장 중요하며, 데이터에서 모든 것이 시작된다. 데이터를 어떻게 다듬고, 구성하고, 사용해야 하는지를 상세히 설명한다. 모델 산출도 중요하지만 그다음이 더 중요하다. 모델의 성능을 어떻게 평가해야 하는지, 각 성능치가 의미하는 바가 무엇인지, 산출된 모델을 어떤 방식으로 개선해 나가야 하는지를 명료하게 해설한다. 언어 모델이나, 상담 챗봇, 이미지 생성/합성 등 화려한 최신 모델에 대한 책은 아니다. 기본에 충실해 독자가 실무 수행 중에 채워 넣어야 할 항목들을 담백하게 설명한다.
추천의 글
견고한 개념적 기초를 제공할 뿐만 아니라 독자가 자신의 프로젝트와 솔루션을 설계하는 데 적용할 실용적인 지침을 제공한다. 현재 이 분야에서 표준으로 인정되는 모델 평가 방식을 소개하면서 이를 이용해 머신러닝 모델의 성능을 조정하고 평가하는 방법을 설명한다. 책 전반에 걸쳐 직관이 강조된다. 실용적인 지식은 직관을 기반으로 하기 때문이다.
완벽한 책은 없다. 이 책은 입문서 수준의 책일 뿐이다. 이 책의 마지막 장은 딥러닝 혁명으로의 여정을 계속하면서 다음으로 살펴볼 만한 주제가 무엇인지 제시해준다. 즐거운 탐험이 되길 바란다.
― 마이클 모저(Michael C. Mozer) 박사/ 콜로라도 대학교 볼더 캠퍼스 컴퓨터 과학과, 인지 과학 연구소 교수/ 캘리포니아 마운틴 뷰 구글 연구소 연구 과학자
이 책에서 다루는 내용
◆ k-최근접 이웃 알고리듬, 랜덤 포레스트, 서포트 벡터 머신 등의 고전적인 머신러닝 모델 사용 방법
◆ 신경망의 작동 원리와 학습 방법
◆ 컨볼루션 신경망의 사용 방법
◆ 성공적인 딥러닝 모델을 바닥부터 개발하는 방법
이 책의 대상 독자
머신러닝에 대한 배경 지식은 없지만 이 기술에 관심이 많아 여러 가지 실습을 해보고 싶은 독자를 위한 안내서다. 수학적인 내용은 최소한으로 했다. 이 책의 목표는 머신러닝의 핵심 개념을 이해하고 앞으로 이 분야에서 일할 때 도움이 될 직관을 구축하는 것이다.
컴퓨터 프로그래밍 언어 중 아무 언어나 어느 정도 익숙하다고 가정한다. 이 책에서는 학생이든 대기업이든 머신러닝 분야에서 많이 사용하는 언어인 파이썬을 사용한다. 고등학교 저학년 수학에는 익숙하지만 미적분학에는 익숙하지 않다고 가정할 것이다. 약간의 미적분학은 언급하겠지만, 자세한 내용을 몰라도 기본적인 아이디어를 이해할 수 있다. 또한 약간의 통계 지식과 기본적인 확률론은 알고 있다고 가정한다. 고등학교 졸업 후 완전히 잊어버렸더라도 괜찮다. 내용을 따라가기에 충분한 배경 지식을 본문에서 소개한다.
이 책의 구성
1장, ‘시작하기’에서는 이 책에서 실습을 수행할 때 필요한 작업 환경을 설정하는 방법을 설명한다. 또한 이후에 나오는 설명의 배경 지식으로 사용할 수 있게 벡터, 행렬, 확률, 통계를 주제로 한 절이 포함돼 있다.
2장, ‘파이썬 사용’은 파이썬을 사용할 수 있게 안내한다.
3장, ‘넘파이 사용’에서는 파이썬을 확장한 라이브러리인 넘파이에 관해 이야기한다. 이 라이브러리로 인해 파이썬이 머신러닝에 유용한 언어가 됐다. 넘파이에 익숙해지도록 이 장을 정독할 것을 권장한다.
4장, ‘데이터 작업’에서는 좋은 데이터 세트를 구축하는 방법을 배울 수 있다.
5장, ‘데이터 세트 구축’에서는 책에서 사용될 데이터 세트를 구축한다. 데이터 세트를 증강시키는 방법도 배운다.
6장, ‘고전적인 머신러닝’에서는 머신러닝 초기에 사용됐던 모델 중 일부를 다룬다. 어디를 향해 가고 있는지 이해하고자 때로는 어디에서 왔는지를 알아보는 것이 중요하다.
7장, ‘고전 모델 실습’에서는 머신러닝에 대한 초기 접근 방식의 강점과 약점을 보여준다. 산출된 결과는 이 후의 장에서 비교 목적으로 참조할 것이다.
8장, ‘신경망 소개’에서는 신경망을 자세히 알아본다. 현대의 딥러닝은 신경망을 근간으로 한다.
9장, ‘신경망 학습’에서는 신경망이 학습되는 원리를 이해하는 데 필요한 지식을 소개한다. 몇 가지 기본적인 미적분 개념이 포함돼 있지만 당황할 필요는 없다. 직관을 만들어주는 것이 목적이므로 개념 위주로 내용을 구성했고, 처음에는 표기법이 낯설게 느껴질 수도 있지만 쉽게 이해할 수 있도록 자세히 설명한다.
10장, ‘실용적인 신경망 예제’는 실제로 데이터를 다루는 느낌과 직관을 얻을 수 있게 다양한 실습으로 구성돼 있다.
11장, ’모델 평가’는 모델을 평가하는 과정을 자세히 안내한다. 머신러닝 분야의 논문, 강연, 강의에서 논의되는 결과를 이해하려면 모델을 평가하는 방법을 알아야 한다.
12장, ‘컨볼루션 신경망 소개’에서는 CNN 네트워크의 기본 빌딩 블록을 설명한다. 이 책이 초점을 맞추고 있는 딥러닝 개념은 컨볼루션 신경망(CNN, Convolutional Neural Network)이라는 아이디어를 통해 실현된다.
13장, ‘케라스와 MNIST를 활용한 CNN 분석’에서는 딥러닝 분야의 기본 데이터 세트인 MNIST 데이터 세트를 이용한 실습을 통해 CNN 작동 원리를 살펴본다.
14장, ‘CIFAR-10 데이터 세트 실습’에서는 CIFAR-10이라는 또 다른 기본 데이터 세트를 살펴본다. 이 데이터 세트는 실질적인 이미지로 구성돼 있어 CNN 모델을 실험하기에 적합하다.
15장, ‘사례 연구: 오디오 샘플 분류’에서는 사례 연구로 모든 논의를 마무리한다. 흔치 않은 새로운 데이터 세트로 시작해 이를 분류하기 위한 좋은 모델을 구축하는 과정을 따라가 본다.
16장, ‘추가 학습’에서는 간과했던 몇 가지를 지적하고 다음에 공부해야 할 것에 집중할 수 있게 머신러닝과 관련된 주변의 산더미 같은 리소스를 살펴보는 데 도움이 될 내용을 담았다.
목차
목차
- 1장. 시작하기
- 프로그램 실행 환경
- 넘파이
- 싸이킷런
- 케라스와 텐서플로
- 툴킷 설치
- 선형 대수 기초
- 벡터
- 행렬
- 행렬과 벡터의 곱
- 통계와 확률
- 서술 통계
- 확률 분포
- 통계적 검정
- 그래픽 처리 장치
- 요약
- 프로그램 실행 환경
- 2장. 파이썬 사용
- 파이썬 인터프리터
- 문장과 공백
- 변수와 기본적인 자료 구조
- 수의 표현
- 변수
- 문자열
- 리스트
- 딕셔너리
- 제어 구조
- if-elif-else문
- for 반복문
- while 반복문
- break문과 continue문
- with문
- try-except문으로 에러 처리
- 함수
- 모듈
- 요약
- 3장. 넘파이 사용
- 왜 넘파이인가?
- 배열과 리스트
- 배열과 리스트 간의 처리 속도 비교
- 기본 배열
- np.array로 배열 정의
- 0과 1로 구성된 배열 정의
- 배열 원소에 접근
- 배열 인덱싱
- 배열 슬라이싱
- 말 줄임 기호
- 연산자와 브로드캐스팅
- 배열 입력과 출력
- 난수
- 넘파이와 이미지
- 요약
- 왜 넘파이인가?
- 4장. 데이터 작업
- 클래스와 레이블
- 피처와 피처 벡터
- 피처의 유형
- 피처 선택과 차원의 저주
- 좋은 데이터 세트의 특징
- 내삽법과 외삽법
- 모분포
- 사전 클래스 확률
- 컨퓨저
- 데이터 세트의 크기
- 데이터 준비
- 피처의 범위 조정
- 누락된 피처 값
- 학습, 검증, 테스트 데이터
- 3개의 부분 데이터
- 데이터 세트의 분할
- k-Fold 교차 검증
- 데이터 검토
- 데이터 점검
- 주의할 사항
- 요약
- 5장. 데이터 세트 구축
- 아이리스 꽃 데이터
- 유방암 데이터 세트
- MNIST 숫자
- CIFAR-10
- 데이터 증강
- 학습 데이터를 증강시키는 이유
- 학습 데이터 증강법
- 아이리스 꽃 데이터 세트 증강시키기
- CIFAR-10 데이터 세트 증강시키기
- 요약
- 6장. 고전적인 머신러닝
- 최근접 센트로이드
- k-최근접 이웃
- 나이브 베이즈
- 의사결정 트리와 랜덤 포레스트
- 재귀의 개념
- 의사결정 트리 만들기
- 랜덤 포레스트
- 서포트 벡터 머신 (Support Vector Machines)
- 마진
- 서포트 벡터
- 최적화
- 커널
- 요약
- 7장. 고전 모델 실습
- 아이리스 꽃 데이터 세트 실험
- 고전 모델 테스팅
- 최근접 센트로이드 분류기의 구현
- 유방암 데이터 세트 실험
- 두 개의 초기 테스트 실행
- 랜덤 분할의 효과
- k-폴드 검증 추가
- 하이퍼파라미터 분석
- MNIST 데이터 세트 실험
- 고전 모델 테스팅
- 실행 시간 분석
- PCA 구성 요소 실험
- 데이터 세트 스크램블링
- 고전 모델 요약
- 최근접 센트로이드
- k-최근접 이웃
- 나이브 베이즈
- 의사결정 트리
- 랜덤 포레스트
- 서포트 벡터 머신(SVM)
- 고전 모델의 사용
- 데이터 세트가 소규모인 경우
- 컴퓨팅 자원의 제약이 심한 경우
- 판정 결과를 설명할 수 있는 모델이 필요한 경우
- 벡터 입력 작업
- 요약
- 아이리스 꽃 데이터 세트 실험
- 8장. 신경망 소개
- 신경망의 구조
- 뉴런
- 활성화 함수
- 네트워크의 구조
- 출력 계층
- 가중치와 편향 표현법
- 간단한 신경망의 구현
- 데이터 세트 구축
- 신경망의 구현
- 신경망 학습과 테스팅
- 요약
- 신경망의 구조
- 9장. 신경망 학습
- 개요
- 경사 하강법
- 최솟값 찾기
- 가중치 갱신
- 확률적 경사 하강법
- 배치와 미니배치
- 콘벡스 함수와 비콘벡스 함수
- 학습 종료
- 학습률 갱신
- 모멘텀
- 역전파
- 역전파, 첫 번째 설명
- 역전파, 두 번째 설명
- 손실 함수
- 절대 손실과 평균 제곱 오차 손실
- 교차 엔트로피 손실
- 가중치 초기화
- 과적합과 정규화
- 과적합의 이해
- 정규화의 이해
- L2 정규화
- 드롭아웃
- 요약
- 10장. 실용적인 신경망 예제
- 데이터 세트
- sklearn의 MLPClassifier 클래스
- 네트워크 구조와 활성화 함수
- 소스코드
- 실행 결과
- 배치 크기
- 기본 학습률
- 학습 데이터 세트의 크기
- L2 정규화
- 모멘텀
- 가중치 초기화
- 피처 간의 순서
- 요약
- 11장. 모델 평가
- 정의와 가정
- 정확도만으로 충분하지 않은 이유
- 2 × 2 혼동 행렬
- 2 × 2 혼동 행렬에서 파생된 메트릭
- 2 × 2 행렬에서 메트릭 도출
- 메트릭으로 모델 해석
- 고급 메트릭
- 정보도와 표식도
- F1 점수
- 코헨 카파 계수
- 매튜 상관 계수
- 메트릭 구현
- 수신자 조작 특성(ROC) 곡선
- 모델 수집
- 그래프로 메트릭 출력
- ROC 곡선 해석
- ROC 분석을 통한 모델 비교
- ROC 곡선 그리기
- 정밀도-재현율 곡선
- 다중 클래스 다루기
- 혼동 행렬의 확장
- 가중치를 고려한 정확도 계산
- 다중 클래스 매튜 상관 계수
- 요약
- 12장. 컨볼루션 신경망 소개
- 컨볼루션 신경망을 사용하는 이유
- 컨볼루션
- 커널을 이용한 스캐닝
- 이미지 처리에 사용하는 컨볼루션
- 컨볼루션 신경망의 해부학
- 다양한 유형의 계층
- CNN을 통한 데이터 처리 과정
- 컨볼루션 계층
- 컨볼루션 계층의 작동 방식
- 컨볼루션 계층의 사용
- 다중 컨볼루션 계층
- 컨볼루션 계층 초기화
- 풀링 계층
- 완전 연결 계층
- 완전 컨볼루션 계층
- 단계별 분석
- 요약
- 13장. 케라스와 MNIST를 활용한 CNN 분석
- 케라스로 CNN 구축
- MNIST 데이터 로드
- 모델 구축
- 모델 학습과 평가
- 오차 플로팅
- 기본 실험
- 아키텍처 실험
- 학습 세트 크기, 미니배치, 에폭
- 옵티마이저
- 완전 컨볼루션 네트워크
- 모델의 구축과 학습
- 테스트 이미지 만들기
- 모델 테스트
- 스크램블된 MNIST 숫자
- 요약
- 케라스로 CNN 구축
- 14장. CIFAR-10 데이터 세트 실습
- CIFAR-10 복습
- 전체 CIFAR-10 데이터 세트를 이용한 실습
- 모델 구축
- 모델 분석
- 동물과 교통수단 구분
- 이진 클래스와 다중 클래스
- 전이학습
- 모델 미세 조정
- 데이터 세트 구축
- 미세 조정을 위한 모델 수정
- 모델 테스트
- 요약
- 15장. 사례 연구: 오디오 샘플 분류
- 데이터 세트 구축
- 데이터 세트 증강
- 데이터 전처리
- 오디오 피처 분류
- 클래식 모델 사용
- 전통적인 신경망 사용
- 컨볼루션 신경망 사용
- 스펙트로그램
- 스펙트로그램 분류
- 초기화, 정규화, 배치 정규화
- 혼동 행렬 조사
- 앙상블
- 요약
- 데이터 세트 구축
- 16장. 추가 학습
- CNN 추가 연구
- 강화학습과 비지도학습
- 생성적 적대 신경망(GAN) 모델
- 순환 신경망
- 온라인 리소스
- 학술대회
- 서적
- 맺음말, So Long and Thanks for All the Fish
도서 오류 신고
정오표
정오표
[p.42 : 두 번째 수식]
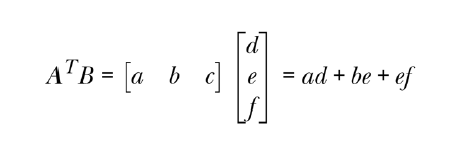
->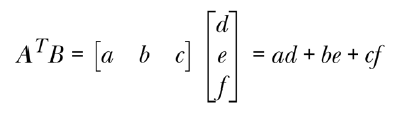
[p.77 : 4행]
https://docs.python.org/3/py-modindex.htm
->
https://docs.python.org/3/py-modindex.html
[p.168 : 아래에서 6행]
http://archive.ics.uci.edu/ml/machine-learning-databases/iris/
->
https://archive.ics.uci.edu/dataset/53/iris
[p.171 : 아래에서 2행]
https://archive.ics.uci.edu/ml/datasets/Breast+Cancer+Wisconsin+(Diagnostic)/
->
https://archive.ics.uci.edu/dataset/15/breast+cancer+wisconsin+original
[p.671 : 아래에서 10행]
www.youtube.com
->
https://www.youtube.com